When creating an order programmatically and skipping to the checkout process via redirect, the checkout system is denying access to anonymous ...
from Google Alert - anonymous http://ift.tt/2n0ycvd
via IFTTT
Saturday, March 4, 2017
Anonymous donor pays off Ohio students' lunch debts - ABC21: Your Weather Authority
School officials say an anonymous donor has paid off the lunch debts of more than 150 students in an Ohio city in honor of a retired cafeteria worker ...
from Google Alert - anonymous http://ift.tt/2mQMoYK
via IFTTT
from Google Alert - anonymous http://ift.tt/2mQMoYK
via IFTTT
Scientists Store an Operating System, a Movie and a Computer Virus on DNA
Do you know — 1 Gram of DNA Can Store 1,000,000,000 Terabyte of Data for 1000+ Years. Just last year, Microsoft purchased 10 Million strands of synthetic DNA from San Francisco DNA synthesis startup called Twist Bioscience and collaborated with researchers from the University of Washington to focus on using DNA as a data storage medium. However, in the latest experiments, a pair of


from The Hacker News http://ift.tt/2mQoCvF
via IFTTT
from The Hacker News http://ift.tt/2mQoCvF
via IFTTT
anonymous users
Having previously allowed guest posting I'm now considering converting all anonymous users to a bucket user. Can this be done? And if so how?
from Google Alert - anonymous http://ift.tt/2m546Yj
via IFTTT
from Google Alert - anonymous http://ift.tt/2m546Yj
via IFTTT
Sivan 2 to M31
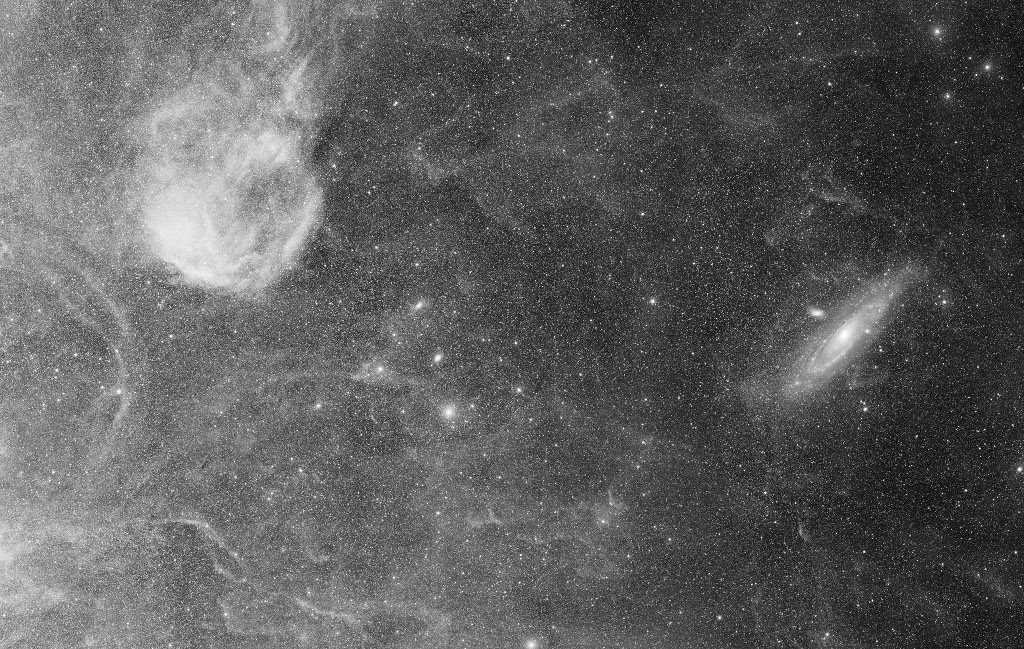
From within the boundaries of the constellation Cassiopeia (left) to Andromeda (right), this telescopic mosaic spans over 10 degrees in planet Earth's skies. The celestial scene is constructed of panels that are part of a high-resolution astronomical survey of the Milky Way in hydrogen-alpha light. Processing the monochromatic image data has brought out the region's faintest structures, relatively unexplored filaments of hydrogen gas near the plane of our Milky Way Galaxy. Large but faint and also relatively unknown nebula Sivan 2 is at the upper left in the field. The nearby Andromeda Galaxy, M31, is at center right, while the faint, pervasive hydrogen nebulosities stretch towards M31 across the foreground in the wide field of view. The broad survey image demonstrates the intriguing faint hydrogen clouds recently imaged by astronomer Rogelio Bernal Andreo really are within the Milky Way, along the line-of-sight to the Andromeda Galaxy. via NASA http://ift.tt/2lC3Nm8
Flying Through LIDAR Canopy Data
This visualization shows the resolution of LIDAR (LIght Detection And Ranging) canopy data over the Brazilian Rainforest by flying a virtual camera down through the data. The full swath of data consists of approximately 1 billion data points, where each data point is a position in 3D space. Together these data points provide scientists with information on foliage distribution and the elements of tree canopy. Similar LIDAR technologies are used to measure terrain topographies on the Moon and Mars.
