Dear support team,. Is it possible to block or redirect Proxy IPs / Anonymous IPs? I cannot find the option in your plugin. Please advise. Thanks.
from Google Alert - anonymous http://ift.tt/2kBnz4r
via IFTTT
Saturday, February 4, 2017
dotnet/roslyn
wizicer changed the title from switch statement producing NullReferenceException when anonymous object were using in closure without assigning to ...
from Google Alert - anonymous http://ift.tt/2l5YwHk
via IFTTT
from Google Alert - anonymous http://ift.tt/2l5YwHk
via IFTTT
Goddesses Anonymous
Showing 1-8 of 8 results for “Goddesses Anonymous”. Sorted by date added, Popularity, Relevance, Release date, Title, Author. Filters. Filter search ...
from Google Alert - anonymous http://ift.tt/2jMWhIV
via IFTTT
from Google Alert - anonymous http://ift.tt/2jMWhIV
via IFTTT
Anonymous Couple in Sauna
Anonymous Couple in Sauna. Anonymous Couple in Sauna · Fit Young Man · Parks / Outdoor · Frangipani Flowers and Spa Stones · Nature ...
from Google Alert - anonymous http://ift.tt/2l9OPDM
via IFTTT
from Google Alert - anonymous http://ift.tt/2l9OPDM
via IFTTT
Bind, Call, Apply, Arrow, Direct, Anonymous
anonymous 2. obj.execute(function(){ obj.test(1) }), ready. bind. obj.test.bind(obj, 1)(), ready. apply. obj.test.apply(obj, [1]), ready. call. obj.test.call(obj, ...
from Google Alert - anonymous http://ift.tt/2kdP82Q
via IFTTT
from Google Alert - anonymous http://ift.tt/2kdP82Q
via IFTTT
NH Food Bank receives $1M anonymous donation
MANCHESTER — The New Hampshire Food Bank, a program of Catholic Charities New Hampshire, recently received an anonymous $1 million ...
from Google Alert - anonymous http://ift.tt/2jJzuxB
via IFTTT
from Google Alert - anonymous http://ift.tt/2jJzuxB
via IFTTT
Milky Way with Airglow Australis

Captured last April after sunset on a Chilean autumn night an exceptionally intense airglow flooded this scene. The panoramic skyscape is also filled with stars, clusters, and nebulae along the southern Milky Way including the Large and Small Magellanic clouds. Originating at an altitude similar to aurorae, the luminous airglow is due to chemiluminescence, the production of light through chemical excitation. Commonly recorded with a greenish tinge by sensitive digital cameras, both red and green airglow emission here is predominately from atmospheric oxygen atoms at extremely low densities and has often been present in southern hemisphere nights during the last few years. Like the Milky Way on that dark night the strong airglow was visible to the eye, but seen without color. Mars, Saturn, and bright star Antares in Scorpius form the celestial triangle anchoring the scene on the left. The road leads toward the 2,600 meter high mountain Cerro Paranal and the European Southern Observatory's Very Large Telescopes. via NASA http://ift.tt/2jKOpmn
Friday, February 3, 2017
Anonymous letter writer spreads joy, love to strangers
The Texas woman started the "spreadjoy24/7" movement by leaving anonymous letters of encouragement in the Bedford, Hurst and Grapevine areas.
from Google Alert - anonymous http://ift.tt/2l7nv9e
via IFTTT
from Google Alert - anonymous http://ift.tt/2l7nv9e
via IFTTT
Anonymous Gamer
The following update will apply to all GameBattles Variant Ladder matches from 4:30 PM EST and Tournaments starting after 6:00 PM EST 1/31:.
from Google Alert - anonymous http://ift.tt/2kCbgV6
via IFTTT
from Google Alert - anonymous http://ift.tt/2kCbgV6
via IFTTT
An Anonymous Group Just Took Down a Fifth of the Dark Web
A group affiliating itself with Anonymous had compromised servers at Freedom Hosting II, a popular service for hosting websites accessible only ...
from Google Alert - anonymous http://ift.tt/2l6Vrmj
via IFTTT
from Google Alert - anonymous http://ift.tt/2l6Vrmj
via IFTTT
Food Bank gets anonymous $1M donation
MANCHESTER, N.H. (AP) — The New Hampshire Food Bank has received an anonymous $1 million donation, most of it meant for its 430 partner ...
from Google Alert - anonymous http://ift.tt/2kynKxL
via IFTTT
from Google Alert - anonymous http://ift.tt/2kynKxL
via IFTTT
Dobrado O Arrogante (Anonymous)
Dobrado O Arrogante (Anonymous) ... Composer, Anonymous. Key, B-flat minor. Year/Date of CompositionY/D of Comp. Copy 1914. First Publication.
from Google Alert - anonymous http://ift.tt/2l5tUCD
via IFTTT
from Google Alert - anonymous http://ift.tt/2l5tUCD
via IFTTT
ISS Daily Summary Report – 2/02/2017
Exposed Facility Unit (EFU) Adapter Transfer: Ground Controllers maneuvered the Japanese Experiment Module (JEM) Remote Manipulator System (JEMRMS) and extracted the Small Fine Arm (SFA) from the SFA Storage Equipment (SSE). Overnight tonight the ground controllers will maneuver the SFA to grasp the EFU Adapter from the EFU-5 location. Once the EFU Adapter has been removed, it will be transferred and installed on the JEM Airlock (JEMAL) Slide Table. These activity is part of a series of events prior to the deployment of the High Definition Television Camera –Exposed Facility 2 (HDTV-EF2) experiment. HDTV-EF2 is a high-definition television camera system, which is used for earth observation from the ISS. Body Measures: Today the Body Measures subject performed the Flight Day 80 (FD80) session. The crew, with assistance from a trained operator conducted a Body Measures data collection session. The crew configured still cameras and video, then collected the Neutral Body Posture video and stow the equipment. NASA is collecting in-flight anthropometric data (body measurements) to assess the impact of physical body shape and size changes on suit sizing. Still and video imagery is captured and a tape measure is used to measure segmental length, height, depth, and circumference data for all body segments (chest, waist, hip, arms, legs, etc.) from astronauts before, during and after their flight missions. Bigelow Expandable Activity Module (BEAM) Modal Test: The crew ingressed BEAM and temporarily installed the Internal Wireless Instrumentation System (IWIS) Remote Sensing Unit (RSU) in Node 3 and the Triaxial Accelerometer (TAA) in BEAM. Following the instrument installation, the crew performed a modal test by imparting loads onto BEAM and measuring the acceleration throughout the module. Expandable habitats, occasionally described as inflatable habitats, greatly decrease the amount of transport volume for future space missions. These “expandables” weigh less and take up less room on a rocket while allowing additional space for living and working. They also provide protection from solar and cosmic radiation, space debris, and other contaminants. Crews traveling to the moon, Mars, asteroids, or other destinations could potentially use them as habitable structures. BEAM is an experimental expandable capsule attached to the Node 3 aft Common Berthing Mechanism (CBM) port. The BEAM investigation will run approximately 2 years. BEAM is not an occupied module, and not used for stowage. During this time, BEAM is constantly monitored for temperature, pressure, and radiation. Periodically, four times per year, the ISS crew enters the module to collect data and check on its structural condition. Following the BEAM investigation, the module will be released from the ISS and burn up on reentry into the atmosphere. SkinSuit: The SkinSuit subject configured the height measurement location, then with operator assistance conducted a height measurement and answered a questionnaire. At the end of the day, the operator took additional measurements prior to the subject doffing the suit. The Skinsuit is a tailor-made overall with a bi-directional weave specially designed to counteract the lack of gravity by squeezing the body from the shoulders, to the feet, with a similar force to that felt on Earth. The subjects of the investigation perform an evaluation of the efficacy of Skinsuit in reducing/preventing low back pain and preventing spine elongation; measure the gravitational load provided by Skinsuit on the ISS crewmember; evaluate operational considerations, in particular hygiene/microbiology, comfort, thermoregulation, donning/doffing, impingement and range of motion to prepare for Long Duration Missions; and evaluate the effect of wearing Skinsuit while exercising. Electromagnetic Levitation (EML) Sample Coupling Electronic (SCE) Installation: The crew performed an installation of the SCE into the Experiment Module (EXM) of the EML. The SCE will measure electrical resistivity of samples inside the EML. After demating cables and hoses the EXM will be partially removed from the European Drawer Rack (EDR) to allow for the SCE installation. The EXM will be reinstalled and cables and hoses reconnected. EML is a facility composed of 4 inserts installed into EDR on-orbit representing a facility for Electromagnetic Levitation of samples. The experiment samples are installed in a dedicated Sample Chamber that is attached to EML and will be replaced by new Sample Chambers for new experiment batches. Synchronized Position Hold, Engage, Reorient, Experimental Satellites (SPHERES) Halo: The crew conducted the first of two days of initial checkout and runs in support of the SPHERES Halo investigation. Sponsored by Defense Advanced Research Projects Agency (DARPA), SPHERES Halo utilizes the SPHERES facility (satellites) and is designed to mature adaptive Guidance, Navigation and Control (GNC) technology in support of on-orbit, robotic satellite assembly and servicing in a risk-tolerant, dynamically authentic environment. The Halo has six Halo ports and is able to support up to six peripherals, including docking ports, cameras, and other sensors and actuators. These peripherals can be added and removed from the Halo by the astronaut as necessary for each test. Today’s Planned Activities All activities were completed unless otherwise noted. Lighting Effects Sleep Log Entry – Subject KORREKTSIYA. Collection of Blood Samples KORREKTSIYA. Closeout Ops KORREKTSIYA. Venous blood sample processing using Plasma-03 centrifuge Insertion of Russian experiments blood samples into MELFI KORREKTSIYA. Handover to USOS for MELFI Insertion SPHERES Battery Swap JEM Airlock Depressurization Dose Tracker Data Entry Subject KORREKTSIYA. Logging Liquid and Food (Medicine) Intake ISS HAM Service Module Pass Cable removal for EML SCE installation СОЖ maintenance Acoustic Dosimeter Operations – Setup Dosimeter for Static Measurement CARDIOVECTOR. Experiment Ops. Body Measures Equipment Gather Body Measures Experiment Operations – Subject RELAKSATSIYAHardware Setup. VEG-03 Plant Photo SPHERES Battery Swap Body Measures Experiment Operations – Operator Multi Omics Item Gathering JEM Airlock Vent RELAKSATSIYA Parameter Settings Adjustment. JEM Airlock Vent Confirmation SkinSuit H/W Retrieval and Height Measurement Setup RELAKSATSIYA Observation SkinSuit Height Measurement & Questionnaire SkinSuit Height Measurement Operator Remove Items in Front of N3A for Hatch Access RELAKSATSIYA Closeout Ops and Hardware Removal. ARED Platform Fold Photo/TV N3/BEAM Camcorder Setup SPHERES Battery Swap BEAM Ingress Dose Tracker Data Entry Subject Reminder Multi Omics FOS intake BRI Deactivation and Cleaning. Cable reconfiguration between SM panels 228 and 229А SPHERES Crew Conference TAA Install […]
from ISS On-Orbit Status Report http://ift.tt/2jL99Kx
via IFTTT
from ISS On-Orbit Status Report http://ift.tt/2jL99Kx
via IFTTT
Radio Stations Hacked to Play "F**k Donald Trump" on Repeat Across the Country
It’s just two weeks into the Trump presidency, but his decisions have caused utter chaos around the country. One such order signed by the president was banning both refugees and visa holders from seven Muslim-majority countries (Iraq, Iran, Libya, Yemen, Somalia, Syria, and Sudan) from entering the United States, resulting in unexpectedly arrest of some travelers at airports. Now, it seems


from The Hacker News http://ift.tt/2jEAWBc
via IFTTT
from The Hacker News http://ift.tt/2jEAWBc
via IFTTT
I have a new follower on Twitter
Ash Maurya
Author of #RunningLean and Creator of #LeanCanvas. My new book: #ScalingLean - https://t.co/UvYpBnJsIA
Austin, TX
https://t.co/dFcdquFcS0
Following: 11501 - Followers: 40665
February 03, 2017 at 01:07AM via Twitter http://twitter.com/ashmaurya
Two Arrested for Hacking Washington CCTV Cameras Before Trump Inauguration
Two suspected hackers have reportedly been arrested in London on suspicion of hacking 70 percent of the CCTV cameras in Washington with ransomware ahead of President Donald Trump's inauguration last month. The arrest took place on 20th January by the officers from the National Crime Agency (NCA) of UK after it received a request from United States authorities, but it has not been disclosed until

from The Hacker News http://ift.tt/2k23G2X
via IFTTT
from The Hacker News http://ift.tt/2k23G2X
via IFTTT
NGC 1316: After Galaxies Collide

An example of violence on a cosmic scale, enormous elliptical galaxy NGC 1316 lies about 75 million light-years away toward Fornax, the southern constellation of the Furnace. Investigating the startling sight, astronomers suspect the giant galaxy of colliding with smaller neighbor NGC 1317 seen just above, causing far flung loops and shells of stars. Light from their close encounter would have reached Earth some 100 million years ago. In the deep, sharp image, the central regions of NGC 1316 and NGC 1317 appear separated by over 100,000 light-years. Complex dust lanes visible within also indicate that NGC 1316 is itself the result of a merger of galaxies in the distant past. Found on the outskirts of the Fornax galaxy cluster, NGC 1316 is known as Fornax A. One of the visually brightest of the Fornax cluster galaxies it is one of the strongest and largest radio sources with radio emission extending well beyond this telescopic field-of-view, over several degrees on the sky. via NASA http://ift.tt/2jAxVC0
Thursday, February 2, 2017
I have a new follower on Twitter
FrankNoack
Wordpress Produkte: https://t.co/8nCOCfzFB5
Hamburg Germany
https://t.co/tsHNC0MfHd
Following: 7944 - Followers: 16479
February 02, 2017 at 11:02PM via Twitter http://twitter.com/Knarfkcaon
Procedural Content Generation via Machine Learning (PCGML). (arXiv:1702.00539v1 [cs.AI])
This survey explores Procedural Content Generation via Machine Learning (PCGML), defined as the generation of game content using machine learning models trained on existing content. As the importance of PCG for game development increases, researchers explore new avenues for generating high-quality content with or without human involvement; this paper addresses the relatively new paradigm of using machine learning (in contrast with search-based, solver-based, and constructive methods). We focus on what is most often considered functional game content such as platformer levels, game maps, interactive fiction stories, and cards in collectible card games, as opposed to cosmetic content such as sprites and sound effects. In addition to using PCG for autonomous generation, co-creativity, mixed-initiative design, and compression, PCGML is suited for repair, critique, and content analysis because of its focus on modeling existing content. We discuss various data sources and representations that affect the resulting generated content. Multiple PCGML methods are covered, including neural networks, long short-term memory (LSTM) networks, autoencoders, and deep convolutional networks; Markov models, $n$-grams, and multi-dimensional Markov chains; clustering; and matrix factorization. Finally, we discuss open problems in the application of PCGML, including learning from small datasets, lack of training data, multi-layered learning, style-transfer, parameter tuning, and PCG as a game mechanic.
