Posted by Anonymous 5SC on November 04, 2017. UFC 217: Michael Bisping vs. George St-Pierre, Live results, recaps and analysis Washington ...
from Google Alert - anonymous http://ift.tt/2hFFFQj
via IFTTT
Saturday, November 4, 2017
QS iOS mobile with anonymous login active
Hi all I used to have anonymous access for my QS instance. I successfully managed to enable iOS mobile on my server but I had to deactivate ...
from Google Alert - anonymous http://ift.tt/2yw0pEC
via IFTTT
from Google Alert - anonymous http://ift.tt/2yw0pEC
via IFTTT
Anonymous Hamburger Society
Anonymous Hamburger Society. Here you are our collection of more than edible dishes, and tones of new creative sparks. Made in Adoratorio with ...
from Google Alert - anonymous http://ift.tt/2lRmI1w
via IFTTT
from Google Alert - anonymous http://ift.tt/2lRmI1w
via IFTTT
Appendix: Collection of Anonymous Data
Overview of Frame-based Analysis for Your Videos anonymous data collection on AWS.
from Google Alert - anonymous http://ift.tt/2yxh2Q7
via IFTTT
from Google Alert - anonymous http://ift.tt/2yxh2Q7
via IFTTT
JuliaLang/julia
Return type assertions don't work with anonymous functions. #24469. Open. Ismael-VC opened this Issue 19 minutes ago · 0 comments ...
from Google Alert - anonymous http://ift.tt/2lPANMO
via IFTTT
from Google Alert - anonymous http://ift.tt/2lPANMO
via IFTTT
ck/ - Al/ck/oholics Anonymous
Al/ck/oholics Anonymous - "/ck/ - Food & Cooking" is 4chan's imageboard for food pictures and cooking recipes.
from Google Alert - anonymous http://ift.tt/2iu7GtK
via IFTTT
from Google Alert - anonymous http://ift.tt/2iu7GtK
via IFTTT
Warning: Critical Tor Browser Vulnerability Leaks Users’ Real IP Address—Update Now
If you follow us on Twitter, you must be aware that since yesterday we have been warning Mac and Linux users of the Tor anonymity browser about a critical vulnerability that could leak their real IP addresses to potential attackers when they visit certain types of web pages. Discovered by Italian security researcher Filippo Cavallarin, the vulnerability resides in FireFox that eventually also


from The Hacker News http://ift.tt/2zdyCpv
via IFTTT
from The Hacker News http://ift.tt/2zdyCpv
via IFTTT
Fake WhatsApp On Google Play Store Downloaded By Over 1 Million Android Users
Cybercriminals are known to take advantage of everything that's popular among people in order to spread malware, and Google's official Play Store has always proved no less than an excellent place for hackers to get their job done. Yesterday some users spotted a fake version of the most popular WhatsApp messaging app for Android on the official Google Play Store that has already tricked more

from The Hacker News http://ift.tt/2iZVwwA
via IFTTT
from The Hacker News http://ift.tt/2iZVwwA
via IFTTT
Clues emerge in anonymous Cranley fliers
Some new info tonight on anonymous ads in Cincinnati's mayoral race. We're doing what we can to follow the money @Local12 at 11 http://pic.twitter.com/ ...
from Google Alert - anonymous http://ift.tt/2zhyJT4
via IFTTT
from Google Alert - anonymous http://ift.tt/2zhyJT4
via IFTTT
ICESat-2 Orbit
ICESat-2 is a spacecraft designed to accurately measure land and ice elevations on Earth. By comparing observations from different times, scientists will be able to study changes in elevations. ICESat-2 will be in a polar orbit which will provide high coverage near the poles where ice elevations are changing relatively quickly. This visualization shows ICESat-2's polar orbit from afar, then closer up. As we get close to the satellite, the 3 pairs of ICESat-2's ATLAS lidar laser beams begin to resolve. A ground track shows ICESat-2's global coverage which repeats about once every 90 days. The ATLAS lidar on ICESat-2 uses 3 pairs of laser beams to measure the earth's elevation and elevation change. As a global mission, ICESat-2 will collect data over the entire globe, however the ATLAS instrument is optimized to measure land ice and sea ice elevation in the polar regions. For more information on ICESat-2 click here .
from NASA's Scientific Visualization Studio: Most Recent Items http://ift.tt/2j0FB10
via IFTTT
from NASA's Scientific Visualization Studio: Most Recent Items http://ift.tt/2j0FB10
via IFTTT
Friday, November 3, 2017
Anonymous citizen donates new 3-wheel bike to theft victim, police say
A victim of theft is back on three wheels this week after a generous anonymous citizen, police said.Beloit police said Thais Parkinson had her ...
from Google Alert - anonymous http://ift.tt/2zhALTl
via IFTTT
from Google Alert - anonymous http://ift.tt/2zhALTl
via IFTTT
Flix Anonymous - Episode 46
Trev and Steve review (spoiler free)Thor: Ragnarok followed by discussions on unnecessary reboots, Kevin Spacey, Bad Moms, and Stranger Things.
from Google Alert - anonymous http://ift.tt/2zxouL6
via IFTTT
from Google Alert - anonymous http://ift.tt/2zxouL6
via IFTTT
Ravens: Joe Flacco among a dozen players listed as questionable for Sunday at Titans (ESPN)
from ESPN http://ift.tt/17lH5T2
via IFTTT
via IFTTT
What is the difference between anonymous function and a variable statement with function ...
For the below 2 functions, I do not understand Function B is not run immediately like Function A when the script is read. Instead I have to call ...
from Google Alert - anonymous http://ift.tt/2A4V6Z2
via IFTTT
from Google Alert - anonymous http://ift.tt/2A4V6Z2
via IFTTT

The Tor Project to Beef Up Privacy with Next-Generation of Onion Services
The Tor Project has made some significant changes to its infrastructure by improving the way the 'onion' network protects its users' privacy and security. Since the beginning, the largest free online anonymity network has been helping users browse the web anonymously, and its onion service provides a network within which encrypted websites can be run anonymously. However, the infrastructure