from NASA's Scientific Visualization Studio: Most Recent Items http://ift.tt/2lGsJIT
via IFTTT
from NASA's Scientific Visualization Studio: Most Recent Items http://ift.tt/2lGsJIT
via IFTTT
North East Snow Storm on December 17, 2016
NASA's Global Precipitation Measurement mission or GPM core observatory satellite flew over the United States east coast during a snow storm on December 17, 2016. This print resolution image was created for use on the GPM Senior Review document. The GPM Core Observatory carries two instruments that show the location and intensity of rain and snow, which defines a crucial part of the storm structure - and how it will behave. The GPM Microwave Imager sees through the tops of clouds to observe how much and where precipitation occurs, and the Dual-frequency Precipitation Radar observes precise details of precipitation in 3-dimensions. GPM data is part of the toolbox of satellite data used by forecasters and scientists to understand how storms behave. GPM is a joint mission between NASA and the Japan Aerospace Exploration Agency. Current and future data sets are available with free registration to users from NASA Goddard's Precipitation Processing Center website.
from NASA's Scientific Visualization Studio: Most Recent Items http://ift.tt/2lGft7a
via IFTTT
from NASA's Scientific Visualization Studio: Most Recent Items http://ift.tt/2lGft7a
via IFTTT
Friday, March 3, 2017
An Anonymous Donation
An Anonymous Donation. The salt mine is dark and the humid, still air makes my breath hang before me. My torch gives the stacks and boxes of stolen ...
from Google Alert - anonymous http://ift.tt/2lFJPH0
via IFTTT
from Google Alert - anonymous http://ift.tt/2lFJPH0
via IFTTT
Anonymous Donor Gives $1000 for Lackawanna Firefighting Gear
"This donation, from a person who wished to remain anonymous, came as a direct result of a plea made earlier this year by Lackawanna firefighters ...
from Google Alert - anonymous http://ift.tt/2lIGxnn
via IFTTT
from Google Alert - anonymous http://ift.tt/2lIGxnn
via IFTTT
Redit etas aurea
Misc. Comments. For the unique source, see "Magnus liber organi", f. 318v-319r. This piece is a conductus and accordingly is not based on plainchant ...
from Google Alert - anonymous http://ift.tt/2m5peiL
via IFTTT
from Google Alert - anonymous http://ift.tt/2m5peiL
via IFTTT
Ryan Gosling, Ken Kao, Anonymous Content team on
Ryan Gosling, Ken Kao's Waypoint and Anonymous Content will produce the film. Lemire, Top Shelf editor-in-chief Chris Staros and IDW Publishing ...
from Google Alert - anonymous http://ift.tt/2m4PcTs
via IFTTT
from Google Alert - anonymous http://ift.tt/2m4PcTs
via IFTTT
I have a new follower on Twitter
Clayton Wood
I'm a digital marketer, traveler, corporate executive, start up guy. I believe that people are more capable than they think they are with the right motivation.