from cs.AI updates on arXiv.org http://ift.tt/2l0Cu5w
via IFTTT
Multilingual and Cross-lingual Timeline Extraction. (arXiv:1702.00700v1 [cs.CL])
In this paper we present an approach to extract ordered timelines of events, their participants, locations and times from a set of multilingual and cross-lingual data sources. Based on the assumption that event-related information can be recovered from different documents written in different languages, we extend the Cross-document Event Ordering task presented at SemEval 2015 by specifying two new tasks for, respectively, Multilingual and Cross-lingual Timeline Extraction. We then develop three deterministic algorithms for timeline extraction based on two main ideas. First, we address implicit temporal relations at document level since explicit time-anchors are too scarce to build a wide coverage timeline extraction system. Second, we leverage several multilingual resources to obtain a single, inter-operable, semantic representation of events across documents and across languages. The result is a highly competitive system that strongly outperforms the current state-of-the-art. Nonetheless, further analysis of the results reveals that linking the event mentions with their target entities and time-anchors remains a difficult challenge. The systems, resources and scorers are freely available to facilitate its use and guarantee the reproducibility of results.
from cs.AI updates on arXiv.org http://ift.tt/2kyskeD
via IFTTT
Two forms of minimality in ASPIC+. (arXiv:1702.00780v1 [cs.AI])
Many systems of structured argumentation explicitly require that the facts and rules that make up the argument for a conclusion be the minimal set required to derive the conclusion. ASPIC+ does not place such a requirement on arguments, instead requiring that every rule and fact that are part of an argument be used in its construction. Thus ASPIC+ arguments are minimal in the sense that removing any element of the argument would lead to a structure that is not an argument. In this brief note we discuss these two types of minimality and show how the first kind of minimality can, if desired, be recovered in ASPIC+.
from cs.AI updates on arXiv.org http://ift.tt/2kyi06o
via IFTTT
A Simplified and Improved Free-Variable Framework for Hilbert's epsilon as an Operator of Indefinite Committed Choice. (arXiv:1104.2444v9 [cs.AI] UPDATED)
Free variables occur frequently in mathematics and computer science with ad hoc and altering semantics. We present the most recent version of our free-variable framework for two-valued logics with properly improved functionality, but only two kinds of free variables left (instead of three): implicitly universally and implicitly existentially quantified ones, now simply called "free atoms" and "free variables", respectively. The quantificational expressiveness and the problem-solving facilities of our framework exceed standard first-order and even higher-order modal logics, and directly support Fermat's descente infinie. With the improved version of our framework, we can now model also Henkin quantification, neither using quantifiers (binders) nor raising (Skolemization). We propose a new semantics for Hilbert's epsilon as a choice operator with the following features: We avoid overspecification (such as right-uniqueness), but admit indefinite choice, committed choice, and classical logics. Moreover, our semantics for the epsilon supports reductive proof search optimally.
from cs.AI updates on arXiv.org http://ift.tt/12jZYm9
via IFTTT
Exploration and Exploitation of Victorian Science in Darwin's Reading Notebooks. (arXiv:1509.07175v5 [cs.CL] UPDATED)
Search in an environment with an uncertain distribution of resources involves a trade-off between exploitation of past discoveries and further exploration. This extends to information foraging, where a knowledge-seeker shifts between reading in depth and studying new domains. To study this decision-making process, we examine the reading choices made by one of the most celebrated scientists of the modern era: Charles Darwin. From the full-text of books listed in his chronologically-organized reading journals, we generate topic models to quantify his local (text-to-text) and global (text-to-past) reading decisions using Kullback-Liebler Divergence, a cognitively-validated, information-theoretic measure of relative surprise. Rather than a pattern of surprise-minimization, corresponding to a pure exploitation strategy, Darwin's behavior shifts from early exploitation to later exploration, seeking unusually high levels of cognitive surprise relative to previous eras. These shifts, detected by an unsupervised Bayesian model, correlate with major intellectual epochs of his career as identified both by qualitative scholarship and Darwin's own self-commentary. Our methods allow us to compare his consumption of texts with their publication order. We find Darwin's consumption more exploratory than the culture's production, suggesting that underneath gradual societal changes are the explorations of individual synthesis and discovery. Our quantitative methods advance the study of cognitive search through a framework for testing interactions between individual and collective behavior and between short- and long-term consumption choices. This novel application of topic modeling to characterize individual reading complements widespread studies of collective scientific behavior.
from cs.AI updates on arXiv.org http://ift.tt/1FxghEk
via IFTTT
Bootstrap Model Aggregation for Distributed Statistical Learning. (arXiv:1607.01036v2 [stat.ML] UPDATED)
In distributed, or privacy-preserving learning, we are often given a set of probabilistic models estimated from different local repositories, and asked to combine them into a single model that gives efficient statistical estimation. A simple method is to linearly average the parameters of the local models, which, however, tends to be degenerate or not applicable on non-convex models, or models with different parameter dimensions. One more practical strategy is to generate bootstrap samples from the local models, and then learn a joint model based on the combined bootstrap set. Unfortunately, the bootstrap procedure introduces additional noise and can significantly deteriorate the performance. In this work, we propose two variance reduction methods to correct the bootstrap noise, including a weighted M-estimator that is both statistically efficient and practically powerful. Both theoretical and empirical analysis is provided to demonstrate our methods.
from cs.AI updates on arXiv.org http://ift.tt/29ljlaZ
via IFTTT
A correlation coefficient of belief functions. (arXiv:1612.05497v2 [cs.AI] UPDATED)
How to manage conflict is still an open issue in Dempster-Shafer evidence theory. The correlation coefficient can be used to measure the similarity of evidence in Dempster-Shafer evidence theory. However, existing correlation coefficients of belief functions have some shortcomings. In this paper, a new correlation coefficient is proposed with many desirable properties. One of its applications is to measure the conflict degree among belief functions. Some numerical examples and comparisons demonstrate the effectiveness of the correlation coefficient.
from cs.AI updates on arXiv.org http://ift.tt/2h1gZTV
via IFTTT
Jointly Extracting Relations with Class Ties via Effective Deep Ranking. (arXiv:1612.07602v2 [cs.AI] UPDATED)
Connections between relations in relation extraction, which we call class ties, are common. In distantly supervised scenario, one entity tuple may have multiple relation facts. Exploiting class ties between relations of one entity tuple will be promising for distantly supervised relation extraction. However, previous models are not effective or ignore to model this property. In this work, to effectively leverage class ties, we propose to make joint relation extraction with a unified model that integrates convolutional neural network with a general pairwise ranking framework, in which two novel ranking loss functions are introduced. Additionally, an effective method is presented to relieve the impact of NR (not relation) for model training, which significantly boosts our model performance. Experiments on a widely used dataset show that leveraging class ties will enhance extraction and demonstrate that our model is effective to learn class ties. Our model outperforms baselines significantly, achieving state-of-the-art performance.
from cs.AI updates on arXiv.org http://ift.tt/2i7dI2c
via IFTTT
Pose-Selective Max Pooling for Measuring Similarity. (arXiv:1609.07042v4 [cs.CV] CROSS LISTED)
In this paper, we deal with two challenges for measuring the similarity of the subject identities in practical video-based face recognition - the variation of the head pose in uncontrolled environments and the computational expense of processing videos. Since the frame-wise feature mean is unable to characterize the pose diversity among frames, we define and preserve the overall pose diversity and closeness in a video. Then, identity will be the only source of variation across videos since the pose varies even within a single video. Instead of simply using all the frames, we select those faces whose pose point is closest to the centroid of the K-means cluster containing that pose point. Then, we represent a video as a bag of frame-wise deep face features while the number of features has been reduced from hundreds to K. Since the video representation can well represent the identity, now we measure the subject similarity between two videos as the max correlation among all possible pairs in the two bags of features. On the official 5,000 video-pairs of the YouTube Face dataset for face verification, our algorithm achieves a comparable performance with VGG-face that averages over deep features of all frames. Other vision tasks can also benefit from the generic idea of employing geometric cues to improve the descriptiveness of deep features.
from cs.AI updates on arXiv.org http://ift.tt/2cVF35F
via IFTTT
Overeaters Anonymous to hold local workshop
Anyone recovering from a food addiction is welcome to attend an Overeaters Anonymous workshop scheduled for Saturday, Feb. 11, from 9 a.m. to 5 ...
from Google Alert - anonymous http://ift.tt/2k1r4Oc
via IFTTT
from Google Alert - anonymous http://ift.tt/2k1r4Oc
via IFTTT
[FD] HP Printers Wi-Fi Direct Improper Access Control
HP Printers Wi-Fi Direct Improper Access Control
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
[FD] [FOXMOLE SA 2016-07-05] ZoneMinder - Multiple Issues
-----BEGIN PGP SIGNED MESSAGE-
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
Re: [FD] Multiple vulnerabilities found in the Dlink DWR-932B (backdoor, backdoor accounts, weak WPS, RCE ...)