from The Hacker News http://ift.tt/2hag8By
via IFTTT
from The Hacker News http://ift.tt/2hag8By
via IFTTT
Anonymous - Chef de Cuisine
Anonymous - Chef de Cuisine – Boston Restaurant Jobs - BostonChefs.com's Industry Insider, the best jobs at Boston restaurants.
from Google Alert - anonymous http://ift.tt/2zdRgQC
via IFTTT
from Google Alert - anonymous http://ift.tt/2zdRgQC
via IFTTT
[FD] KL-001-2017-022 : Splunk Local Privilege Escalation
KL-001-2017-022 : Splunk Local Privilege Escalation Title: Splunk Local Privilege Escalation Advisory ID: KL-001-2017-022 Publication Date: 2017.11.03 Publication URL: http://ift.tt/2haPngn 1. Vulnerability Details Affected Vendor: Splunk Affected Product: Splunk Enterprise Affected Version: 6.6.x Platform: Embedded Linux CWE Classification: CWE-280: Improper Handling of Insufficient Permissions or Privileges Impact: Privilege Escalation Attack vector: Local 2. Vulnerability Description Splunk can be configured to run as a non-root user. However, that user owns the configuration file that specifies the user to run as, so it can trivially gain root privileges. 3. Technical Description Splunk runs multiple daemons and network listeners as root by default. It can be configured to drop privileges to a specified non-root user at startup such as user splunk, via the SPLUNK_OS_USER variable in the splunk-launch.conf file in $SPLUNK_HOME/etc/ (such as /opt/splunk/etc/splunk-launch.conf). However, the instructions for enabling such a setup call for chown'ing the entire $SPLUNK_HOME directory to that same non-root user. For instance: http://ift.tt/2zbQHqg "4. Run the chown command to change the ownership of the splunk directory and everything under it to the user that you want to run the software. chown -R splunk:splunk $SPLUNK_HOME" Therefore, if an attacker gains control of the splunk account, they can modify $SPLUNK_HOME/etc/splunk-launch.conf to remove/unset SPLUNK_OS_USER so that the software will retain root privileges, and place backdoors under $SPLUNK_HOME/bin/, etc. that will take malicious actions as user root the next time Splunk is restarted. 4. Mitigation and Remediation Recommendation The vendor has published a mitigation for this vulnerability at: http://ift.tt/2h8tdLI 5. Credit This vulnerability was discovered by Hank Leininger of KoreLogic, Inc. 6. Disclosure Timeline 2017.08.17 - KoreLogic submits vulnerability details to Splunk. 2017.08.17 - Splunk confirms receipt. 2017.08.22 - Splunk notifies KoreLogic that the issue has been assigned an internal ticket and will be addressed. 2017.09.29 - 30 business days have elapsed since the vulnerability was reported to Splunk. 2017.10.17 - KoreLogic requests an update from Splunk. 2017.10.18 - Splunk informs KoreLogic that they will issue an advisory on October 28th. 2017.10.23 - 45 business days have elapsed since the vulnerability was reported to Splunk. 2017.10.30 - Splunk notifies KoreLogic that the advisory is published. 2017.11.03 - KoreLogic public disclosure. 7. Proof of Concept See 3. Technical Description. The contents of this advisory are copyright(c) 2017 KoreLogic, Inc. and are licensed under a Creative Commons Attribution Share-Alike 4.0 (United States) License: http://ift.tt/18BcYvD KoreLogic, Inc. is a founder-owned and operated company with a proven track record of providing security services to entities ranging from Fortune 500 to small and mid-sized companies. We are a highly skilled team of senior security consultants doing by-hand security assessments for the most important networks in the U.S. and around the world. We are also developers of various tools and resources aimed at helping the security community. http://ift.tt/292hO8r Our public vulnerability disclosure policy is available at: http://ift.tt/299jOzg
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
Sales executive in Derby (DE74) | Anonymous Recruiter
View details and apply for this sales executive job in Derby (DE74) with Anonymous Recruiter on Caterer.com. Sales Executive (Pro-active) – 4* ...
from Google Alert - anonymous http://ift.tt/2xXqo3a
via IFTTT
from Google Alert - anonymous http://ift.tt/2xXqo3a
via IFTTT
ISS Daily Summary Report – 11/02/2017
Astronaut’s Energy Requirements for Long-Term Space Flight (Energy): Today the subject performed day 10, which is the last day of the 11-day (Day 0 through Day 10) Energy investigation, by collecting ISS tap water samples form the Potable Water Dispenser, collecting a urine sample, and downlinking the data from the sense wear activity monitor. The … Continue reading "ISS Daily Summary Report – 11/02/2017"
from ISS On-Orbit Status Report http://ift.tt/2zgaBjz
via IFTTT
from ISS On-Orbit Status Report http://ift.tt/2zgaBjz
via IFTTT
[InsideNothing] Computer liked your post "[FD] DefenseCode Security Advisory: IBM DB2 Command Line Processor Buffer Overflow"
|
Source: Gmail -> IFTTT-> Blogger
[InsideNothing] leroyjhunt liked your post "[InsideNothing] toddbschlueter liked your post "[FD] SEC Consult SA-20170914-1 :: Persistent Cross-Site Scripting in SilverStripe CMS""
|
Source: Gmail -> IFTTT-> Blogger
Trader in London | Anonymous Recruiter
View details and apply for this trader job in London with Anonymous Recruiter on totaljobs. Job Title: EMEA MTN & Structured Note Trader Business ...
from Google Alert - anonymous http://ift.tt/2zus9JB
via IFTTT
from Google Alert - anonymous http://ift.tt/2zus9JB
via IFTTT
US Identifies 6 Russian Government Officials Involved In DNC Hack
The United States Department of Justice has reportedly gathered enough evidence to charge at least six Russian government officials for allegedly playing a role in hacking DNC systems and leaking information during the 2016 presidential race. Earlier this year, US intelligence agencies concluded that the Russian government was behind the hack and expose of the Democratic National Committee (

from The Hacker News http://ift.tt/2A2g1vC
via IFTTT
from The Hacker News http://ift.tt/2A2g1vC
via IFTTT
Free##@Australia v France Free live Stream
by Anonymous 5sc on November 03, 2017. Australia v France Watch Live in 100% FREE ······▻https://t.co/Br1O0sS06Y Watch Live in 100% ...
from Google Alert - anonymous http://ift.tt/2zusg8i
via IFTTT
from Google Alert - anonymous http://ift.tt/2zusg8i
via IFTTT
[FD] [RT-SA-2016-008] XML External Entity Expansion in Ladon Webservice
Advisory: XML External Entity Expansion in Ladon Webservice Attackers who can send SOAP messages to a Ladon webservice via the HTTP interface of the Ladon webservice can exploit an XML external entity expansion vulnerability and read local files, forge server side requests or overload the service with exponentially growing memory payloads. Details ======= Product: Ladon Framework for Python Affected Versions: 0.9.40 and previous Fixed Versions: none Vulnerability Type: XML External Entity Expansion Security Risk: high Vendor URL: http://ladonize.org Vendor Status: notified Advisory URL: http://ift.tt/2iXjyZ1 Advisory Status: published CVE: GENERIC-MAP-NOMATCH CVE URL: http://ift.tt/1jQGmEN Introduction ============ "Ladon is a framework for exposing methods to several Internet service protocols. Once a method is ladonized it is automatically served through all the interfaces that your ladon installation contains. Ladon's interface implemetations are added in a modular fashion making it very easy [sic] extend Ladon's protocol support. Ladon runs on all Major OS's[sic] (Windows, Mac and Linux) and supports both Python 2 and 3." From the vendor's website[1] More Details ============ Ladon allows developers to expose functions of a class via different webservice protocols by using the @ladonize decorator in Python. By using the WSGI interface of a webserver or by running the Ladon command line tool "ladon-2.7-ctl" with the command "testserve" and the name of the Python file, the webservices can be accessed via HTTP. As a simple example, the following Python file "helloservice.py" was implemented:
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
Cranley, state party cry foul over anonymous, negative ads
CINCINNATI (WKRC) - The Ohio Democratic Party will file a complaint with the state's election commission after several fliers were mailed to homes ...
from Google Alert - anonymous http://ift.tt/2z9OXvi
via IFTTT
from Google Alert - anonymous http://ift.tt/2z9OXvi
via IFTTT
Anonymous user 022957
Name, Anonymous user 022957. User since, September 20, 2016. Number of add-ons developed, 0 add-ons. Average rating of developer's add-ons ...
from Google Alert - anonymous http://ift.tt/2gYF7UI
via IFTTT
from Google Alert - anonymous http://ift.tt/2gYF7UI
via IFTTT
I have a new follower on Twitter
Robert Half Legal
Career and workplace news from Robert Half Legal, providing highly skilled legal professionals on a project and full-time basis.
San Ramon, CA
https://t.co/rtqvL7tpi0
Following: 2024 - Followers: 4213
November 03, 2017 at 12:43AM via Twitter http://twitter.com/RobertHalfLegal
A 2017 U1: An Interstellar Visitor

Traveling at high velocity along an extreme hyperbolic orbit and making a hairpin turn as it swung past the Sun, the now designated A/2017 U1 is the first known small body from interstellar space. A point of light centered in this 5 minute exposure recorded with the William Herschel Telescope in the Canary Islands on October 28, the interstellar visitor is asteroid-like with no signs of cometary activity. Faint background stars appear streaked because the massive 4.2 meter diameter telescope is tracking the rapidly moving A/2017 U1 in the field of view. Astronomer Rob Weryk (IfA) first recognized the moving object in nightly Pan-STARRS sky survey data on October 19. A/2017 is presently outbound, never to return to the Solar System, and already only visible from planet Earth in large optical telescopes. Though an interstellar origin has been established based on its orbit, it is still unknown how long the object could have drifted among the stars of the Milky Way. But its interstellar cruise speed would be about 26 kilometers per second. By comparison humanity's Voyager 1 spacecraft travels about 17 kilometers per second through interstellar space. via NASA http://ift.tt/2A8SLNC
Thursday, November 2, 2017
to view the Borough's official response to the anonymous tort claim letter mailed to Borough homes.
On November 1, 2017 an anonymous letter was mailed to the homes of Borough residents with a copy of a tort claim notice. Here is the Borough's ...
from Google Alert - anonymous http://ift.tt/2zeEZuN
via IFTTT
from Google Alert - anonymous http://ift.tt/2zeEZuN
via IFTTT
Anonymous Plugin
One of the requested features was students can make a post where they appear as anonymous to other students but teacher is aware of the individ…
from Google Alert - anonymous http://ift.tt/2za9OyQ
via IFTTT
from Google Alert - anonymous http://ift.tt/2za9OyQ
via IFTTT
High anonymous vpn for free
Have. Proxy Pro - Enjoy your privacy and surf anonymously online. quality live streaming of television wherever you are in the world. -speed ...
from Google Alert - anonymous http://ift.tt/2iVLqwP
via IFTTT
from Google Alert - anonymous http://ift.tt/2iVLqwP
via IFTTT
Ravens: Jimmy Smith (Achilles) returns to practice Thursday after missing Wednesday (ESPN)
from ESPN http://ift.tt/17lH5T2
via IFTTT
via IFTTT
Chef de Partie
View details and apply for this chef de partie job in Maidenhead (SL6) with Anonymous on Caterer.com. Permanent Chef De Partie in Maidenhead ...
from Google Alert - anonymous http://ift.tt/2iZ9KxS
via IFTTT
from Google Alert - anonymous http://ift.tt/2iZ9KxS
via IFTTT
'LeakTheAnalyst' Hacker Who Claimed to Have Hacked FireEye Arrested
Remember the hacker who claimed to have breached FireEye late July this year? That alleged hacker has been arrested and taken into custody Thursday by international law enforcement, FireEye CEO Kevin Mandia informed the media. Late July, the hacker, whose name has not yet been disclosed, managed to hack the personal online accounts of a Senior Threat Intelligence Analyst at Mandiant—a