San Francisco, CA
http://t.co/n1xPdoIHsD
Following: 3178 - Followers: 4008
March 03, 2017 at 02:03PM via Twitter http://twitter.com/claytonwwood
Google Increases Bug Bounty Payouts by 50% and Microsoft Doubles It!
Well, there's some good news for hackers and bug bounty hunters! Both tech giants Google and Microsoft have raised the value of the payouts they offer security researchers, white hat hackers and bug hunters who find high severity flaws in their products. While Microsoft has just doubled its top reward from $15,000 to $30,000, Google has raised its high reward from $20,000 to $31,337, which

from The Hacker News http://ift.tt/2mBktPq
via IFTTT
from The Hacker News http://ift.tt/2mBktPq
via IFTTT
ISS Daily Summary Report – 3/02/2017
Lab Carbon Dioxide Removal Assembly (CDRA) Maintenance: Yesterday the crew installed the newer generation beds, like those in Node 3 CDRA, into Lab CDRA. Today, the crew repaired the CDRA Valve Power Cable W9P12 by splicing in two new wire segments and performing a 120V power check of the connector prior to installing CDRA into the LAB AR Rack. Initial CDRA power and data checkout was nominal. The full Lab CDRA checkout is in work. Pressurized Mating Adaptor (PMA) 3 Ingress Prep: The crew is scheduled to ingress the PMA3 tomorrow morning. Today the crew reviewed the PMA3 ingress procedure and gathered required hardware for tomorrow’s activities. Energy Requirements for Long-Term Space Flight (Energy): Today is Day 1 for the Energy investigation; yesterday the subject began the 11 day diet and today began the urine collection for both the subject and control subject. This morning, the subject configured the Pulmonary Function System (PFS) and performed a series of Oxygen Uptake Measurements (OUMs) after prescribed meals and scheduled fluid collections. The Energy investigation measures adaptations in the components of total energy expenditure of crewmembers, so that an equation to determine the energy requirements of crewmembers during space flight may be derived. Such knowledge of energy requirements is of a great importance to ensure health, good performance and the overall success of a mission, and also contributes to ensure adequate exercise load and cargo allotments for food during space flight. Advanced Plant Experiments (APEX)-04 Photo: The crew retrieved one of the APEX-04 petri plates and photographed it on the Advanced Biology Research Facility (ABRS) photogrid. The picture will be downlinked for ground teams to evaluate the growth status. The APEX-04 (Epigenetic change in Arabidopsis thaliana in response to spaceflight – differential cytosine DNA methylation of plants on the ISS) experiment investigates how spaceflight can affect an organism on a molecular level without altering its outward appearance. Previous research has demonstrated that large numbers of plant genes are expressed differently in space compared to plants on Earth, which can alter how plants grow. This investigation studies the entire genome of thale cress plants grown in space, creating maps of spaceflight-specific changes in certain groups of genes. Results give new insight into plants’ molecular responses to spaceflight, which benefits efforts to grow plants in space for food and oxygen. Microgravity Expanded Stem Cells (MESC) Microscope Operations: The crew removed a BioCell from the Space Automated Bioproduct Laboratory-2 (SABL2) and placed it on the microscope stage configured outside the Microgravity Science Glovebox (MSG). The crew worked with ground specialist to image areas of the BioCell plate. Following the focused imaging, the crew reinserted the BioCell back into the SABL. MESC will aid researches determine the efficiency of using a microgravity environment to accelerate expansion (replication) of stem cells for use in terrestrial clinical trials for treatment of disease. ISS Reboost: Last night the ISS performed a nominal reboost