Hello, Following the advisory posted to FD and Buqtraq about the Dlink DWR-932B router, the complete version on analyzing the security on the corrected firmware for Dlink 932B LTE routers is posted here: http://ift.tt/2ks4OAs Please find a text-only version below sent to security mailing lists. === text-version of the advisory === An update on this post: MITRE has provided me with CVE numbers. CVE-2016-10177 for #1 (Backdoor accounts) CVE-2016-10178 for #2 (Backdoor) CVE-2016-10179 for #3 (hardcoded WPS PIN) CVE-2016-10180 for #4 (WPS PIN generation based on srand(time(0)) seeding) CVE-2016-10181 for #5 (qmiweb leaks information) CVE-2016-10182 for #6 (qmiweb allows command injection with ` characters) CVE-2016-10183 for #7 (qmiweb allows directory listing with ../ traversal) CVE-2016-10184 for #8 (qmiweb allows file reading with ..%2f traversal) CVE-2016-10185 for #9 (A secure_mode=no line exists in /var/miniupnpd.conf) CVE-2016-10186 for #10 (/var/miniupnpd.conf has no deny rules) Although D-link did not acknowledge all the vulnerabilities on its products, it released a new firmware on Oct 19, 2016 (DWR-932_fw_revB_2_03_eu_en_20161011.zip) that should fix several RCEs and backdoors. According to D-Link, there is no vulnerability as long as "potential attackers cannot connect to the secure wi-fi network"[1] - does it mean the product is secure as long as there are no attackers? A reader will note that D-Link did have a full advisory with PoCs for more than 100 days while taking no actions before public disclosure[2] and he/she will surely be able to verify the vulnerabilities by downloading an affected firmware and reversing the binaries (see my blog post for details). D-Link did not make any effort to contact the security researcher even after the initial advisory was published, but it posted its official answers and patches on their website that the security researcher found "by chance". [1] - http://ift.tt/2l1VdNp [2] - Report Timeline @ http://ift.tt/2deyBYo However, the corrected firmware still appears to have the backdoor in execution. The only security patches they made were: 1. renaming /sbin/telnetd to /sbin/xxlnetd (so the appmgr backdoor cannot be used by an attacker), 2. dropbear is now listening to port 47980/tcp or to port "999999999/tcp" instead of 22/tcp (still with root/1234). The appmgr backdoor is still present and running but ineffective (as /sbin/telnetd doesn't exist anymore): root@kali:~$ echo -ne "HELODBG" | nc -u 192.168.1.1 39889 <- will NOT start a telnetd on port 23/tcp because /sbin/telnetd was removed Interesting fact: Starting Dropbear with port 999999999/tcp will result in dropbear using the port 51711/tcp instead (999999999 & 0xFFFF). So, an attacker can still use the backdoor access to continue to root the device. With SSH: root@kali:~$ ssh -l root -p 47980 192.168.1.1 <- will provide a root shell with "1234" as a password. OR root@kali:~$ ssh -l root -p 51711 192.168.1.1 <- will provide a root shell with "1234" as a password. Following the reaction from D-Link and the lack of quality of the security patches, I finally advise users to trash their affected routers and I encourage security researchers to review security patches provided from D-Link instead of blindly trusting them. Note that future 0day vulnerabilities regarding D-Link products may be released at my will without coordinated disclosure ("Full disclosure"). "ALTERNATIVE FACT" - backdoor access are still present inside the new firmware: I would like to thank Gianni Carabelli for finding the password of the zip file provided by D-Link. root@kali:~# wget http://ift.tt/2kXyu9s root@kali:~# sha256sum DWR-932_fw_revB_2_03_eu_en_20161011.zip # in case of a modification of this file by D-link fb721979b235c9da9a9b8e505767ce04410b8c7f5035a73ac2c4cc0b9cada3bd DWR-932_fw_revB_2_03_eu_en_20161011.zip root@kali:~# dd if=DWR-932_fw_revB_2_03_eu_en_20161011.zip of=firmware.zip bs=64 skip=1 993106+1 records in 993106+1 records out 63558829 bytes (64 MB) copied, 1.29239 s, 49.2 MB/s root@kali:~# mkdir output && cd output && 7z x -pbeUT9Z ../firmware.zip root@kali:~/output# 7z x -pbeUT9Z firmware.zip 7-Zip 9.20 Copyright (c) 1999-2010 Igor Pavlov 2010-11-18 p7zip Version 9.20 (locale=en_US.UTF-8,Utf16=on,HugeFiles=on,1 CPU) Processing archive: ../firmware.zip Extracting 02.03EU Extracting 2K-cksum.txt Extracting 2K-mdm-image-mdm9625.yaffs2 Extracting appsboot.mbn Extracting mba.mbn Extracting mdm-image-boot-mdm9625.img Extracting mdm-image-mdm9625.yaffs2 Extracting mdm-recovery-image-boot-mdm9625.img Extracting mdm-recovery-image-mdm9625.yaffs2 Extracting mdm9625-usr-image.usrfs.yaffs2 Extracting qdsp6sw.mbn Extracting rpm.mbn Extracting sbl1.mbn Extracting tz.mbn Extracting wdt.mbn Everything is Ok Files: 15 Size: 145018347 Compressed: 63558829 root@kali:~/output# ls -latr total 141640 -rw
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
Remember The Anonymous Guy Who Wrote The 'Flight 93' Trump Essay?
Some conservatives may recall that back in September someone under the pseudonym Publius Decius Mus wrote an essay bashing Never Trump ...
from Google Alert - anonymous http://ift.tt/2l1U1d7
via IFTTT
from Google Alert - anonymous http://ift.tt/2l1U1d7
via IFTTT
40 comments
Hitler phone up for auction, highest bid from anonymous bidder in Washington DC (cnn.com ), divider line. 28. More: Weird, Ranulf Rayner, Adolf Hitler ...
from Google Alert - anonymous http://ift.tt/2kmu2hl
via IFTTT
from Google Alert - anonymous http://ift.tt/2kmu2hl
via IFTTT
Orioles: C Caleb Joseph loses salary arbitration case after setting MLB records for most AB and PA in a season with no RBI (ESPN)
from ESPN http://ift.tt/1eW1vUH
via IFTTT
via IFTTT
Ten anonymous Twitter profiles we like on #copolitics
They're sometimes funny, sometimes wacky and sometimes snotty (we're tired of “snarky”). They swing right; they lean left. Some weigh in often; some ...
from Google Alert - anonymous http://ift.tt/2kxmx9d
via IFTTT
from Google Alert - anonymous http://ift.tt/2kxmx9d
via IFTTT
Anonymous wants to 'make humanity great again' with global protest against Trump
The rhetoric of the Anonymous hacking collective has undoubtedly escalated following the election of Donald Trump, a figure loathed by many of the ...
from Google Alert - anonymous http://ift.tt/2kxllD0
via IFTTT
from Google Alert - anonymous http://ift.tt/2kxllD0
via IFTTT
Anonymous Stranger Donates Generously To PRRA
"We received a donation in the amount of $9,500 from an anonymous donor to build a new batting cage at Rotary Republic Park," says PRRA General ...
from Google Alert - anonymous http://ift.tt/2k4W6av
via IFTTT
from Google Alert - anonymous http://ift.tt/2k4W6av
via IFTTT
I have a new follower on Twitter
BB&A
We are an award-winning agency that has achieved global recognition for our change communications, employee engagement, and learning and development work
Surrey, UK
http://t.co/gToGdEuNtc
Following: 4187 - Followers: 4541
February 02, 2017 at 10:17AM via Twitter http://twitter.com/BBandA_Chat
ISS Daily Summary Report – 2/01/2017
Multi-Omics Collections: This morning the crew performed sampling in support of the JAXA Multi-Omics experiment. Various samples are collected and stowed in MELFI four times throughout the crew’s on-orbit duration in addition to a questionnaire and ingestion of fructooligosaccharide (FOS). The objective of Multi-Omics is to understand the gut ecosystem of astronauts in the space environment, especially focusing on the immune dysfunction, and to evaluate the impact of FOS. Robonaut Compact Peripheral Component Interconnect (CPCI) Inspection: The crew performed troubleshooting on the Robonaut chassis. Previous troubleshooting suggested an issue with two card that were returned and tested on the ground. The cards brought down were exonerated and during today’s activities teams received a good response from the Robonaut during first power up. Indicator lights were as expected for a working Robonaut. Various power cycles were performed while trying to narrow down intermittent fault statuses. Eventually the team exonerated several of the cables. The cards were not removed from the CPCI chassis and remain installed and all cables were left connected. Teams plan to analyze results to develop any forward actions. Robonaut is a humanoid robot designed with the versatility and dexterity to manipulate hardware, work in high risk environments, and respond safely to unexpected obstacles. Robonaut is comprised of a torso with two arms and a head, and two legs with end effectors that enable the robot to translate inside the ISS by interfacing with handrails and seat track. Robonaut is currently operated inside the International Space Station (ISS); in the future, it will perform tasks both inside and outside the ISS. The Robonaut Teleoperations System enables Robonaut to mimic the motions of a crewmember wearing specialized gloves, a vest and a visor providing a three-dimensional view through Robonaut’s eyes. Microgravity Science Glovebox (MSG) Window Replace: The crew removed the MSG Front window and replace it with a removable window assembly. The new window will allow for easier access to the MSG through the front, rather than smaller access ports on the side of the MSG. Packed Bed Reactor Experiment (PBRE) Module Exchange: The crew successfully exchanged the removed the Test Module in the PBRE located in the MSG. The crew removed most of the hardware configured in the MSG, then re-installed and reconnected the cables and hoses. The PBRE investigation studies the behavior of gases and liquids when they flow simultaneously through a column filled with fixed porous media. The porous media or “packing” can be made of different shapes and materials and are used widely in chemical engineering as a means to enhance the contact between two immiscible fluid phases (e.g., liquid-gas, water-oil, etc.). Packed columns can serve as reactors, scrubbers, strippers, etc. in systems where efficient interphase contact is desired, both on Earth and in space. Synchronized Position Hold, Engage, Reorient, Experimental Satellites Tether (SPHERES Tether): The crew conducted a conference with the ground team then setup and checkout the SPHERES, the work area in the Japanese Experiment Module (JEM), and the EXpedite PRocessing of Experiments to Space Station (EXPRESS) Laptop Computer (ELC) prior to testing. The crew will load the test specific software to the satellites and execute the first of two test sessions with ground support teams. The goal of the SPHERES Tether Demo is to study the dynamics of a tethered capture object and a “space tug” chase vehicle, improving computer programs and modeling needed for removing space debris as well as capturing scientific samples from other planets. Space Station Remote Manipulator System (SSRMS) Operations: Robotics Ground Controllers are configuring for the SpX-10 mission by translating the Mobile Transporter (MT) to Worksite 4, stowing the Special Purpose Dexterous Manipulator (SPDM) on Mobile Base System (MBS)2, and maneuvering the SSRMS to the Offset Grapple Start position. Japanese Experiment Module Remote Manipulator System (JEMRMS) Operations: Overnight Robotic Ground Controllers in JAXA Space Station Integration and Promotion Center (SSIPC) will be maneuvering JEMRMS and Small Fine Arm (SFA) in preparation for Exposed Facility Unit (EFU) Adapter transfer operations. Today’s Planned Activities All activities were completed unless otherwise noted. Lighting Effects Sleep Log Entry – Subject EKON-M. Observations and photography KORREKTSIYA. Logging Liquid and Food (Medicine) Intake ISS HAM Radio and Video Power Up JEF HDTV Software Update Setup SPHERES Battery Swap Robonaut Node 2 Camcorder Video Setup Robonaut Lab Camcorder Video Setup Robonaut Troubleshooting Acoustic Dosimeter Setup Day 3 Public Affairs Office (PAO) Event in High Definition (HD) – JEM Multi Omics Fecal Sample Operations Study of cardiovascular system under graded physical CYCLE load. Multi Omics Fecal Sample MELFI Insertion Multi Omics Fecal Stow ESA ACTIVE DOSIMETER MOBILE UNIT SWAP Environmental Health System (EHS) – Rad Detector Rotate SPHERES Battery Swap Robonaut Troubleshooting Verification of ИП-1 Flow Sensor Position Recharging Soyuz 732 Samsung PC Battery (if charge level is below 80%) Study of cardiovascular system under graded physical CYCLE load. СОЖ maintenance Verify connections per diagram in Figure 1 of referenced procedure Microgravity Science Glovebox Front Window Exchange SPHERES Battery Swap KORREKTSIYA. Logging Liquid and Food (Medicine) Intake Terminate Soyuz 732 Samsung PC Battery Recharge (as necessary) Greetings Video Footage SPHERES Crew Conference Public Affairs Office (PAO) High Definition (HD) Config LAB Setup PAO Preparation SPHERES Test Session Setup Public Affairs Office (PAO) Event in High Definition (HD) – Lab PILOT-T. Preparation for the experiment. KORREKTSIYA. Experiment setup Packed Bed Reactor Experiment Test Module Exchange SPHERES Battery Swap Deploy AC Inverter to NOD3 UOP3-J3, PS-120 Junction Box J4 power port. Life On The Station Photo and Video SPHERES Tether Demo Test Run PILOT-T. Experiment Ops. PILOT-T. Closeout Ops RELAKSATSIYA. Charging battery for Relaksatstiya experiment (initiate) SPHERES Test Session Shutdown CONTENT. Experiment Ops JEF HDTV RS232C-USB Cable Switch KORREKTSIYA. Logging Liquid and Food (Medicine) Intake Completed Task List Items WHC KTO Replace New Food Evaluation Ground Activities All activities were completed unless otherwise noted. MT Translate SPDM Stow Three-Day Look Ahead: Thursday, 02/02: Body Measures, SPHERES HALO, EML, BEAM Modal test Friday, 02/03: SPHERES HALO, ELF Sample Holder Exchange, EFU Adapter Transfer Saturday, 02/04: Weekly Housekeeping, Crew […]
from ISS On-Orbit Status Report http://ift.tt/2kVPe0Q
via IFTTT
from ISS On-Orbit Status Report http://ift.tt/2kVPe0Q
via IFTTT
I have a new follower on Twitter
CodaKid
CodaKid is an online kids coding and game design academy for kids ages 7 to 15.