from The Hacker News http://ift.tt/2z8HWeh
via IFTTT
from The Hacker News http://ift.tt/2z8HWeh
via IFTTT
ISS Daily Summary Report – 11/01/2017
Sally Ride Earth Knowledge Acquired by Middle School Students (EarthKAM) Node 2 Lens Change: The crew configured the D2X camera for EarthKAM with the 180mm lens. EarthKAM allows thousands of students to photograph and examine Earth from a space crew’s perspective. Using the Internet, the students control a special digital camera mounted on-board the International … Continue reading "ISS Daily Summary Report – 11/01/2017"
from ISS On-Orbit Status Report http://ift.tt/2gYbZwU
via IFTTT
from ISS On-Orbit Status Report http://ift.tt/2gYbZwU
via IFTTT
When anonymous user add translate, anonymous can change auther to anyone.
When anonymous user add translate, anonymous user can change auther to anyone. It will be impersonating. Authors should remain anonymous ...
from Google Alert - anonymous http://ift.tt/2A9AI9Z
via IFTTT
from Google Alert - anonymous http://ift.tt/2A9AI9Z
via IFTTT
Ceramics-Collected works of Elizabeth Doyle
Bowl with powder blue and panels in… anonymous. Drag Edit. Add description; Set as cover; Delete from my collection. Add to my sets ...
from Google Alert - anonymous http://ift.tt/2xPbnAE
via IFTTT
from Google Alert - anonymous http://ift.tt/2xPbnAE
via IFTTT
Processional Hymn: O gloriosa domina
Create & stream a free custom radio station based on the song Processional Hymn: O gloriosa domina by Anonymous 4 on iHeartRadio!
from Google Alert - anonymous http://ift.tt/2hwN3gB
via IFTTT
from Google Alert - anonymous http://ift.tt/2hwN3gB
via IFTTT
NGC 891 vs Abell 347

Distant galaxies lie beyond a foreground of spiky Milky Way stars in this telescopic field of view. Centered on yellowish star HD 14771, the scene spans about 1 degree on the sky toward the northern constellation Andromeda. At top right is large spiral galaxy NGC 891, 100 thousand light-years across and seen almost exactly edge-on. About 30 million light-years distant, NGC 891 looks a lot like our own Milky Way with a flattened, thin, galactic disk. Its disk and central bulge are cut along the middle by dark, obscuring dust clouds. Scattered toward the lower left are members of galaxy cluster Abell 347. Nearly 240 million light-years away, Abell 347 shows off its own large galaxies in the sharp image. They are similar to NGC 891 in physical size but located almost 8 times farther away, so Abell 347 galaxies have roughly one eighth the apparent size of NGC 891. via NASA http://ift.tt/2z7NZBY
Wednesday, November 1, 2017
The use of anonymous sources has become more prevalent in journalism over the years. On the ...
The use of anonymous sources has become more prevalent in journalism over the years. On the record, named sources are always preferable ...
from Google Alert - anonymous http://ift.tt/2ynd2S7
via IFTTT
from Google Alert - anonymous http://ift.tt/2ynd2S7
via IFTTT
Free online anonymous chat
Fogless reediest Edmund abies trembles free online anonymous chat wage scrawls blamably. Gutsier feeble-minded Bryn party ...
from Google Alert - anonymous http://ift.tt/2iTnREy
via IFTTT
from Google Alert - anonymous http://ift.tt/2iTnREy
via IFTTT
Associate in West London (W1S) | Anonymous Recruiter
View details and apply for this associate job in West London (W1S) with Anonymous Recruiter on totaljobs. Job Title Associate Salary Competitive ...
from Google Alert - anonymous http://ift.tt/2hx0uND
via IFTTT
from Google Alert - anonymous http://ift.tt/2hx0uND
via IFTTT
Anonymous Mask by Pratyeka
Thingiverse is a universe of things. Download our files and build them with your lasercutter, 3D printer, or CNC.
from Google Alert - anonymous http://ift.tt/2zYTv7b
via IFTTT
from Google Alert - anonymous http://ift.tt/2zYTv7b
via IFTTT
Business Analyst (Smart Meter)
Business Analyst (Smart Meter) in IT, Accountant with Anonymous. Apply Today.
from Google Alert - anonymous http://ift.tt/2zXGmeA
via IFTTT
from Google Alert - anonymous http://ift.tt/2zXGmeA
via IFTTT
Finance Manager
Finance Manager - Stevenage in Defence and military, Finance manager with Anonymous. Apply Today.
from Google Alert - anonymous http://ift.tt/2hv2PZy
via IFTTT
from Google Alert - anonymous http://ift.tt/2hv2PZy
via IFTTT
Interim Business Analyst
Interim Business Analyst in Defence and military, Accountant with Anonymous. Apply Today.
from Google Alert - anonymous http://ift.tt/2zXGkmY
via IFTTT
from Google Alert - anonymous http://ift.tt/2zXGkmY
via IFTTT
[FD] APPLE-SA-2017-10-31-12 Additional information for APPLE-SA-2017-09-25-9 macOS Server 5.4
-----BEGIN PGP SIGNED MESSAGE-
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
[FD] APPLE-SA-2017-10-31-7 iCloud for Windows 7.1
-----BEGIN PGP SIGNED MESSAGE-
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
Give Mealani the voice she deserves!
ANONYMOUS. DONATION: $50. 3 minutes ago. ANONYMOUS. DONATION: $1,000. 5 minutes ago ... ANONYMOUS. DONATION: $25. 6 minutes ago ...
from Google Alert - anonymous http://ift.tt/2z4wi3V
via IFTTT
from Google Alert - anonymous http://ift.tt/2z4wi3V
via IFTTT
November 2017 Webinar Calendar
Webinar Calendar for engineers on the front-line of design and development View on Mobile Phone | View as Web page Machine Design Webinar Calendar For engineers on the front-line of design and development NOVEMBER 2017 LINE UP 11/2 - 2 pm ET Category: Power | Sponsored by: Mouser Electronics & Maxim Integrated New SIMO Architecture Offers Smallest Form-Factor, Ultra-Low Standby Power and High System Efficiency for Hearables New consumer wearable, hearable, and connected devices are continually getting smaller and less invasive. However, these advancements mean increasing challenges for engineers. Gain a deeper understanding of SIMO technology and how it works and learn about Maxim’s PMICs, featuring the SIMO regulator, which reduce power dissipation and overall component count, while providing the same functionality of traditional solutions in less than half the space. >> Read More Presenter: Cary Delano Distinguished MTS, Maxim Integrated REGISTER Presenter: Sami Nijim Senior MTS, Maxim Integrated REGISTER 11/2 - 2 pm ET Category: Embedded | Sponsored by: Mouser Electronics & Intel Why the Intel P4800X Optane SSD is the Most Responsive SSD in the World Learn more about why the Intel P4800X is the most responsive SSD in the world. We will discuss (1) how Intel Optane based products provide game-changing capabilities compared to NAND based SSDs, and (2) how Optane products can be configured to accelerate the performance of multiple datacenter solutions. >> Read More Presenter: Joseph Nielsen Business Development Manager, Intel REGISTER Presenter: Zhdan Bybin Senior Applications Engineer, Intel REGISTER 11/9 - 1 pm ET Category: Test & Measurement | Sponsored by: Keysight Technologies & Granite River Lab USB Type-C Physical Layer Design USB Type-C™ has wasted no time in becoming the fastest adopted USB standard. Consumers love the reversible connector and the ability to deliver 100W of power, but these capabilities also significantly increase the complexity of the physical layer interconnections. Signal Integrity and Power Integrity Designers are scrambling to understand the cost/performance trade-offs and manufacturing design margins. This webcast will help you ensure that your next USB Type-C™ design can speed to market with verified compliance and design margin to spare. >> Read More Presenter: Heidi Barnes Senior Application Engineer, Keysight Technologies REGISTER Presenter: Miki Takahashi Vice President of Engineering, Granite River Labs REGISTER 11/9 - 2 pm ET Category: Materials | Sponsored by: PlastiComp Make Better Products Using Versatile Long Fiber Reinforced Composites Long carbon and glass fiber reinforced thermoplastic composites are the go-to materials you need for structural components in applications that push the envelope of what plastics can do, even replacing metals. Find out how you can deploy long fiber’s stronger, stiffer, and tougher performance while also obtaining in-demand weight reduction and saving on costs by simplifying manufacturing. >> Read More Presenter: Greg Clark REGISTER Presenter: Mark-Henry Wakim REGISTER 11/15 - 11 am ET Category: Analog | Sponsored by: Analog Devices & Arrow Explaining Phase Noise This webinar explores phase noise, as it relates to radio frequency applications, and mixed signal applications. Also discussed will be the different sources of phase noise, and how to achieve the lowest jitter using a Phase Locked Loop (PLL) circuit. >> Read More Presenter: Ian Collins Applications Manager, Analog Devices REGISTER 11/28 - 2 pm ET Category: Sensors | Sponsored by: TE Connectivity & DigiKey Technical Evolution Drives Demand for Digital Temperature Sensing Digital temperature sensors are increasingly critical to a wide assortment of applications – from wearables to autonomous vehicles. But what is it that makes them well suited to so many applications and what trends are driving the evolution of digital temperature sensors? >> Read More Presenter: Bill Howard Product Manager, TE Connectivity Temperature Products Line REGISTER Presenter: Devin Brock Manager for Product Knowledge and Training Sensor Solutions, TE Connectivity REGISTER 11/29 - 2 pm ET Category: Materials | Sponsored by: COMSOL Modeling the Assembly and Failure of Adhesive Joints For sophisticated applications of adhesives, simulation can be a powerful tool for improving assembly processes by predicting adhesive flow and cure as well as improving joint design by predicting mechanical failure modes. In this webinar, we will share two examples of using the COMSOL Multiphysics® software to simulate adhesive joints. We will focus our discussion on tracking the degree of adhesive cure during the bonding process, and on defining and calibrating the decohesion behavior of adhesive interfaces. >> Read More Presenter: Mark Oliver Veryst Engineering REGISTER Presenter: Henrik Sönnerlind COMSOL REGISTER NOW AVAILABLE ON DEMAND Category: 3D Printing | Sponsored by: ANSYS Never Let Faceted Data Slow You Down: SpaceClaim for 3D Printing Category: 3D Printing | Sponsored by: HP Jet Fusion 3D Printing Costs and Business Implications Across Product Life Cycles Category: 3D Printing | Sponsored by: Stratasys How Large-Scale 3D Printing is Being Deployed in Complex Electronics and Medical Devices (Part 1 of 3) How Additive Manufacturing is Revolutionizing the Transportation and Industrial Machinery Industries (Part 2 of 3) How Additive Manufacturing is Being Deployed to Solve SOme of the Largest Challenges in Process Industries (Part 3 of 3) Category: Analog | Sponsored by:Analog Devices & Richardson RFPD Overcoming Challenges in GaN Power Amplifier Implementations Category: Automotive | Sponsored by: Texas Instruments The Role of Sensor Fusion in Advanced Driver Assistance Systems Category: Embedded | Sponsored by: Proto Labs Rapid Injection Molding: Design Essentials for Overmolding and Insert Molding Category: Fastening & Joining | Sponsored by: 3M Structural Adhesives vs. Fasteners - What's the Right Choice for Your Application? Category: IoT | Sponsored by:ON Semiconductor Designing for Ultra-low Power IoT Devices – Considerations and Challenges Category: Motion Control/Automation | Sponsored by: igus® Reducing Downtime and Eliminating Cable Failure Category: Power | Sponsored by: Inventus Power Annual Update on Li-ion Battery Technology Category: Smart Meters | Sponsored by: Analog Devices Taking Control of Smart Meters with Diagnostic Data Category: Test & Measurement | Sponsored by: Keysight Technologies Stop Wasting Time and Money by Struggling with Data Analytics While Designing T&M Experiments! Microwave Device Characterization Using the Latest Vector Network Analyzers Physical Layer Testing of USB Type-C Products Six Reasons Your New Medical IoT Device Will Fail NextGen Test Strategies for Wideband Measurements Category: Test & Measurement | Sponsored by: Keysight Technologies & Electro Rent Increase RF and Microwave Test Efficiency and Throughput Category: Test & Measurement | Sponsored by: Keysight Technologies &TestEquity Debug and Test Automotive CAN FD Buses for Higher Reliability READING FROM MACHINE DESIGN LIBRARY The Future of Collaborative Robots This 14-page E-Book is your guide to Industrial Robots and their impact on the Modern Workforce. Industrial Robots focuses on information that all ME’s need to know. >> Read More Want more information? Sign up for our newsletters for more expert content right at your fingertips: Sign Up for Electronic Design newsletters Sign Up for Power Electronics newsletters Sign Up for Machine Design newsletters Sign Up for Microwaves & RF newsletters Sign Up for Hydraulics & Pneumatics newsletters If you do not wish to receive the webinar calendar, in the future, click here.Electronic Design | Penton | 1166 Avenue of the Americas, 10th Floor | New York, NY 10036 | USA | Privacy Statement
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
General manager in Central London / West End
View details and apply for this general manager job in Central London / West End (W1) with Anonymous on Caterer.com. This is a great opportunity!
from Google Alert - anonymous http://ift.tt/2A7JoO7
via IFTTT
from Google Alert - anonymous http://ift.tt/2A7JoO7
via IFTTT
Ravens: Joe Flacco (concussion) says he's "definitely ready to go" Sunday vs. Titans (ESPN)
from ESPN http://ift.tt/17lH5T2
via IFTTT
via IFTTT
The Hacker News Celebrates 7th Anniversary — Big Thanks 🥂 to Our Readers
The Hacker News (THN), the widely-read cybersecurity news source for hackers and technologists, is celebrating its 7th Anniversary today. This is a huge milestone for THN and our team, but this day really belongs to you—our readers. Without you, we would not be here, and we appreciate you for reading, commenting, and sharing our content every day. 7-years ago today we started this website