using the SM main engines, TIG 061/03:10 GMT burn duration 43 seconds. The reboost set up the planned conditions for the upcoming landing of 48S on 10-April and launch of 50S on 20-April 20. The 50S launch will utilize the 4-orbit rendezvous. Mobile Servicing System (MSS) Operations: Robotics operations for Stratospheric Aerosol and Gas Experiment (SAGE) Instrument Panel (IP) extraction from the SpX-10 Dragon Trunk have begun. Today’s Planned Activities All activities were completed unless otherwise noted. Energy PFS Powerup Energy Urine Sample Collection Regeneration of БМП Ф1 Micropurification Cartridge (start) Energy PFS Instrument Check ENERGY Double Labeled Water Intake In Flight Maintenance Carbon Dioxide Removal Assembly (CDRA) Preparation. Energy Oxygen Uptake – Part 1 Pressurized Mating Adapter 3 Big Picture Word Review IDENTIFICATION. Copy ИМУ-Ц micro-accelerometer data to laptop Electrostatic Levitation Furnace(ELF) sample holder packing for SpX-10 early destow Water Recovery System Waste Water Tank Drain Termination In Flight Maintenance Carbon Dioxide Removal Assembly (CDRA) Preparation. Standardized Breakfast Replacement of БД-2 Treadmill Belt. Energy Oxygen Uptake – Part 2 In-flight Maintenance (IFM) Carbon Dioxide Removal Assembly (CDRA) Chassis Installation Empty bladder for ENERGY Energy Oxygen Uptake – Part 3 Start transfer from CWC-I No.2379 (NODE1; 20.4 L) to EDV No.1234 (00068255R, ФГБ1ПГО1_109) СОЖ maintenance Terminate water transfer from CWC-I to ЕДВ Progress 435 (DC1) Cargo Transfers and IMS Ops Energy Urine Sample Collection Energy Oxygen Uptake – Part 4 BIOPLENKA. Removal of Samples from the Thermostat, fixation of Constanta cassette No.1-6 biofilm. Energy Urine Sample Collection Lab Carbon Dioxide Removal Assembly (CDRA) Bed Equipment Stow Energy Urine Sample Collection BIOPLENKA. Removal of Cryogem-03 after Completion of the Experiment APEX-04 Petri Plate Photo Meteor Shutter Open Rodent Research Access Unit Clean Energy PFS Conclude Progress 435 (DC1) Cargo Transfers and IMS Ops Pressurized Mating Adapter 3 (PMA 3) Hardware Gather ENERGY Diet Log of Lunch Columbus Video Camera Assembly 1 Adjustment Preparing For Upcoming MagVector Science Run ESA Weekly crew conference RS remote laptop testing after BRI cleaning. Regenerative Environmental Control and Life Support System (RGN) Wastewater Storage Tank Assembly (WSTA) Fill Inventory Management System (IMS) Conference Public Affairs Office (PAO) High Definition (HD) Config LAB Setup Microscope Hardware Unstow PAO Preparation Delta file prep Public Affairs Office (PAO) Event in High Definition (HD) – Lab Dose Tracker Data Entry Subject Micrgravity Expanded Stem Cells Microscope Ops Activation/Deactivation of MPEG2 Multicast TV Data Monitoring a (Ku-band) Cleaning dust filter cartridges ПФ1-4 in SM Fluid Shifts Dilution Measures Setup Download of BRI log from RSS1 CONTENT. Experiment Ops JEM System Laptop Terminal Reboot Flight Director/ISS CREW CONFERENCE Microscope Hardware Temporary Stowage Completed Task List Items None Ground Activities All activities were completed unless otherwise noted. Lab AR Rack Activation Lab CDRA Checkout SAGE IP Extract Three-Day Look Ahead: Friday, 03/03: Node 2 Power Cable (HMU 220) Rerouting, PMA3 Ingress, ESA Energy, Node 3 IMV Valve Scavenge Saturday, 03/04: Weekly Housekeeping, Microgravity Expanded Stem Cells (MESC) Session Sunday, 03/05: Microgravity Expanded Stem Cells (MESC) Session QUICK ISS Status – Environmental Control Group: Component Status Elektron On Vozdukh Manual [СКВ] 1 – SM Air Conditioner System (“SKV1”) Off [СКВ] 2 – […]
from ISS On-Orbit Status Report http://ift.tt/2m3pbCt
via IFTTT
from ISS On-Orbit Status Report http://ift.tt/2m3pbCt
via IFTTT
O Salutaris for Wind Band (Anonymous)
O Salutaris for Wind Band (Anonymous). (Redirected from O Salutaris (Instrumental) (Anonymous)). Movements/SectionsMov'ts/Sec's, 1. Contents.