Scottsdale AZ
http://t.co/QxUCw6eZSW
Following: 4949 - Followers: 6063
February 02, 2017 at 09:57AM via Twitter http://twitter.com/CodaKid
THN Deal: Join Certified Ethical Hacker Boot Camp Online Course (99% Off)
Not all hacking is bad hacking. How would you feel if you are offered a six-figure salary to hack computer networks and break into IT systems legally? Isn't career with such skill-set worth considering, right? With hackers and cyber criminals becoming smarter and sophisticated, ethical hackers are in high demand and being hired by almost every industry to protect their IT infrastructures. <

from The Hacker News http://ift.tt/2jGNsLV
via IFTTT
from The Hacker News http://ift.tt/2jGNsLV
via IFTTT
Hackers Offering Money to Company Insiders in Return for Confidential Data
The insider threat is the worst nightmare for a company, as the employees can access company's most sensitive data without having to circumvent security measures designed to keep out external threats. The rogue employee can collect, leak, or sell all your secrets, including professional, confidential, and upcoming project details, to your rival companies and much more that could result in

from The Hacker News http://ift.tt/2jYSrsc
via IFTTT
from The Hacker News http://ift.tt/2jYSrsc
via IFTTT
I have a new follower on Twitter
Jay Graves
Jay Graves. Dad. Database nerd. Dude who quotes Fletch. Overly enthusiastic about most things data, business and productivity. And there are two b's in Babar...
Nashville, TN
https://t.co/dH5Ekt1x9u
Following: 934 - Followers: 1355
February 02, 2017 at 06:07AM via Twitter http://twitter.com/allballbearings
I have a new follower on Twitter
AllSight
AllSight is the first Customer Intelligence Management system that manages and synthesizes ALL data to provide the 'big picture' for your customer.
Toronto, ON
http://t.co/hZm9rPLRZf
Following: 1718 - Followers: 2255
February 02, 2017 at 06:07AM via Twitter http://twitter.com/AllSight
Critical WordPress REST API Bug: Prevent Your Blog From Being Hacked!
Last week, WordPress patched three security flaws, but just yesterday the company disclosed about a nasty then-secret zero-day vulnerability that let remote unauthorized hackers modify the content of any post or page within a WordPress site. The nasty bug resides in Wordpress REST API that would lead to the creation of two new vulnerabilities: Remote privilege escalation and Content injection

from The Hacker News http://ift.tt/2kk4wJB
via IFTTT
from The Hacker News http://ift.tt/2kk4wJB
via IFTTT
New anonymous reporting system helps keep Edgerton students safe
EDGERTON, Wis. - The Edgerton School District's new anonymous alert system just started at the beginning of the year, and officials are hoping it ...
from Google Alert - anonymous http://ift.tt/2kVnQwI
via IFTTT
from Google Alert - anonymous http://ift.tt/2kVnQwI
via IFTTT
Wednesday, February 1, 2017
I have a new follower on Twitter
KellyMartinBroderick
#feminist I ♥ Wonder Woman, red lipstick, Irish Whiskey, and Ellen Ripley - my cat. https://t.co/VNFfalHmSL
Baltimore, MD
https://t.co/fN9pq7OURf
Following: 1539 - Followers: 751
February 01, 2017 at 10:06PM via Twitter http://twitter.com/artsykelly
Towards "AlphaChem": Chemical Synthesis Planning with Tree Search and Deep Neural Network Policies. (arXiv:1702.00020v1 [cs.AI])
Retrosynthesis is a technique to plan the chemical synthesis of organic molecules, for example drugs, agro- and fine chemicals. In retrosynthesis, a search tree is built by analysing molecules recursively and dissecting them into simpler molecular building blocks until one obtains a set of known building blocks. The search space is intractably large, and it is difficult to determine the value of retrosynthetic positions. Here, we propose to model retrosynthesis as a Markov Decision Process. In combination with a Deep Neural Network policy learned from essentially the complete published knowledge of chemistry, Monte Carlo Tree Search (MCTS) can be used to evaluate positions. In exploratory studies, we demonstrate that MCTS with neural network policies outperforms the traditionally used best-first search with hand-coded heuristics.
from cs.AI updates on arXiv.org http://ift.tt/2kTo5va
via IFTTT
Blue Sky Ideas in Artificial Intelligence Education from the EAAI 2017 New and Future AI Educator Program. (arXiv:1702.00137v1 [cs.AI])
The 7th Symposium on Educational Advances in Artificial Intelligence (EAAI'17, co-chaired by Sven Koenig and Eric Eaton) launched the EAAI New and Future AI Educator Program to support the training of early-career university faculty, secondary school faculty, and future educators (PhD candidates or postdocs who intend a career in academia). As part of the program, awardees were asked to address one of the following "blue sky" questions:
* How could/should Artificial Intelligence (AI) courses incorporate ethics into the curriculum?
* How could we teach AI topics at an early undergraduate or a secondary school level?
* AI has the potential for broad impact to numerous disciplines. How could we make AI education more interdisciplinary, specifically to benefit non-engineering fields?
This paper is a collection of their responses, intended to help motivate discussion around these issues in AI education.
from cs.AI updates on arXiv.org http://ift.tt/2kj4gKM
via IFTTT
Robust Order Scheduling in the Fashion Industry: A Multi-Objective Optimization Approach. (arXiv:1702.00159v1 [cs.NE])
In the fashion industry, order scheduling focuses on the assignment of production orders to appropriate production lines. In reality, before a new order can be put into production, a series of activities known as pre-production events need to be completed. In addition, in real production process, owing to various uncertainties, the daily production quantity of each order is not always as expected. In this research, by considering the pre-production events and the uncertainties in the daily production quantity, robust order scheduling problems in the fashion industry are investigated with the aid of a multi-objective evolutionary algorithm (MOEA) called nondominated sorting adaptive differential evolution (NSJADE). The experimental results illustrate that it is of paramount importance to consider pre-production events in order scheduling problems in the fashion industry. We also unveil that the existence of the uncertainties in the daily production quantity heavily affects the order scheduling.
from cs.AI updates on arXiv.org http://ift.tt/2kTsyOD
via IFTTT
A Hybrid Evolutionary Algorithm Based on Solution Merging for the Longest Arc-Preserving Common Subsequence Problem. (arXiv:1702.00318v1 [cs.AI])
The longest arc-preserving common subsequence problem is an NP-hard combinatorial optimization problem from the field of computational biology. This problem finds applications, in particular, in the comparison of arc-annotated Ribonucleic acid (RNA) sequences. In this work we propose a simple, hybrid evolutionary algorithm to tackle this problem. The most important feature of this algorithm concerns a crossover operator based on solution merging. In solution merging, two or more solutions to the problem are merged, and an exact technique is used to find the best solution within this union. It is experimentally shown that the proposed algorithm outperforms a heuristic from the literature.
from cs.AI updates on arXiv.org http://ift.tt/2kj0H7x
via IFTTT
Edward: A library for probabilistic modeling, inference, and criticism. (arXiv:1610.09787v3 [stat.CO] UPDATED)
Probabilistic modeling is a powerful approach for analyzing empirical information. We describe Edward, a library for probabilistic modeling. Edward's design reflects an iterative process pioneered by George Box: build a model of a phenomenon, make inferences about the model given data, and criticize the model's fit to the data. Edward supports a broad class of probabilistic models, efficient algorithms for inference, and many techniques for model criticism. The library builds on top of TensorFlow to support distributed training and hardware such as GPUs. Edward enables the development of complex probabilistic models and their algorithms at a massive scale.
from cs.AI updates on arXiv.org http://ift.tt/2fb93u5
via IFTTT
Online Sequence-to-Sequence Active Learning for Open-Domain Dialogue Generation. (arXiv:1612.03929v4 [cs.CL] UPDATED)
We propose an online, end-to-end, neural generative conversational model for open-domain dialog. It is trained using a unique combination of offline two-phase supervised learning and online human-in-the-loop active learning. While most existing research proposes offline supervision or hand-crafted reward functions for online reinforcement, we devise a novel interactive learning mechanism based on a diversity-promoting heuristic for response generation and one-character user-feedback at each step. Experiments show that our model inherently promotes the generation of meaningful, relevant and interesting responses, and can be used to train agents with customized personas, moods and conversational styles.
from cs.AI updates on arXiv.org http://ift.tt/2hCSEDX
via IFTTT
Anonymous calls for travel ban on U.S. citizens, boycott of Trump…
The hacker collective Anonymous has once again set its targets on U.S. President Donald Trump, calling on people around the world to find ways of ...