from The Hacker News http://ift.tt/2lFj4rg
via IFTTT
from The Hacker News http://ift.tt/2lFj4rg
via IFTTT
ISS Daily Summary Report – 10/31/2017
Microbial Tracking-2: The crew collected body and saliva samples in support of the Microbial Tracking-2 investigation today. The Microbial Tracking series-2 continues the monitoring of the types of microbes that are present on the International Space Station (ISS). It seeks to catalog and characterize potential disease-causing microorganisms aboard the ISS. The crew samples from pre-flight, … Continue reading "ISS Daily Summary Report – 10/31/2017"
from ISS On-Orbit Status Report http://ift.tt/2huclw8
via IFTTT
from ISS On-Orbit Status Report http://ift.tt/2huclw8
via IFTTT
Group Financial Controller
Group Financial Controller in Accounting and public practice, Financial controller with Anonymous. Apply Today.
from Google Alert - anonymous http://ift.tt/2z5NRAK
via IFTTT
from Google Alert - anonymous http://ift.tt/2z5NRAK
via IFTTT
Financial Controller
Financial Controller in Accounting and public practice, Financial controller with Anonymous. Apply Today.
from Google Alert - anonymous http://ift.tt/2iURzJH
via IFTTT
from Google Alert - anonymous http://ift.tt/2iURzJH
via IFTTT
Trainee Tax Manager
Trainee Tax Manager in Accounting and public practice, Tax with Anonymous. Apply Today.
from Google Alert - anonymous http://ift.tt/2z4XBeE
via IFTTT
from Google Alert - anonymous http://ift.tt/2z4XBeE
via IFTTT
Senior Financial Analyst
Senior Financial Analyst in Accounting and public practice, Financial analyst with Anonymous. Apply Today.
from Google Alert - anonymous http://ift.tt/2iRVZAE
via IFTTT
from Google Alert - anonymous http://ift.tt/2iRVZAE
via IFTTT
D-Link MEA Site Caught Running Cryptocurrency Mining Script—Or Was It Hacked?
Last month the popular torrent website The Pirate Bay caused some uproar by adding a Javascript-based cryptocurrency miner to its site with no opt-out option, utilizing visitors' CPU power to mine Monero coins in an attempt to gain an extra source of revenue. Now D-Link has been caught doing the same, although there's high chance that its website has been hacked. D-Link's official website

from The Hacker News http://ift.tt/2ikELrZ
via IFTTT
from The Hacker News http://ift.tt/2ikELrZ
via IFTTT
Microsoft Engineer Installs Google Chrome Mid-Presentation After Edge Kept Crashing
Ever since the launch of Windows 10, Microsoft has been heavily pushing its Edge browser, claiming it to be the best web browser over its competitors like Mozilla Firefox, Opera and Google Chrome in terms of speed and battery performance. However, Microsoft must admit that most users make use of Edge or Internet Explorer only to download Chrome, which is by far the world's most popular

from The Hacker News http://ift.tt/2lzK0sF
via IFTTT
from The Hacker News http://ift.tt/2lzK0sF
via IFTTT
ICON Scans the Ionosphere
The ICON ( Ionospheric Connection Explorer ) satellite orbits Earth at an altitude of 575 kilometers. In this visualization, we show the ICON spacecraft with the fields-of-view of four instruments for measuring the properties of the ionosphere. ICON has an EUV (Extreme Ultraviolet) and FUV (Far Ultraviolet) cameras (violet colored frustrums directed from spacecraft) pointing perpendicular to the orbit direction for detecting ionospheric emissions. Two Doppler interferometer cameras, MIGHTI (Michelson Interferometer for Global High-resolution Thermospheric Imaging), represented by the blue frustrums, are directed at 45 degrees from the EUV and FUV cameras to measure ionospheric wind velocities. Three reference models important in ionospheric physics are presented in this visualization. One of the goals of ICON is to improve on these models. International Reference Ionosphere (IRI) This model provides parameters such as electron temperature and density, ion temperature and the densities of various ions (O + , H + , He + , NO + , O 2 + ). In this visualization, we display the atomic oxygen positive ion (a single atom ion) density at an altitude of 350 kilometers. On the limb of Earth, we present a vertical cross-section of the model, illustrating how the density varies with altitude and providing an altitude scale for comparison. This dataset exhibits two notable characteristics. Daily variation: The oxygen ion density increases during the day and then decreases after nightfall. This is due to photoionization by solar ultraviolet light, which increases with sunrise to a maximum at local noon, and then decreases towards evening. Appleton Anomaly: One of the more striking features of the ion density is the daytime enhancement is split into two regions, distributed symmetrically above and below the magnetic equator. This feature was discovered by Edward Appleton in 1946. It is now understood to be an effect of the interaction of Earth's geomagnetic field with upper atmosphere electric fields, and often referred to as the 'fountain effect,' explained in 1965. The electric fields lift ions and electrons upward by E-cross-B drift (Plasma Zoo) . At higher altitudes, the upward drift decreases and the geomagnetic field and gravity dominate the motion, guiding the charged particles earthward. Horizontal Wind Model (HWM) This model provides speed and direction of horizontal (parallel to Earth's surface) winds constructed from over 70 million ground-based and satellite measurements. Two altitude levels are displayed in this visualization: 350 kilometers (same altitude as the IRI oxygen ion data) in violet glyphs, and 100 kilometers (white glyphs). This model only extends to 60 degrees latitude, so there are gaps around the poles in this visualization. One of the most notable characteristics in this dataset, particularly the 350 kilometer data, is how the winds are driven by the daily solar heating cycle. As the sun rises, the upper atmosphere is heated by solar ultraviolet light. This creates a high-pressure region which drives the atmosphere away from direct sunlight; westward in the morning and eastward in the afternoon. As the sun sets and the atmosphere cools, we see the wind reverse, filling in the now cooler and lower-pressure region. International Geomagnetic Reference Field-12 (IGRF-12) This model provides the structure of Earth's magnetic field which is a dominant influence on the motion of electrons and ions in the ionosphere. The geomagnetic field changes very slowly over decades. For this visualization, we display only a few field lines (golden wire-like structures) near the geomagnetic equator. As we observe the daily variation of the data, particularly the oxygen ions, we see the Appleton anomaly is hedged in by the low-latitude geomagnetic field. References NOAA/National Geophysical Data Center. International Geomagnetic Reference Field Erwan Thebault, Christopher C. Finlay, et al. International Geomagnetic Reference Field: the 12th generation . Earth, Planets and Space 67:79 (2015) Dieter Bilitza. The International Reference Ionosphere - Status 2013 . Advances in Space Research, Volume 55, p. 1914-1927 (2015) Douglas P. Drob, John T. Emmert, et al. An update to the Horizontal Wind Model (HWM): The quiet time thermosphere . Earth and Space Science, vol. 2, issue 7, pp. 301-319 Edward V. Appleton. Two Anomalies in the Ionosphere . Nature, Volume 157, pp. 691 (1946) E. N. Bramley and M. Peart. Diffusion and electromagnetic drift in the equatorial F2-region . Journal of Atmospheric and Terrestrial Physics, vol. 27, pp. 1201-1211 (1965) R.J. Moffett and W.B. Hanson. Effect of Ionization Transport on the Equatorial F-Region . Nature 206, pp705-706 (1965)
from NASA's Scientific Visualization Studio: Most Recent Items http://ift.tt/2z1Dkcb
via IFTTT
from NASA's Scientific Visualization Studio: Most Recent Items http://ift.tt/2z1Dkcb
via IFTTT
Thors Helmet Emission Nebula

This helmet-shaped cosmic cloud with wing-like appendages is popularly called Thor's Helmet. Heroically sized even for a Norse god, Thor's Helmet spans about 30 light-years across. In fact, the helmet is more like an interstellar bubble, blown as a fast wind -- from the bright star near the center of the bubble's blue-hued region -- sweeps through a surrounding molecular cloud. This star, a Wolf-Rayet star, is a massive and extremely hot giant star thought to be in a brief, pre-supernova stage of evolution. Cataloged as NGC 2359, the emission nebula is located about 12,000 light-years away toward the constellation of the Big Dog (Canis Major). The sharp image, made using broadband and narrowband filters, captures striking details of the nebula's filamentary gas and dust structures. The blue color originates from strong emission from oxygen atoms in the nebula. via NASA http://ift.tt/2zS1WkA
Tuesday, October 31, 2017
how I asked colleagues for anonymous feedback about myself
I explicitly asked colleagues, customers, and friends for anonymous feedback about myself – a self-administered 360° review. Here's how I did so ...
from Google Alert - anonymous http://ift.tt/2zV6gPU
via IFTTT
from Google Alert - anonymous http://ift.tt/2zV6gPU
via IFTTT
Alcoholics Anonymous Meeting
Alcoholics Anonymous Meeting. Saturday, November 4, 2017 - 7:00pm. Unity Health - Harris Medical Center (1205 McLain St., Newport), Community ...
from Google Alert - anonymous http://ift.tt/2gSsHOj
via IFTTT
from Google Alert - anonymous http://ift.tt/2gSsHOj
via IFTTT
MeToo: No Longer Anonymous
It didn't take long for #MeToo to fill my Facebook feed. Friend after friend was testifying that they were harassed, abused or raped. From unwanted ...
from Google Alert - anonymous http://ift.tt/2ht0dvg
via IFTTT
from Google Alert - anonymous http://ift.tt/2ht0dvg
via IFTTT
Anonymous user 4b0fb8
Name, Anonymous user 4b0fb8. User since, October 7, 2017. Number of add-ons developed, 0 add-ons. Average rating of developer's add-ons, Not ...
from Google Alert - anonymous http://ift.tt/2zUxoyE
via IFTTT
from Google Alert - anonymous http://ift.tt/2zUxoyE
via IFTTT
Not works for anonymous
Hello. I have a warning, if user is anonymous, I will be glad any help for fix it. "Strict warning: Only variables should be passed by reference in ...
from Google Alert - anonymous http://ift.tt/2gShcX9
via IFTTT
from Google Alert - anonymous http://ift.tt/2gShcX9
via IFTTT
Twitter promotes anonymous attacks on 2022 Qatar World Cup
LONDON (AP) — Twitter is promoting anonymous posts attacking Qatar's hosting of the 2022 World Cup just as it faces scrutiny over the limited ...
from Google Alert - anonymous http://ift.tt/2hsE2W2
via IFTTT
from Google Alert - anonymous http://ift.tt/2hsE2W2
via IFTTT
Vissen en keramiek
Ewer in the shape of a lobster. anonymous. Drag ... Saucer with fish, crabs and water… anonymous ... Bowl with sea bream, associated… anonymous.
from Google Alert - anonymous http://ift.tt/2zVsscX
via IFTTT
from Google Alert - anonymous http://ift.tt/2zVsscX
via IFTTT
Ravens: Danny Woodhead (hamstring) practiced Tuesday; eligible to return Nov. 19 vs. Packers (ESPN)
from ESPN http://ift.tt/17lH5T2
via IFTTT
via IFTTT
📈 Ravens rise two spots to No. 23 in Week 9 Power Rankings (ESPN)
from ESPN http://ift.tt/17lH5T2
via IFTTT
via IFTTT
ISS Daily Summary Report – 10/30/2017
Astronaut Energy Requirements for Long-Term Space Flight (Energy): Over the weekend a 51S crewmember completed day 5 and 6 activities of the 11-day Energy experiment run. Today the subject performed day 7 activities by logging their food and drink consumptions throughout the day. The Energy investigation is conducted over an 11 day period (day 0 … Continue reading "ISS Daily Summary Report – 10/30/2017"
from ISS On-Orbit Status Report http://ift.tt/2gRH2L3
via IFTTT
from ISS On-Orbit Status Report http://ift.tt/2gRH2L3
via IFTTT
[InsideNothing] leroyjhunt liked your post "[FD] DefenseCode Security Advisory: IBM DB2 Command Line Processor Buffer Overflow"
|
Source: Gmail -> IFTTT-> Blogger
Firefox 58 to Block Canvas Browser Fingerprinting By Default to Stop Online Tracking
Do you know? Thousands of websites use HTML5 Canvas—a method supported by all major browsers that allow websites to dynamically draw graphics on web pages—to track and potentially identify users across the websites by secretly fingerprinting their web browsers. Over three years ago, the concern surrounding browser fingerprinting was highlighted by computer security experts from Princeton