from Google Alert - anonymous http://ift.tt/2kT4MCi
via IFTTT
from Google Alert - anonymous http://ift.tt/2kT4MCi
via IFTTT
Anonymous donor spends $13250 to pay lunch debts for 148 students
Embed Share An anonymous donor paid off lunch debts for 148 elementary school students. HUMANKIND An anonymous donor paid off lunch ...
from Google Alert - anonymous http://ift.tt/2jZulQx
via IFTTT
from Google Alert - anonymous http://ift.tt/2jZulQx
via IFTTT
Goddesses Anonymous
Showing 1-4 of 4 results for “Goddesses Anonymous”. Sorted by date added, Popularity, Relevance, Release date, Title, Author. Filters. Filter search ...
from Google Alert - anonymous http://ift.tt/2kTyx2v
via IFTTT
from Google Alert - anonymous http://ift.tt/2kTyx2v
via IFTTT
Buddy Montana for Ballers Anonymous
Another break from the usual style. An illustration of Michael Jordan for Ballers Anonymous. Check them out on Instagram at @ballers_anonymous_.
from Google Alert - anonymous http://ift.tt/2kTuaEN
via IFTTT
from Google Alert - anonymous http://ift.tt/2kTuaEN
via IFTTT
Immediately Executing Anonymous Functions
... to get it all in one place. One way we can do that is to use an immediately executing anonymous function or closure. Let's check out how this works.
from Google Alert - anonymous http://ift.tt/2kWpfCe
via IFTTT
from Google Alert - anonymous http://ift.tt/2kWpfCe
via IFTTT
ISS Daily Summary Report – 1/31/2017
64 Progress (64P) Undock: 64P successfully undocked from the Docking Compartment 1 (DC-1) port this morning at 8:25 AM CST. Deorbit burn was at 11:34 AM CST today followed by atmospheric entry and destruction. Crew Autonomous Scheduling Test (CAST): The third of five sessions was completed today. The objective of this session was to allow the crew to self-schedule and execute a flexible afternoon using the Playbook tool. This is the final step before the crewmember will schedule a full crew day. Space missions beyond low-Earth orbit require new approaches to daily operations between ground and crew to account for significant communication delays. One approach is increased autonomy for crews, or Autonomous Mission Operations. The CAST investigation analyzes whether crews can develop plans in a reasonable period of time with appropriate input, whether proximity of planners to the planned operations increases efficiency, and if crew members are more satisfied when given a role in plan development. Multi-Purpose Experiment Platform (MPEP) and Small Fine Arm Attachment Mechanism (SAM) Removal: The crew extended the JEM Airlock (JEMAL) slide table into the cabin and removed the MPEP and SAM facilities. On Thursday, the JEMAL will be depressed and the empty Slide Table will be extended. Ground controllers will be removing an Exposed Facility Unit (EFU) from the JEM External Facility (EF) and installing it on the Slide Table to make space on the EF for the High Definition Television Camera –Exposed Facility 2 (HDTV-EF2) experiment. HDTV-EF2 is a high-definition television camera system, which is used for earth observation from the ISS. Story Time From Space – Pendulous Demonstration: The crew configured and performed the pendulous experiment to demonstrate pendulous motion in a microgravity environment. The crew aligned the support stand (fulcrum) on the wall such that the beam points in the direction of the ISS’s velocity vector and is able to freely rotate and point towards Earth. Story Time From Space combines science literacy outreach with simple demonstrations recorded aboard the ISS. Crew members read five science, technology, engineering and mathematics-related children’s books in orbit, and complete simple science concept experiments. Crew members videotape themselves reading the books and completing demonstrations. Video and data collected during the demonstrations are downlinked to the ground and posted in a video library with accompanying educational materials. This is a videotaped narrated demonstration based on the children’s (K-8) book Max Goes to the Moon. Synchronized Position Hold, Engage, Reorient, Experimental Satellites (SPHERES) Slosh Tank Maneuvers: The crew, with ground support, performed manual maneuvers using the two partially filled tanks from the SPHERES Slosh experiment. Following ground instructions for the maneuvers, the crew observed the bubble formation in tanks of different fill quantities using single and double tank combinations and motions. The maneuvers that the crew will perform will provide valuable data for potential future in-space propellant storage required for deep space exploration. Several concepts include a configuration where two partially filled tanks are spinning in tandem. The SPHERES-Slosh investigation uses small robotic satellites to examine how liquids move around inside containers in microgravity. Bigelow Expandable Activity Module (BEAM) Modal Test Preparation: In preparation for Thursday’s BEAM modal test, the crew gathered and configured the necessary equipment including Space Acceleration Measurement System (SAMS) sensors and video cameras. BEAM is an experimental expandable capsule attached to the Node 3 aft Common Berthing Mechanism (CBM) port. The BEAM investigation will run approximately 2 years. BEAM is not an occupied module, and not used for stowage. During this time, BEAM is constantly monitored for temperature, pressure, and radiation. Periodically, four times per year, the ISS crew enters the module to collect data and check on its structural condition. Following the BEAM investigation, the module will be released from the ISS and burn up on reentry into the atmosphere. Radiation Dosimetry Inside ISS-Neutron (RaDI-N): After retrieving the RaDI-N hardware from the Russian crewmembers, a USOS crewmember deployed eight Space Bubble Detectors in Node 3 for the Radi-N2 experiment. The Canadian Space Agency (CSA) RaDI-N investigation will be conducted by measuring neutron radiation levels while onboard the ISS. RaDI-N uses bubble detectors as neutron monitors which have been designed to only detect neutrons and ignore all other radiation. Haptics-2: The crew completed two Haptics-2 protocols in coordination with ground support teams. The first protocol attempted to quantify the performance characteristics of the communication channel between the ISS and ground teams via software connections and data measurements. The aim of the second protocol was to demonstrate bilateral teleoperation with force-feedback between ISS and ground facilities. During the protocol the crew was asked to move a master one Degree of Freedom (1DOF) Setup joystick inside the Columbus module, in order to control in real-time the slave robotic joint located on Earth at European Space Technology Center (ESTEC). The crew was able to successfully complete the 15 trials, and due to crew efficiency repeated trials 1-11 a second time. The crew also executed a remote hand-shake with the members of the science team at the slave work-site. Microgravity Science Laboratory (MSL) Sample Cartridge Assembly (SCA) Exchange: The crew performed an exchange of the SCAs, replacing the used cartridge with the next in the series, Solidification along an Eutectic Path in Ternary Alloys (SETA)2-#9. The SETA investigation looks at how two phases that form together organize into lamellar, or fiber, structures when cooling Aluminum (Copper-Silver Alloys). Both, the SETA and Metastable Solidification of Composites (METCOMP) projects provide benchmark samples that will enable numerical model tests that aim to predict these structures. Lab Carbon Dioxide Removal Assembly (CDRA) Valve Power Cable Installation: Due to the intermittent Remote Power Controller (RPC) trip on the Lab CDRA, the CDRA Valve Power Cable was installed in order to isolate this trip. The six valves within CDRA are currently all powered from a single RPC. This new cable will initially power half of the six valves via a different RPC. Based on the results of the troubleshooting, the cable will be reconfigured to further isolate the trip source. Today’s Planned Activities […]
from ISS On-Orbit Status Report http://ift.tt/2kUYL3U
via IFTTT
from ISS On-Orbit Status Report http://ift.tt/2kUYL3U
via IFTTT
Completing checkout as anonymous user stores payment method
When performing checkout with an anonymous user, the payment method used is stored in the database and it is then available to any anonymous ...
from Google Alert - anonymous http://ift.tt/2jCsRYR
via IFTTT
from Google Alert - anonymous http://ift.tt/2jCsRYR
via IFTTT
[FD] secuvera-SA-2017-02: Reflected XSS and Open Redirect in MailStore Server
secuvera-SA-2017-02: Reflected XSS and Open Redirect in MailStore Server Affected Products MailStore Server Version 10.0.1.12148 was tested according to the vendor: - MailStore 9.2 to 10.0.1 is affected by the Reflected XSS Vulnerability - Mailstore 9.0 to 10.0.1 is affected by the Open Redirect Vulnerability References http://ift.tt/2jU6T4F CWE-79 http://ift.tt/1sECy8t CWE-601 http://ift.tt/1OqwbDo Summary: "MailStore Server is one of the world’s leading solutions for email archiving, management and compliance for small and medium-sized businesses." The in-built Webapplication does not properly validate untrusted input in several variables. This leads to both Reflected Cross-Site-Scripting (XSS) and an Open Redirect. Effect: To exploit the reflected XSS, the victim has to be authenticated to the Mailstore Webapplication. By clicking on a link sent to a victim, an attacker could for example copy the victims Session-ID to his on data sink. Sending another link with a crafted URL, the attacker could redirect the victim to a malicious website, while the link itself points to the trusted Mailstore-Address. The victim is not required to be authenticated. Vulnerable Scripts Reflected XSS for authenticated users: /search-result/, Parameters c-f, c-q, c-from and c-to /message/ajax/send/, Parameter recipient Vulnerable Script Open Redirect: derefer/, Parameter url Example for reflected XSS: http://ift.tt/2jVAj4T #Load external JS-Code http://ift.tt/2jU3gMb Example for Open Redirect: http://ift.tt/2jVsU5J Solution: Update to Version 10.0.2 Disclosure Timeline: 2017/01/09 vendor contacted 2017/01/10 initial vendor response asking for technical details 2017/01/10 provided vendor with the advisory including technical details 2017/01/13 vendor provided informations about affected versions and mitigation 2017/01/18 update published by vendor 2017/01/31 public disclosure Credits: Tobias Glemser tglemser@secuvera.de secuvera GmbH https://www.secuvera.de Disclaimer: All information is provided without warranty. The intent is to provide information to secure infrastructure and/or systems, not to be able to attack or damage. Therefore secuvera shall not be liable for any direct or indirect damages that might be caused by using this information.
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
[FD] secuvera-SA-2017-02: Reflected XSS and Open Redirect in MailStore Server
secuvera-SA-2017-02: Reflected XSS and Open Redirect in MailStore Server Affected Products MailStore Server Version 10.0.1.12148 was tested according to the vendor: - MailStore 9.2 to 10.0.1 is affected by the Reflected XSS Vulnerability - Mailstore 9.0 to 10.0.1 is affected by the Open Redirect Vulnerability References http://ift.tt/2jU6T4F CWE-79 http://ift.tt/1sECy8t CWE-601 http://ift.tt/1OqwbDo Summary: "MailStore Server is one of the world’s leading solutions for email archiving, management and compliance for small and medium-sized businesses." The in-built Webapplication does not properly validate untrusted input in several variables. This leads to both Reflected Cross-Site-Scripting (XSS) and an Open Redirect. Effect: To exploit the reflected XSS, the victim has to be authenticated to the Mailstore Webapplication. By clicking on a link sent to a victim, an attacker could for example copy the victims Session-ID to his on data sink. Sending another link with a crafted URL, the attacker could redirect the victim to a malicious website, while the link itself points to the trusted Mailstore-Address. The victim is not required to be authenticated. Vulnerable Scripts Reflected XSS for authenticated users: /search-result/, Parameters c-f, c-q, c-from and c-to /message/ajax/send/, Parameter recipient Vulnerable Script Open Redirect: derefer/, Parameter url Example for reflected XSS: http://ift.tt/2jVAj4T #Load external JS-Code http://ift.tt/2jU3gMb Example for Open Redirect: http://ift.tt/2jVsU5J Solution: Update to Version 10.0.2 Disclosure Timeline: 2017/01/09 vendor contacted 2017/01/10 initial vendor response asking for technical details 2017/01/10 provided vendor with the advisory including technical details 2017/01/13 vendor provided informations about affected versions and mitigation 2017/01/18 update published by vendor 2017/01/31 public disclosure Credits: Tobias Glemser tglemser@secuvera.de secuvera GmbH https://www.secuvera.de Disclaimer: All information is provided without warranty. The intent is to provide information to secure infrastructure and/or systems, not to be able to attack or damage. Therefore secuvera shall not be liable for any direct or indirect damages that might be caused by using this information.
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
[FD] Cross-Site Scripting vulnerability in Bitrix Site Manager
Hello list! There is Cross-Site Scripting vulnerability in Bitrix Site Manager.
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
[FD] Viscosity for Windows 1.6.7 Privilege Escalation
# Exploit Title: Viscosity for Windows 1.6.7 Privilege Escalation # Date: 31.01.2017 # Software Link: http://ift.tt/1FT1XGn # Exploit Author: Kacper Szurek # Contact: https://twitter.com/KacperSzurek # Website: http://ift.tt/2iHZPtU # Category: local 1. Description It is possible to execute openvpn with custom dll as SYSTEM using ViscosityService because path is not correctly validated. http://ift.tt/2jQTL0k 2. Proof of Concept http://ift.tt/2jVoiw8 3. Solution Update to version 1.6.8 http://ift.tt/2kQfyFf
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
Popular PlayStation and Xbox Gaming Forums Hacked; 2.5 Million Users' Data Leaked
Do you own an account on one of the two hugely popular PlayStation and Xbox gaming forums? Your details may have been exposed, as it has been revealed that the two popular video gaming forums, "XBOX360 ISO" and "PSP ISO," has been hacked, exposing email addresses, account passwords and IP addresses of 2.5 Million gamers globally. The attackers hacked and breached both "XBOX360 ISO" and "PSP

from The Hacker News http://ift.tt/2kfBVoK
via IFTTT
from The Hacker News http://ift.tt/2kfBVoK
via IFTTT
Police Arrested Suspected Hacker Who Hacked the 'Hacking Team'
Remember the Hacker who hacked Hacking Team? In 2015, a hacker named Phineas Fisher hacked Hacking Team – the Italy-based spyware company that sells spying software to law enforcement agencies worldwide – and exposed some 500 gigabytes of internal data for anyone to download. Now, the Spanish authorities believe that they have arrested Phineas Fisher, who was not just behind the embarrassing

from The Hacker News http://ift.tt/2kqbzCr
via IFTTT
from The Hacker News http://ift.tt/2kqbzCr
via IFTTT
Where to See the American Eclipse
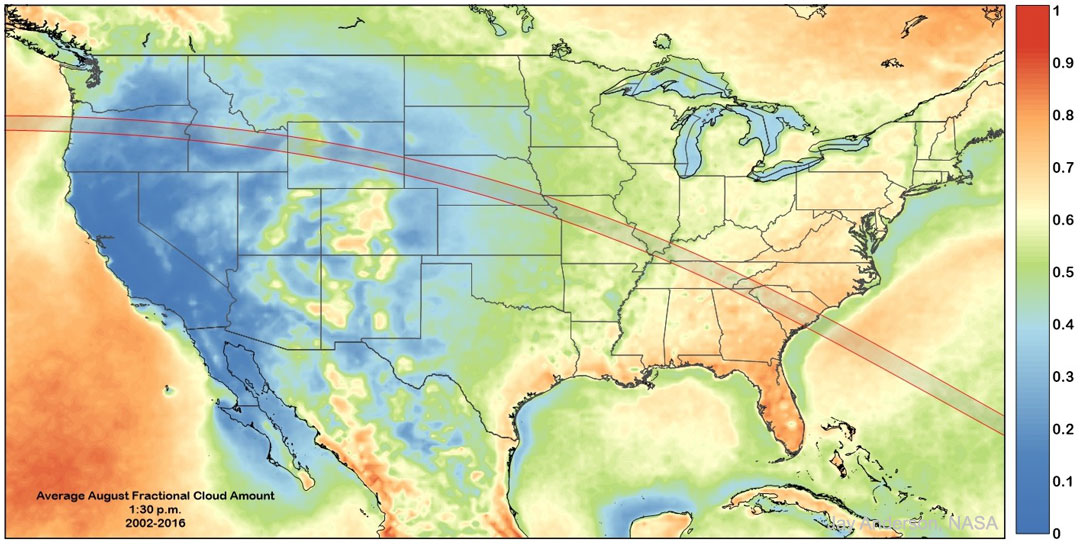
Are you planning to see the American Eclipse on August 21? A few hours after sunrise, a rare total eclipse of the Sun will be visible along a narrow path across the USA. Those only near the path will see a partial eclipse. Although some Americans live right in path of totality, surely many more will be able to get there after a well-planned drive. One problem with eclipses, though, is that clouds sometimes get in the way. To increase your clear-viewing odds, you might consult the featured map and find a convenient destination with a historically low chance (more blue) of thick clouds overhead during totality. Given the large fraction of Americans carrying camera-equipped smartphones, this American Eclipse may turn out to be the most photographed event in the history of the world. via NASA http://ift.tt/2jR3xiW
Tuesday, January 31, 2017
A Muvver (Anonymous)
Misc. Comments. A work by "Anonymous", which has been sung in pubs since 1900. TO be sung in a Cockney accent, if possible. Retrieved from ...
from Google Alert - anonymous http://ift.tt/2kSO0z2
via IFTTT
from Google Alert - anonymous http://ift.tt/2kSO0z2
via IFTTT
C3A: A Cognitive Collaborative Control Architecture For an Intelligent Wheelchair. (arXiv:1701.08761v1 [cs.RO])
Retention of residual skills for persons who partially lose their cognitive or physical ability is of utmost importance. Research is focused on developing systems that provide need-based assistance for retention of such residual skills. This paper describes a novel cognitive collaborative control architecture C3A, designed to address the challenges of developing need- based assistance for wheelchair navigation. Organization of C3A is detailed and results from simulation of the proposed architecture is presented. For simulation of our proposed architecture, we have used ROS (Robot Operating System) as a control framework and a 3D robotic simulator called USARSim (Unified System for Automation and Robot Simulation).
from cs.AI updates on arXiv.org http://ift.tt/2kSzK9s
via IFTTT
Algorithm selection of off-policy reinforcement learning algorithm. (arXiv:1701.08810v1 [stat.ML])
Dialogue systems rely on a careful reinforcement learning design: the learning algorithm and its state space representation. In lack of more rigorous knowledge, the designer resorts to its practical experience to choose the best option. In order to automate and to improve the performance of the aforementioned process, this article formalises the problem of online off-policy reinforcement learning algorithm selection. A meta-algorithm is given for input a portfolio constituted of several off-policy reinforcement learning algorithms. It then determines at the beginning of each new trajectory, which algorithm in the portfolio is in control of the behaviour during the full next trajectory, in order to maximise the return. The article presents a novel meta-algorithm, called Epochal Stochastic Bandit Algorithm Selection (ESBAS). Its principle is to freeze the policy updates at each epoch, and to leave a rebooted stochastic bandit in charge of the algorithm selection. Under some assumptions, a thorough theoretical analysis demonstrates its near-optimality considering the structural sampling budget limitations. Then, ESBAS is put to the test in a set of experiments with various portfolios, on a negotiation dialogue game. The results show the practical benefits of the algorithm selection for dialogue systems, in most cases even outperforming the best algorithm in the portfolio, even when the aforementioned assumptions are transgressed.
from cs.AI updates on arXiv.org http://ift.tt/2kpeITa
via IFTTT
Expert Level control of Ramp Metering based on Multi-task Deep Reinforcement Learning. (arXiv:1701.08832v1 [cs.AI])
This article shows how the recent breakthroughs in Reinforcement Learning (RL) that have enabled robots to learn to play arcade video games, walk or assemble colored bricks, can be used to perform other tasks that are currently at the core of engineering cyberphysical systems. We present the first use of RL for the control of systems modeled by discretized non-linear Partial Differential Equations (PDEs) and devise a novel algorithm to use non-parametric control techniques for large multi-agent systems. We show how neural network based RL enables the control of discretized PDEs whose parameters are unknown, random, and time-varying. We introduce an algorithm of Mutual Weight Regularization (MWR) which alleviates the curse of dimensionality of multi-agent control schemes by sharing experience between agents while giving each agent the opportunity to specialize its action policy so as to tailor it to the local parameters of the part of the system it is located in.
from cs.AI updates on arXiv.org http://ift.tt/2kOsgW3
via IFTTT
Interaction Information for Causal Inference: The Case of Directed Triangle. (arXiv:1701.08868v1 [cs.AI])
Interaction information is one of the multivariate generalizations of mutual information, which expresses the amount information shared among a set of variables, beyond the information, which is shared in any proper subset of those variables. Unlike (conditional) mutual information, which is always non-negative, interaction information can be negative. We utilize this property to find the direction of causal influences among variables in a triangle topology under some mild assumptions.
from cs.AI updates on arXiv.org http://ift.tt/2kpeJqc
via IFTTT
Deep Reinforcement Learning for Robotic Manipulation-The state of the art. (arXiv:1701.08878v1 [cs.RO])
The focus of this work is to enumerate the various approaches and algorithms that center around application of reinforcement learning in robotic ma- ]]nipulation tasks. Earlier methods utilized specialized policy representations and human demonstrations to constrict the policy. Such methods worked well with continuous state and policy space of robots but failed to come up with generalized policies. Subsequently, high dimensional non-linear function approximators like neural networks have been used to learn policies from scratch. Several novel and recent approaches have also embedded control policy with efficient perceptual representation using deep learning. This has led to the emergence of a new branch of dynamic robot control system called deep r inforcement learning(DRL). This work embodies a survey of the most recent algorithms, architectures and their implementations in simulations and real world robotic platforms. The gamut of DRL architectures are partitioned into two different branches namely, discrete action space algorithms(DAS) and continuous action space algorithms(CAS). Further, the CAS algorithms are divided into stochastic continuous action space(SCAS) and deterministic continuous action space(DCAS) algorithms. Along with elucidating an organ- isation of the DRL algorithms this work also manifests some of the state of the art applications of these approaches in robotic manipulation tasks.
from cs.AI updates on arXiv.org http://ift.tt/2kppSHu
via IFTTT
CommAI: Evaluating the first steps towards a useful general AI. (arXiv:1701.08954v1 [cs.LG])
With machine learning successfully applied to new daunting problems almost every day, general AI starts looking like an attainable goal. However, most current research focuses instead on important but narrow applications, such as image classification or machine translation. We believe this to be largely due to the lack of objective ways to measure progress towards broad machine intelligence. In order to fill this gap, we propose here a set of concrete desiderata for general AI, together with a platform to test machines on how well they satisfy such desiderata, while keeping all further complexities to a minimum.
from cs.AI updates on arXiv.org http://ift.tt/2kSrOoN
via IFTTT
On the Semantics and Complexity of Probabilistic Logic Programs. (arXiv:1701.09000v1 [cs.AI])
We examine the meaning and the complexity of probabilistic logic programs that consist of a set of rules and a set of independent probabilistic facts (that is, programs based on Sato's distribution semantics). We focus on two semantics, respectively based on stable and on well-founded models. We show that the semantics based on stable models (referred to as the "credal semantics") produces sets of probability models that dominate infinitely monotone Choquet capacities, we describe several useful consequences of this result. We then examine the complexity of inference with probabilistic logic programs. We distinguish between the complexity of inference when a probabilistic program and a query are given (the inferential complexity), and the complexity of inference when the probabilistic program is fixed and the query is given (the query complexity, akin to data complexity as used in database theory). We obtain results on the inferential and query complexity for acyclic, stratified, and cyclic propositional and relational programs, complexity reaches various levels of the counting hierarchy and even exponential levels.
from cs.AI updates on arXiv.org http://ift.tt/2kOo3kX
via IFTTT
Comparing Dataset Characteristics that Favor the Apriori, Eclat or FP-Growth Frequent Itemset Mining Algorithms. (arXiv:1701.09042v1 [cs.DB])
Frequent itemset mining is a popular data mining technique. Apriori, Eclat, and FP-Growth are among the most common algorithms for frequent itemset mining. Considerable research has been performed to compare the relative performance between these three algorithms, by evaluating the scalability of each algorithm as the dataset size increases. While scalability as data size increases is important, previous papers have not examined the performance impact of similarly sized datasets that contain different itemset characteristics. This paper explores the effects that two dataset characteristics can have on the performance of these three frequent itemset algorithms. To perform this empirical analysis, a dataset generator is created to measure the effects of frequent item density and the maximum transaction size on performance. The generated datasets contain the same number of rows. This provides some insight into dataset characteristics that are conducive to each algorithm. The results of this paper's research demonstrate Eclat and FP-Growth both handle increases in maximum transaction size and frequent itemset density considerably better than the Apriori algorithm.