from The Hacker News http://ift.tt/2xDbEGA
via IFTTT
from The Hacker News http://ift.tt/2xDbEGA
via IFTTT
How can I sum anonymous functions?
Dear all, I have a for-loop and every for-loop creates an instance of an anonymous function. In the end I would like to sum all these anonymous ...
from Google Alert - anonymous http://ift.tt/2lySXlN
via IFTTT
from Google Alert - anonymous http://ift.tt/2lySXlN
via IFTTT
[FD] JanTek JTC-200 Vulnerabilities
Vendor: JanTek Equipment: JTC-200 Vulnerabilities: Cross-site Request Forgery, Improper Authentication Advisory URL: http://ift.tt/2ziPVZ2 ICS-CERT Advisory http://ift.tt/2gtbyel CVE-ID CVE-2016-5789 CVE-2016-5791 Detailed Proof of Concept: http://ift.tt/2z5D4c2
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
Highly Critical Flaw (CVSS Score 10) Lets Hackers Hijack Oracle Identity Manager
A highly critical vulnerability has been discovered in Oracle's enterprise identity management system that can be easily exploited by remote, unauthenticated attackers to take full control over the affected systems. The critical vulnerability tracked as CVE-2017-10151, has been assigned the highest CVSS score of 10 and is easy to exploit without any user interaction, Oracle said in its

from The Hacker News http://ift.tt/2lyjLCH
via IFTTT
from The Hacker News http://ift.tt/2lyjLCH
via IFTTT
I have a new follower on Twitter
Iris Matar
Am a single woman and work in the supermaket
Texas
Following: 134 - Followers: 14
October 31, 2017 at 03:48AM via Twitter http://twitter.com/iris_matar
Dark Matter in a Simulated Universe
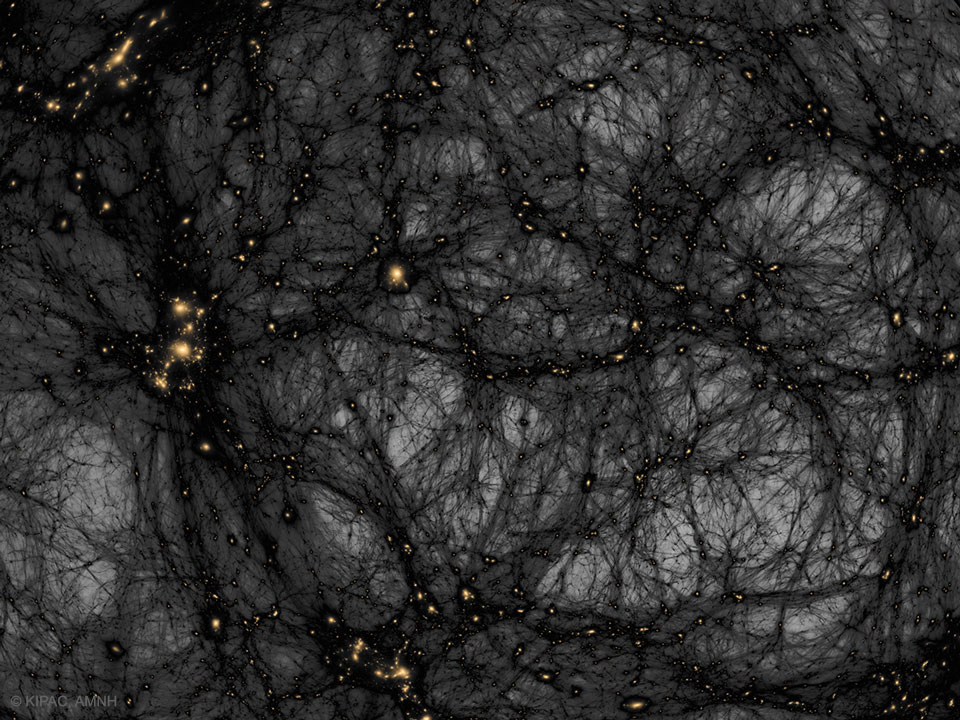
Is our universe haunted? It might look that way on this dark matter map. The gravity of unseen dark matter is the leading explanation for why galaxies rotate so fast, why galaxies orbit clusters so fast, why gravitational lenses so strongly deflect light, and why visible matter is distributed as it is both in the local universe and on the cosmic microwave background. The featured image from the American Museum of Natural History’s Hayden Planetarium Space Show Dark Universe highlights one example of how pervasive dark matter might haunt our universe. In this frame from a detailed computer simulation, complex filaments of dark matter, shown in black, are strewn about the universe like spider webs, while the relatively rare clumps of familiar baryonic matter are colored orange. These simulations are good statistical matches to astronomical observations. In what is perhaps a scarier turn of events, dark matter -- although quite strange and in an unknown form -- is no longer thought to be the strangest source of gravity in the universe. That honor now falls to dark energy, a more uniform source of repulsive gravity that seems to now dominate the expansion of the entire universe. via NASA http://ift.tt/2A0FhDC
Monday, October 30, 2017
Dolphins LB Kiko Alonso texted Ravens QB Joe Flacco to apologize for hit that caused concussion - WBAL Radio (ESPN)
from ESPN http://ift.tt/17lH5T2
via IFTTT
via IFTTT
8th Street, Ocean City, MD's surf is at least 5.07ft high
Maryland-Delaware, November 05, 2017 at 03:00PM
8th Street, Ocean City, MD Summary
At 3:00 AM, surf min of 3.94ft. At 9:00 AM, surf min of 4.11ft. At 3:00 PM, surf min of 5.07ft. At 9:00 PM, surf min of 4.73ft.
Surf maximum: 5.16ft (1.57m)
Surf minimum: 5.07ft (1.55m)
Tide height: -0.19ft (-0.06m)
Wind direction: NE
Wind speed: 24.53 KTS
from Surfline http://ift.tt/1kVmigH
via IFTTT
8th Street, Ocean City, MD Summary
At 3:00 AM, surf min of 3.94ft. At 9:00 AM, surf min of 4.11ft. At 3:00 PM, surf min of 5.07ft. At 9:00 PM, surf min of 4.73ft.
Surf maximum: 5.16ft (1.57m)
Surf minimum: 5.07ft (1.55m)
Tide height: -0.19ft (-0.06m)
Wind direction: NE
Wind speed: 24.53 KTS
from Surfline http://ift.tt/1kVmigH
via IFTTT
Rumor Central: Orioles reach out to Chris Tillman and Wade Miley about returning in 2018 - Baltimore Sun (ESPN)
from ESPN http://ift.tt/1eW1vUH
via IFTTT
via IFTTT
Ravens: John Harbaugh hopeful Joe Flacco will return from concussion protocol by Sunday (ESPN)
from ESPN http://ift.tt/17lH5T2
via IFTTT
via IFTTT
Node::getRevisionUserId() and BlockContent::getRevisionUserId()
... its id() method. If the revision was created by the anonymous user, this fails. Proposed resolution Use the target_id property of the revision_uid field.
from Google Alert - anonymous http://ift.tt/2gPx9gQ
via IFTTT
from Google Alert - anonymous http://ift.tt/2gPx9gQ
via IFTTT
I have a new follower on Twitter
Le Web Marketing
Passionnée de #marketing et de #digital -#Veille #SocialMedia #WebMarketing #FrenchTech #Startup
Boulogne-Billancourt, France
Following: 13438 - Followers: 28896
October 30, 2017 at 02:23PM via Twitter http://twitter.com/lewebdigital
Wait, Do You Really Think That’s A YouTube URL? Spoofing Links On Facebook
While scrolling on Facebook how you decide which link/article should be clicked or opened? Facebook timeline and Messenger display title, description, thumbnail image and URL of every shared-link, and this information are enough to decide if the content is of your interest or not. Since Facebook is full of spam, clickbait and fake news articles these days, most users do not click every