This paper explores the effects that two dataset characteristics can have on the performance of these three frequent itemset algorithms. To perform this empirical analysis, a dataset generator is created to measure the effects of frequent item density and the maximum transaction size on performance. The generated datasets contain the same number of rows. This provides some insight into dataset characteristics that are conducive to each algorithm. The results of this paper's research demonstrate Eclat and FP-Growth both handle increases in maximum transaction size and frequent itemset density considerably better than the Apriori algorithm.
from cs.AI updates on arXiv.org http://ift.tt/2jsVixp
via IFTTT
Efficient Rank Aggregation via Lehmer Codes. (arXiv:1701.09083v1 [cs.LG])
We propose a novel rank aggregation method based on converting permutations into their corresponding Lehmer codes or other subdiagonal images. Lehmer codes, also known as inversion vectors, are vector representations of permutations in which each coordinate can take values not restricted by the values of other coordinates. This transformation allows for decoupling of the coordinates and for performing aggregation via simple scalar median or mode computations. We present simulation results illustrating the performance of this completely parallelizable approach and analytically prove that both the mode and median aggregation procedure recover the correct centroid aggregate with small sample complexity when the permutations are drawn according to the well-known Mallows models. The proposed Lehmer code approach may also be used on partial rankings, with similar performance guarantees.
from cs.AI updates on arXiv.org http://ift.tt/2kplubs
via IFTTT
Robust Multilingual Named Entity Recognition with Shallow Semi-Supervised Features. (arXiv:1701.09123v1 [cs.CL])
We present a multilingual Named Entity Recognition approach based on a robust and general set of features across languages and datasets. Our system combines shallow local information with clustering semi-supervised features induced on large amounts of unlabeled text. Understanding via empirical experimentation how to effectively combine various types of clustering features allows us to seamlessly export our system to other datasets and languages. The result is a simple but highly competitive system which obtains state of the art results across five languages and twelve datasets. The results are reported on standard shared task evaluation data such as CoNLL for English, Spanish and Dutch. Furthermore, and despite the lack of linguistically motivated features, we also report best results for languages such as Basque and German. In addition, we demonstrate that our method also obtains very competitive results even when the amount of supervised data is cut by half, alleviating the dependency on manually annotated data. Finally, the results show that our emphasis on clustering features is crucial to develop robust out-of-domain models. The system and models are freely available to facilitate its use and guarantee the reproducibility of results.
from cs.AI updates on arXiv.org http://ift.tt/2kpuRb1
via IFTTT
Efficient Learning in Large-Scale Combinatorial Semi-Bandits. (arXiv:1406.7443v4 [cs.LG] UPDATED)
A stochastic combinatorial semi-bandit is an online learning problem where at each step a learning agent chooses a subset of ground items subject to combinatorial constraints, and then observes stochastic weights of these items and receives their sum as a payoff. In this paper, we consider efficient learning in large-scale combinatorial semi-bandits with linear generalization, and as a solution, propose two learning algorithms called Combinatorial Linear Thompson Sampling (CombLinTS) and Combinatorial Linear UCB (CombLinUCB). Both algorithms are computationally efficient as long as the offline version of the combinatorial problem can be solved efficiently. We establish that CombLinTS and CombLinUCB are also provably statistically efficient under reasonable assumptions, by developing regret bounds that are independent of the problem scale (number of items) and sublinear in time. We also evaluate CombLinTS on a variety of problems with thousands of items. Our experiment results demonstrate that CombLinTS is scalable, robust to the choice of algorithm parameters, and significantly outperforms the best of our baselines.
from cs.AI updates on arXiv.org http://ift.tt/1x7UzyF
via IFTTT
Combinatorial Aspects of the Distribution of Rough Objects. (arXiv:1605.01778v2 [cs.AI] UPDATED)
The inverse problem of general rough sets, considered by the present author in some of her earlier papers, in one of its manifestations is essentially the question of when an agent's view about crisp and non crisp objects over a set of objects has a rough evolution. In this research the nature of the problem is examined from number-theoretic and combinatorial perspectives under very few assumptions about the nature of data and some necessary conditions are proved.
from cs.AI updates on arXiv.org http://ift.tt/1XgbehY
via IFTTT
Evaluating Induced CCG Parsers on Grounded Semantic Parsing. (arXiv:1609.09405v2 [cs.CL] UPDATED)
We compare the effectiveness of four different syntactic CCG parsers for a semantic slot-filling task to explore how much syntactic supervision is required for downstream semantic analysis. This extrinsic, task-based evaluation provides a unique window to explore the strengths and weaknesses of semantics captured by unsupervised grammar induction systems. We release a new Freebase semantic parsing dataset called SPADES (Semantic PArsing of DEclarative Sentences) containing 93K cloze-style questions paired with answers. We evaluate all our models on this dataset. Our code and data are available at http://ift.tt/2kOi2oC.
from cs.AI updates on arXiv.org http://ift.tt/2dDK0QD
via IFTTT
Design Mining Microbial Fuel Cell Cascades. (arXiv:1610.05716v2 [cs.NE] UPDATED)
Microbial fuel cells (MFCs) perform wastewater treatment and electricity production through the conversion of organic matter using microorganisms. For practical applications, it has been suggested that greater efficiency can be achieved by arranging multiple MFC units into physical stacks in a cascade with feedstock flowing sequentially between units. In this paper, we investigate the use of computational intelligence to physically explore and optimise (potentially) heterogeneous MFC designs in a cascade, i.e. without simulation. Conductive structures are 3-D printed and inserted into the anodic chamber of each MFC unit, augmenting a carbon fibre veil anode and affecting the hydrodynamics, including the feedstock volume and hydraulic retention time, as well as providing unique habitats for microbial colonisation. We show that it is possible to use design mining to identify new conductive inserts that increase both the cascade power output and power density.
from cs.AI updates on arXiv.org http://ift.tt/2dm3pZm
via IFTTT
An Integrated Optimization + Learning Approach to Optimal Dynamic Pricing for the Retailer with Multi-type Customers in Smart Grids. (arXiv:1612.05971v2 [cs.SY] UPDATED)
In this paper, we consider a realistic and meaningful scenario in the context of smart grids where an electricity retailer serves three different types of customers, i.e., customers with an optimal home energy management system embedded in their smart meters (C-HEMS), customers with only smart meters (C-SM), and customers without smart meters (C-NONE). The main objective of this paper is to support the retailer to make optimal day-ahead dynamic pricing decisions in such a mixed customer pool. To this end, we propose a two-level decision-making framework where the retailer acting as upper-level agent firstly announces its electricity prices of next 24 hours and customers acting as lower-level agents subsequently schedule their energy usages accordingly. For the lower level problem, we model the price responsiveness of different customers according to their unique characteristics. For the upper level problem, we optimize the dynamic prices for the retailer to maximize its profit subject to realistic market constraints. The above two-level model is tackled by genetic algorithms (GAs) based distributed optimization methods while its feasibility and effectiveness are confirmed via simulation results.
from cs.AI updates on arXiv.org http://ift.tt/2hOrJot
via IFTTT
Plotting an Anonymous Function
I have created an anonymous function sqr = @(x) x.^2;. and I am trying different methods for plotting this function, and none seem to plot the function ...
from Google Alert - anonymous http://ift.tt/2jTb6Ir
via IFTTT
from Google Alert - anonymous http://ift.tt/2jTb6Ir
via IFTTT
Anonymous Group Reveals Phone Numbers For White House Staffers
President Trump shut down the White House public comments line upon taking office, but that hasn't stopped an anonymous group of citizens from ...
from Google Alert - anonymous http://ift.tt/2jSn4iO
via IFTTT
from Google Alert - anonymous http://ift.tt/2jSn4iO
via IFTTT
Rumor Central: Orioles could still be looking to add defensive OF like Angel Pagan, Michael Bourn - BaltimoreBaseball.com (ESPN)
from ESPN http://ift.tt/1eW1vUH
via IFTTT
via IFTTT
Anonymous call to action against Trump regime
Greetings Citizens of the World, We are Anonymous. This is an open call to establish travel bans on United States citizens, boycott US made products, ...
from Google Alert - anonymous http://ift.tt/2jRR7aH
via IFTTT
from Google Alert - anonymous http://ift.tt/2jRR7aH
via IFTTT
Program Supervisor (Parents Anonymous) -436
Serving our Community since 1947! Visit us at www.morrisonkids.org January 31, 2017 Program Supervisor Portland, Oregon Full Time, Full Benefits ...
from Google Alert - anonymous http://ift.tt/2jRgSdD
via IFTTT
from Google Alert - anonymous http://ift.tt/2jRgSdD
via IFTTT
Piedmont Opera receives $100000 anonymous donation
General Director and Principal Conductor James Allbritten announced today that an anonymous donor has stepped forward with a $100,000 donation ...
from Google Alert - anonymous http://ift.tt/2jQyJkH
via IFTTT
from Google Alert - anonymous http://ift.tt/2jQyJkH
via IFTTT
ISS Daily Summary Report – 1/30/2017
Fine Motor Skills (FMS): The crew performed their Flight Day 75 (FD75) FMS sessions this morning. Currently the crew is performing the test at a frequency of every 5 days for the first three months that they are onboard the ISS. After FD90 the crew will transition to a frequency of FMS sessions every 14 days. The FMS experiment is executed on a touchscreen tablet, where the crew performs a series of interactive tasks. The investigation studies how fine motor skills are effected by long-term microgravity exposure, different phases of microgravity adaptation, and sensorimotor recovery after returning to Earth gravity. The goal of FMS is to answer how fine motor performance in microgravity trend/vary over the duration of a six-month and year-long space mission; how fine motor performance on orbit compare with that of a closely matched participant on Earth; and how performance trend/vary before and after gravitational transitions, including the periods of early flight adaptation, and very early/near immediate post-flight periods. Story Time From Space – Light Demo: The crew recorded an educational video based on three children’s books (Max Goes to Mars, The Wizard Who Saved the World, Max Goes to Jupiter). The video highlights the visible light spectrum and the attenuation of the intensity of the Sun’s light as it is viewed through the atmosphere. Story Time From Space combines science literacy outreach with simple demonstrations recorded aboard the ISS. Crew members read five science, technology, engineering and mathematics-related children’s books in orbit, and complete simple science concept experiments. Crew members videotape themselves reading the books and completing demonstrations. Video and data collected during the demonstrations are downlinked to the ground and posted in a video library with accompanying educational materials. Meteor Hard Drive Swap: The crew performed a regular changeout of the Meteor hard drive located in the Window Observational Research Facility (WORF). The Meteor payload is a visible spectroscopy instrument with the primary purpose of observing meteors in Earth orbit. Meteor uses image analysis to provide information on the physical and chemical properties of the meteoroid dust, such as size, density, and chemical composition. Since the parent comets or asteroids for most of the meteor showers are identified, the study of the meteoroid dust on orbit provides information about the parent comets and asteroids. Lighting Effects Sleep Study: The Lighting Effects subject has initiated a two week sleep logging data collection in support of the Lighting Effects investigation. Using an Actiwatch and Sleep Logs the crewmember will track their sleep patterns and wakefulness. Later this week the crewmember will perform a cognition test and over the weekend perform a 48-hour urine collection, with the samples placed in the Minus Eighty Degree Celsius Laboratory Freezer for ISS (MELFI) for a future return and ground analysis. The Testing Solid State Lighting Countermeasures to Improve Circadian Adaptation, Sleep, and Performance During High Fidelity Analog and Flight Studies for the International Space Station (Lighting Effects) investigation studies the impact of the change from fluorescent light bulbs to solid-state light-emitting diodes (LEDs) with adjustable intensity and color and aims to determine if the new lights can improve crew circadian rhythms, sleep, and cognitive performance. Pressurized Mating Adaptor (PMA) 2 Ingress: The crew completed a review of the planned PMA2 ingress activities. After gathering hardware, the crew removed stowage from the Node 2 endcone and ingressed PMA2. They removed the Common Berthing Mechanism (CBM) Controller Panel Assemblies (CPAs) that will be installed in the Node 3 Port/PMA 3 vestibule later in the increment in preparation for PMA 3 relocate along with some additional hardware. They installed an IMV Duct that will be used for future docked vehicles. The crew then inspected the PMA for evidence of microbial growth and condensation and evaluated whether a newly designed Hatch Depress Indicator is compatible with the PMA bulkhead. The crew also returned the Japanese Experiment Module (JEM) Orbital Replacement Unit (ORU) Transfer Interface (JOTI) hardware back into the PMA2, which was used during the Robotics External Leak Locator (RELL) demonstration last year, as well as some additional hardware that is not needed in the near term. Finally, they egressed PMA2 and returned the stowage to the Node 2 endcone. Cupola Audio Terminal Unit (ATU) Modification Kit Installation: The crew removed the existing Cupola ATU coldplate hardware and installed modified hardware. The new hardware protrudes less into the Cupola work volume and better protects the ATU flex lines from inadvertent damage. Mobile Servicing System (MSS) Operations: Last year, the Columbus Module experienced a power anomaly when a subset of Power Distribution Unit -1 (PDU-1) outlets went unexpectedly to OFF. Among the equipment that suddenly lost power was the RapidScat Feeder#1. The RapidScat power up troubleshooting attempts were not successful. The new ESA payload Atmosphere Space Interaction Monitor (ASIM), arriving on SpX-13, is currently planned for installation at the RapidScat site, therefore the electrical components of the payload site need to be tested to ensure that this location is fully operational. Today ground controllers removed RapidScat from the Columbus External Platform and then demated the electrical connector on the adapter plate to allow for troubleshooting of the interface. Based on the troubleshooting, the payload site on Columbus has been cleared, and the fault is isolated to RapidScat. Once the troubleshooting was completed, the ground controller mated the adapter plate connector and re-installed RapidScat. Today’s Planned Activities All activities were completed unless otherwise noted. Lighting Effects Sleep Log Entry – Subject Fine Motor Skills Experiment Test – Subject Fine Motor Skills Historical Documentation Photography Recharge Air Conditioner [СКВ1] with Freon from bottles, preparation. KORREKTSIA. Logging Liquid and Food Intake (Medicine) Columbus Video Camera Assembly 2 Adjustment Pressurized Mating Adapter 2 (PMA 2) Big Picture Word Review Columbus Payload Power Switching Box (PPSB) – Switch reconfiguration Protein Crystallization Research Facility (PCRF) Cable R&R Part1 Air Conditioner [СКВ1] refill with Freon from tanks. Pressurized Mating Adapter (PMA) 2 Hardware Gather Treadmill 2 (T2) Exercise Video Equipment Setup Acoustic Dosimeter Setup Day 1 Advanced Resistive Exercise Device (ARED) Cylinder […]
from ISS On-Orbit Status Report http://ift.tt/2kNMtyy
via IFTTT
from ISS On-Orbit Status Report http://ift.tt/2kNMtyy
via IFTTT
Lítačka can be anonymous
Lítačka can be anonymous. People will be able to get the public transportation card without giving personal details. by Raymond Johnston - Prague.
from Google Alert - anonymous http://ift.tt/2jQkwEj
via IFTTT
from Google Alert - anonymous http://ift.tt/2jQkwEj
via IFTTT
Trappin Anonymous
Trappin Anonymous (Cheating Anonymous)part 2 the male version, after many listeners asked for there to be they guy version of cheaters we said ...
from Google Alert - anonymous http://ift.tt/2jqoTYr
via IFTTT
from Google Alert - anonymous http://ift.tt/2jqoTYr
via IFTTT
Galena ARC receives anonymous $270 donation
Galena Art & Recreation Center officials received an anonymous $270 donation for its art program.
from Google Alert - anonymous http://ift.tt/2jPxItm
via IFTTT
from Google Alert - anonymous http://ift.tt/2jPxItm
via IFTTT
Facebook Unveils 'Delegated Recovery' to Replace Traditional Password Recovery Methods
How do you reset the password for your Facebook account if your primary email account also gets hacked? Using SMS-based security code or maybe answering the security questions? Well, it's 2017, and we are still forced to depend on insecure and unreliable password reset schemes like email-based or SMS code verification process. But these traditional access recovery mechanisms aren't safe

from The Hacker News http://ift.tt/2kKFH9m
via IFTTT
from The Hacker News http://ift.tt/2kKFH9m
via IFTTT
Re: [FD] [0-day] RCE and admin credential disclosure in NETGEAR WNR2000
Hello Pedro, We have noted the CVEs within our internal records and will update the kb accordingly. Thank you for letting us know. If you have time, are you able to verify the firmware remediates the vulnerability? Thank you for taking the time to continue to research this vulnerability. We appreciate all of the hard work you have put in to make Netgear's products more secure for everyone. NETGEAR’s mission is to be the innovative leader in connecting the world to the internet. To achieve this mission, we strive to earn and maintain the trust of our users that we will protect the privacy and security of their data. We take all security concerns brought forth seriously and are constantly monitoring the latest threats. Being pro-active rather than re-active to emerging security issues is a fundamental belief at NETGEAR. Every day new security issues and attack vectors are created. NETGEAR strives to keep abreast on the latest state-of-the-art security developments by working with security researchers and companies. We appreciate the community's efforts in creating a more secure world. If you have any questions or comments with regard to this information, please contact us at: security@netgear.com. Sincerely, Product Security Incident Response Team Netgear, Inc
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
Violin Sonata in B-flat major, Schrank II/34/47 (Anonymous)
Violin Sonata in B-flat major, Schrank II/34/47 (Anonymous) ... ?title=Violin_Sonata_in_B-flat_major,_Schrank_II/34/47_(Anonymous)&oldid=2258449".
from Google Alert - anonymous http://ift.tt/2jP7B5J
via IFTTT
from Google Alert - anonymous http://ift.tt/2jP7B5J
via IFTTT
Check If Your Netgear Router is also Vulnerable to this Password Bypass Flaw
Again bad news for consumers with Netgear routers: Netgear routers hit by another serious security vulnerability, but this time more than two dozens router models are affected. Security researchers from Trustwave are warning of a new authentication vulnerability in at least 31 models of Netgear models that potentially affects over one million Netgear customers. The new vulnerability,

from The Hacker News http://ift.tt/2jOSCso
via IFTTT
from The Hacker News http://ift.tt/2jOSCso
via IFTTT
Dobrado Landulpho Lintz
Composer, Anonymous. Key, A-flat major. Dedication, Coronel Landulpho Lintz. Piece Style, Early 20th century. Instrumentation, piccolo clarinet (E♭), ...
from Google Alert - anonymous http://ift.tt/2jpcbsL
via IFTTT
from Google Alert - anonymous http://ift.tt/2jpcbsL
via IFTTT
The Cats Eye Nebula from Hubble

To some, it may look like a cat's eye. The alluring Cat's Eye nebula, however, lies three thousand light-years from Earth across interstellar space. A classic planetary nebula, the Cat's Eye (NGC 6543) represents a final, brief yet glorious phase in the life of a sun-like star. This nebula's dying central star may have produced the simple, outer pattern of dusty concentric shells by shrugging off outer layers in a series of regular convulsions. But the formation of the beautiful, more complex inner structures is not well understood. Seen so clearly in this digitally reprocessed Hubble Space Telescope image, the truly cosmic eye is over half a light-year across. Of course, gazing into this Cat's Eye, astronomers may well be seeing the fate of our sun, destined to enter its own planetary nebula phase of evolution ... in about 5 billion years. via NASA http://ift.tt/2jNBEYX
Monday, January 30, 2017
I have a new follower on Twitter
IronPlanet Auctions
IronPlanet is the leading online marketplace for used heavy equipment and an innovative participant in the multi-billion dollar heavy equipment auction market.
North America,Europe,Australia
http://t.co/uphDv8mXPU
Following: 4168 - Followers: 26775
January 30, 2017 at 11:01PM via Twitter http://twitter.com/IronPlanet
I have a new follower on Twitter
Adrian Pineda López
Following: 86 - Followers: 0
January 30, 2017 at 09:36PM via Twitter http://twitter.com/AdrianPinedaLp1
Comparative Study Of Data Mining Query Languages. (arXiv:1701.08190v1 [cs.AI])
Since formulation of Inductive Database (IDB) problem, several Data Mining (DM) languages have been proposed, confirming that KDD process could be supported via inductive queries (IQ) answering. This paper reviews the existing DM languages. We are presenting important primitives of the DM language and classifying our languages according to primitives' satisfaction. In addition, we presented languages' syntaxes and tried to apply each one to a database sample to test a set of KDD operations. This study allows us to highlight languages capabilities and limits, which is very useful for future work and perspectives.
from cs.AI updates on arXiv.org http://ift.tt/2jNcw78
via IFTTT
Incremental Maintenance Of Association Rules Under Support Threshold Change. (arXiv:1701.08191v1 [cs.AI])
Maintenance of association rules is an interesting problem. Several incremental maintenance algorithms were proposed since the work of (Cheung et al, 1996). The majority of these algorithms maintain rule bases assuming that support threshold doesn't change. In this paper, we present incremental maintenance algorithm under support threshold change. This solution allows user to maintain its rule base under any support threshold.
from cs.AI updates on arXiv.org http://ift.tt/2jPkSsv
via IFTTT
Image-Grounded Conversations: Multimodal Context for Natural Question and Response Generation. (arXiv:1701.08251v1 [cs.CL])
The popularity of image sharing on social media reflects the important role visual context plays in everyday conversation. In this paper, we present a novel task, Image-Grounded Conversations (IGC), in which natural-sounding conversations are generated about shared photographic images. We investigate this task using training data derived from image-grounded conversations on social media and introduce a new dataset of crowd-sourced conversations for benchmarking progress. Experiments using deep neural network models trained on social media data show that the combination of visual and textual context can enhance the quality of generated conversational turns. In human evaluation, a gap between human performance and that of both neural and retrieval architectures suggests that IGC presents an interesting challenge for vision and language research.
from cs.AI updates on arXiv.org http://ift.tt/2kaGK2v
via IFTTT
Subscribe to:
Posts (Atom)