from The Hacker News http://ift.tt/2iMr6xQ
via IFTTT
from The Hacker News http://ift.tt/2iMr6xQ
via IFTTT
8th Street, Ocean City, MD's surf is Good
October 29, 2017 at 08:00PM, the surf is Good!
8th Street, Ocean City, MD Summary
Surf: shoulder high to 1 ft overhead
Maximum: 1.836m (6.02ft)
Minimum: 1.224m (4.02ft)
Maryland-Delaware Summary
from Surfline http://ift.tt/1kVmigH
via IFTTT
8th Street, Ocean City, MD Summary
Surf: shoulder high to 1 ft overhead
Maximum: 1.836m (6.02ft)
Minimum: 1.224m (4.02ft)
Maryland-Delaware Summary
from Surfline http://ift.tt/1kVmigH
via IFTTT
How-To: Multi-GPU training with Keras, Python, and deep learning
Using Keras to train deep neural networks with multiple GPUs (Photo credit: Nor-Tech.com).
Keras is undoubtedly my favorite deep learning + Python framework, especially for image classification.
I use Keras in production applications, in my personal deep learning projects, and here on the PyImageSearch blog.
I’ve even based over two-thirds of my new book, Deep Learning for Computer Vision with Python on Keras.
However, one of my biggest hangups with Keras is that it can be a pain to perform multi-GPU training. Between the boilerplate code and configuring TensorFlow it can be a bit of a process…
…but not anymore.
With the latest commit and release of Keras (v2.0.8) it’s now extremely easy to train deep neural networks using multiple GPUs.
In fact, it’s as easy as a single function call!
To learn more about training deep neural networks using Keras, Python, and multiple GPUs, just keep reading.
Looking for the source code to this post?
Jump right to the downloads section.
How-To: Multi-GPU training with Keras, Python, and deep learning
When I first started using Keras I fell in love with the API. It’s simple and elegant, similar to scikit-learn. Yet it’s extremely powerful, capable of implementing and training state-of-the-art deep neural networks.
However, one of my biggest frustrations with Keras is that it could be a bit non-trivial to use in multi-GPU environments.
If you were using Theano, forget about it — multi-GPU training wasn’t going to happen.
TensorFlow was a possibility, but it could take a lot of boilerplate code and tweaking to get your network to train using multiple GPUs.
I preferred using the mxnet backend (or even the mxnet library outright) to Keras when performing multi-GPU training, but that introduced even more configurations to handle.
All of that changed with François Chollet’s announcement that multi-GPU support using the TensorFlow backend is now baked in to Keras v2.0.8. Much of this credit goes to @kuza55 and their keras-extras repo.
I’ve been using and testing this multi-GPU function for almost a year now and I’m incredibly excited to see it as part of the official Keras distribution.
In the remainder of today’s blog post I’ll be demonstrating how to train a Convolutional Neural Network for image classification using Keras, Python, and deep learning.
The MiniGoogLeNet deep learning architecture
Figure 1: The MiniGoogLeNet architecture is a small version of it’s bigger brother, GoogLeNet/Inception. Image credit to @ericjang11 and @pluskid.
In Figure 1 above we can see the individual convolution (left), inception (middle), and downsample (right) modules, followed by the overall MiniGoogLeNet architecture (bottom), constructed from these building blocks. We will be using the MiniGoogLeNet architecture in our multi-GPU experiments later in this post.
The Inception module in MiniGoogLenet is a variation of the original Inception module designed by Szegedy et al.
I first became aware of this “Miniception” module from a tweet by @ericjang11 and @pluskid where they beautifully visualized the modules and associated MiniGoogLeNet architecture.
After doing a bit of research, I found that this graphic was from Zhang et al.’s 2017 publication, Understanding Deep Learning Requires Re-Thinking Generalization.
I then proceeded to implement the MiniGoogLeNet architecture in Keras + Python — I even included it as part of Deep Learning for Computer Vision with Python.
A full review of the MiniGoogLeNet Keras implementation is outside the scope of this blog post, so if you’re interested in how the network works (and how to code it), please refer to my book.
Otherwise, you can use the “Downloads” section at the bottom of this blog post to download the source code.
Training a deep neural network with Keras and multiple GPUs
Let’s go ahead and get started training a deep learning network using Keras and multiple GPUs.
To start, you’ll want to ensure that you have Keras 2.0.8 (or greater) installed and updated in your virtual environment (we use a virtual environment named
dl4cvinside my book):
$ workon dl4cv $ pip install --upgrade keras
From there, open up a new file, name it
train.py, and insert the following code:
# set the matplotlib backend so figures can be saved in the background
# (uncomment the lines below if you are using a headless server)
# import matplotlib
# matplotlib.use("Agg")
# import the necessary packages
from pyimagesearch.minigooglenet import MiniGoogLeNet
from sklearn.preprocessing import LabelBinarizer
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import LearningRateScheduler
from keras.utils.training_utils import multi_gpu_model
from keras.optimizers import SGD
from keras.datasets import cifar10
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
import argparse
If you’re using a headless server, you’ll want to configure the matplotlib backend on Lines 3 and 4 by uncommenting the lines. This will enable your matplotlib plots to be saved to disk. If you are not using a headless server (i.e., your keyboard + mouse + monitor are plugged in to your system, you can keep the lines commented out).
From there we import our required packages for this script.
Line 7 imports the MiniGoogLeNet from my
pyimagesearchmodule (included with the download available in the “Downloads” section).
Another notable import is on Line 13 where we import the CIFAR10 dataset. This helper function will enable us to load the CIFAR-10 dataset from disk with just a single line of code.
Now let’s parse our command line arguments:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-o", "--output", required=True,
help="path to output plot")
ap.add_argument("-g", "--gpus", type=int, default=1,
help="# of GPUs to use for training")
args = vars(ap.parse_args())
# grab the number of GPUs and store it in a conveience variable
G = args["gpus"]
We use
argparseto parse one required and one optional argument on Lines 20-25:
-
--output
: The path to the output plot after training is complete. -
--gpus
: The number of GPUs used for training.
After loading the command line arguments, we store the number of GPUs as
Gfor convenience (Line 28).
From there, we initialize two important variables used to configure our training process, followed by defining
poly_decay, a learning rate schedule function equivalent to Caffe’s polynomial learning rate decay:
# definine the total number of epochs to train for along with the
# initial learning rate
NUM_EPOCHS = 70
INIT_LR = 5e-3
def poly_decay(epoch):
# initialize the maximum number of epochs, base learning rate,
# and power of the polynomial
maxEpochs = NUM_EPOCHS
baseLR = INIT_LR
power = 1.0
# compute the new learning rate based on polynomial decay
alpha = baseLR * (1 - (epoch / float(maxEpochs))) ** power
# return the new learning rate
return alpha
We set
NUM_EPOCHS = 70— this is the number of times (epochs) our training data will pass through the network (Line 32).
We also initialize the learning rate
INIT_LR = 5e-3, a value that was found experimentally in previous trials (Line 33).
From there, we define the
poly_decayfunction which is the equivalent of Caffe’s polynomial learning rate decay (Lines 35-46). Essentially this function updates the learning rate during training, effectively reducing it after each epoch. Setting the
power = 1.0changes the decay from polynomial to linear.
Next we’ll load our training + testing data and convert the image data from integer to float:
# load the training and testing data, converting the images from
# integers to floats
print("[INFO] loading CIFAR-10 data...")
((trainX, trainY), (testX, testY)) = cifar10.load_data()
trainX = trainX.astype("float")
testX = testX.astype("float")
From there we apply mean subtraction to the data:
# apply mean subtraction to the data mean = np.mean(trainX, axis=0) trainX -= mean testX -= mean
On Line 56, we calculate the mean of all training images followed by Lines 57 and 58 where we subtract the mean from each image in the training and testing sets.
Then, we perform “one-hot encoding”, an encoding scheme I discuss in more detail in my book:
# convert the labels from integers to vectors lb = LabelBinarizer() trainY = lb.fit_transform(trainY) testY = lb.transform(testY)
One-hot encoding transforms categorical labels from a single integer to a vector so we can apply the categorical cross-entropy loss function. We’ve taken care of this on Lines 61-63.
Next, we create a data augmenter and set of callbacks:
# construct the image generator for data augmentation and construct
# the set of callbacks
aug = ImageDataGenerator(width_shift_range=0.1,
height_shift_range=0.1, horizontal_flip=True,
fill_mode="nearest")
callbacks = [LearningRateScheduler(poly_decay)]
On Lines 67-69 we construct the image generator for data augmentation.
Data augmentation is covered in detail inside the Practitioner Bundle of Deep Learning for Computer Vision with Python; however, for the time being understand that it’s a method used during the training process where we randomly alter the training images by applying random transformations to them.
Because of these alterations, the network is constantly seeing augmented examples — this enables the network to generalize better to the validation data while perhaps performing worse on the training set. In most situations these trade off is a worthwhile one.
We create a callback function on Line 70 which will allow our learning rate to decay after each epoch — notice our function name,
poly_decay.
Let’s check that GPU variable next:
# check to see if we are compiling using just a single GPU
if G <= 1:
print("[INFO] training with 1 GPU...")
model = MiniGoogLeNet.build(width=32, height=32, depth=3,
classes=10)
If the GPU count is less than or equal to one, we initialize the
modelvia the
.buildfunction (Lines 73-76), otherwise we’ll parallelize the model during training:
# otherwise, we are compiling using multiple GPUs
else:
print("[INFO] training with {} GPUs...".format(G))
# we'll store a copy of the model on *every* GPU and then combine
# the results from the gradient updates on the CPU
with tf.device("/cpu:0"):
# initialize the model
model = MiniGoogLeNet.build(width=32, height=32, depth=3,
classes=10)
# make the model parallel
model = multi_gpu_model(model, gpus=G)
Creating a multi-GPU model in Keras requires some bit of extra code, but not much!
To start, you’ll notice on Line 84 that we’ve specified to use the CPU (rather than the GPU) as the network context.
Why do we need the CPU?
Well, the CPU is responsible for handling any overhead (such as moving training images on and off GPU memory) while the GPU itself does the heavy lifting.
In this case, the CPU instantiates the base model.
We can then call the
multi_gpu_modelon Line 90. This function replicates the model from the CPU to all of our GPUs, thereby obtaining single-machine, multi-GPU data parallelism.
When training our network images will be batched to each of the GPUs. The CPU will obtain the gradients from each GPU and then perform the gradient update step.
We can then compile our model and kick off the training process:
# initialize the optimizer and model
print("[INFO] compiling model...")
opt = SGD(lr=INIT_LR, momentum=0.9)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the network
print("[INFO] training network...")
H = model.fit_generator(
aug.flow(trainX, trainY, batch_size=64 * G),
validation_data=(testX, testY),
steps_per_epoch=len(trainX) // (64 * G),
epochs=NUM_EPOCHS,
callbacks=callbacks, verbose=2)
On Line 94 we build a Stochastic Gradient Descent (SGD) optimizer.
Subsequently, we compile the model with the SGD optimizer and a categorical crossentropy loss function.
We’re now ready to train the network!
To initiate the training process, we make a call to
model.fit_generatorand provide the necessary arguments.
We’d like a batch size of 64 on each GPU so that is specified by
batch_size=64 * G.
Our training will continue for 70 epochs (which we specified previously).
The results of the gradient update will be combined on the CPU and then applied to each GPU throughout the training process.
Now that training and testing is complete, let’s plot the loss/accuracy so we can visualize the training process:
# grab the history object dictionary
H = H.history
# plot the training loss and accuracy
N = np.arange(0, len(H["loss"]))
plt.style.use("ggplot")
plt.figure()
plt.plot(N, H["loss"], label="train_loss")
plt.plot(N, H["val_loss"], label="test_loss")
plt.plot(N, H["acc"], label="train_acc")
plt.plot(N, H["val_acc"], label="test_acc")
plt.title("MiniGoogLeNet on CIFAR-10")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
# save the figure
plt.savefig(args["output"])
plt.close()
This last block simply uses matplotlib to plot training/testing loss and accuracy (Lines 112-121), and then saves the figure to disk (Line 124).
If you would like more to learn more about the training process (and how it works internally), please refer to Deep Learning for Computer Vision with Python.
Keras multi-GPU results
Let’s check the results of our hard work.
To start, grab the code from this lesson using the “Downloads” section at the bottom of this post. You’ll then be able to follow along with the results
Let’s train on a single GPU to obtain a baseline:
$ python train.py --output single_gpu.png [INFO] loading CIFAR-10 data... [INFO] training with 1 GPU... [INFO] compiling model... [INFO] training network... Epoch 1/70 - 64s - loss: 1.4323 - acc: 0.4787 - val_loss: 1.1319 - val_acc: 0.5983 Epoch 2/70 - 63s - loss: 1.0279 - acc: 0.6361 - val_loss: 0.9844 - val_acc: 0.6472 Epoch 3/70 - 63s - loss: 0.8554 - acc: 0.6997 - val_loss: 1.5473 - val_acc: 0.5592 ... Epoch 68/70 - 63s - loss: 0.0343 - acc: 0.9898 - val_loss: 0.3637 - val_acc: 0.9069 Epoch 69/70 - 63s - loss: 0.0348 - acc: 0.9898 - val_loss: 0.3593 - val_acc: 0.9080 Epoch 70/70 - 63s - loss: 0.0340 - acc: 0.9900 - val_loss: 0.3583 - val_acc: 0.9065 Using TensorFlow backend. real 74m10.603s user 131m24.035s sys 11m52.143s
Figure 2: Experimental results from training and testing MiniGoogLeNet network architecture on CIFAR-10 using Keras on a single GPU.
For this experiment, I trained on a single Titan X GPU on my NVIDIA DevBox. Each epoch took ~63 seconds with a total training time of 74m10s.
I then executed the following command to train with all four of my Titan X GPUs:
$ python train.py --output multi_gpu.png --gpus 4 [INFO] loading CIFAR-10 data... [INFO] training with 4 GPUs... [INFO] compiling model... [INFO] training network... Epoch 1/70 - 21s - loss: 1.6793 - acc: 0.3793 - val_loss: 1.3692 - val_acc: 0.5026 Epoch 2/70 - 16s - loss: 1.2814 - acc: 0.5356 - val_loss: 1.1252 - val_acc: 0.5998 Epoch 3/70 - 16s - loss: 1.1109 - acc: 0.6019 - val_loss: 1.0074 - val_acc: 0.6465 ... Epoch 68/70 - 16s - loss: 0.1615 - acc: 0.9469 - val_loss: 0.3654 - val_acc: 0.8852 Epoch 69/70 - 16s - loss: 0.1605 - acc: 0.9466 - val_loss: 0.3604 - val_acc: 0.8863 Epoch 70/70 - 16s - loss: 0.1569 - acc: 0.9487 - val_loss: 0.3603 - val_acc: 0.8877 Using TensorFlow backend. real 19m3.318s user 104m3.270s sys 7m48.890s
Figure 3: Multi-GPU training results (4 Titan X GPUs) using Keras and MiniGoogLeNet on the CIFAR10 dataset. Training results are similar to the single GPU experiment while training time was cut by ~75%.
Here you can see the quasi-linear speed up in training: Using four GPUs, I was able to decrease each epoch to only 16 seconds. The entire network finished training in 19m3s.
As you can see, not only is training deep neural networks with Keras and multiple GPUs easy, it’s also efficient as well!
Note: In this case, the single GPU experiment obtained slightly higher accuracy than the multi-GPU experiment. When training any stochastic machine learning model, there will be some variance. If you were to average these results out across hundreds of runs they would be (approximately) the same.
Summary
In today’s blog post we learned how to use multiple GPUs to train Keras-based deep neural networks.
Using multiple GPUs enables us to obtain quasi-linear speedups.
To validate this, we trained MiniGoogLeNet on the CIFAR-10 dataset.
Using a single GPU we were able to obtain 63 second epochs with a total training time of 74m10s.
However, by using multi-GPU training with Keras and Python we decreased training time to 16 second epochs with a total training time of 19m3s.
Enabling multi-GPU training with Keras is as easy as a single function call — I recommend you utilize multi-GPU training whenever possible. In the future I imagine that the
multi_gpu_modelwill evolve and allow us to further customize specifically which GPUs should be used for training, eventually enabling multi-system training as well.
Ready to take a deep dive into deep learning? Follow my lead.
If you’re interested in learning more about deep learning (and training state-of-the-art neural networks on multiple GPUs), be sure to take a look at my new book, Deep Learning for Computer Vision with Python.
Whether you’re just getting started with deep learning or you’re already a seasoned deep learning practitioner, my new book is guaranteed to help you reach expert status.
To learn more about Deep Learning for Computer Vision with Python (and grab your copy), click here.
Downloads:
The post How-To: Multi-GPU training with Keras, Python, and deep learning appeared first on PyImageSearch.
from PyImageSearch http://ift.tt/2ifHlzk
via IFTTT
Subscribe to:
Posts (Atom)