from Google Alert - anonymous http://ift.tt/2lGInFf
via IFTTT
from Google Alert - anonymous http://ift.tt/2lGInFf
via IFTTT
Big media overuses anonymous sources
Donald Trump's ongoing attacks on the media are, at their heart, a diversionary tactic. They're designed to distract the public from the numerous early ...
from Google Alert - anonymous http://ift.tt/2llAI2Q
via IFTTT
from Google Alert - anonymous http://ift.tt/2llAI2Q
via IFTTT
All Singapore Stuff apologises for 'unfounded allegations'
Singapore Stomp - Alternative news website All Singapore Stuff apologised on Thursday (March 2) morning for posting an online article which police ...
from Google Alert - anonymous http://ift.tt/2lGSXMs
via IFTTT
from Google Alert - anonymous http://ift.tt/2lGSXMs
via IFTTT
Management Accountant
The role of the Management Accountant is to manage the day to day running of the accounts department and is responsible for the production of the ...
from Google Alert - anonymous http://ift.tt/2llsZC8
via IFTTT
from Google Alert - anonymous http://ift.tt/2llsZC8
via IFTTT
Credit Controller
Elevation Recruitment Group are currently recruiting for a permanent, full time Credit Controller for a well known business in Doncaster. Duties and ...
from Google Alert - anonymous http://ift.tt/2lGVCph
via IFTTT
from Google Alert - anonymous http://ift.tt/2lGVCph
via IFTTT
Accounts Assistant
Accounts Assistant – Gloucester Salary up to GBP11 per hour plus holiday pay. Specialist high–tech engineering business is looking for some ...
from Google Alert - anonymous http://ift.tt/2llqoI1
via IFTTT
from Google Alert - anonymous http://ift.tt/2llqoI1
via IFTTT
Management Accountant
Management Accountant in IT, Management accountant with Anonymous. Apply Today.
from Google Alert - anonymous http://ift.tt/2lGZBCn
via IFTTT
from Google Alert - anonymous http://ift.tt/2lGZBCn
via IFTTT
Payroll Officer
Payroll Officer in Accounting and public practice, Accountant with Anonymous. Apply Today.
from Google Alert - anonymous http://ift.tt/2llqLm2
via IFTTT
from Google Alert - anonymous http://ift.tt/2llqLm2
via IFTTT
Business Analyst
Business Analyst in Accounting and public practice, Accountant with Anonymous. Apply Today.
from Google Alert - anonymous http://ift.tt/2lGVG8q
via IFTTT
from Google Alert - anonymous http://ift.tt/2lGVG8q
via IFTTT
Finance Director
Finance Director in Accounting and public practice, Finance director with Anonymous. Apply Today.
from Google Alert - anonymous http://ift.tt/2llv3tw
via IFTTT
from Google Alert - anonymous http://ift.tt/2llv3tw
via IFTTT
I have a new follower on Twitter
Schmoozys
https://t.co/DS5W79Unov, Unique Crowdsourced Social Marketplace, w/ a Revenue Share Referral Program. MAKE MONEY. Passion Req'd.
Georgia, USA
http://t.co/zeaf0swXRd
Following: 13832 - Followers: 18362
March 03, 2017 at 05:53AM via Twitter http://twitter.com/Schmoozys
I have a new follower on Twitter
🚀🚀 Barry
Head of Digital Marketing & Programmatic Media at the world's most trusted events platform. Tweet me if you're interested in a premium business account.
Global
https://t.co/oV1dPGte8h
Following: 3133 - Followers: 3401
March 03, 2017 at 04:48AM via Twitter http://twitter.com/Barry_HOD
How A Simple Command Typo Took Down Amazon S3 and Big Chunk of the Internet
The major internet outage across the United States earlier this week was not due to any virus or malware or state-sponsored cyber attack, rather it was the result of a simple TYPO. Amazon on Thursday admitted that an incorrectly typed command during a routine debugging of the company's billing system caused the 5-hour-long outage of some Amazon Web Services (AWS) servers on Tuesday. The

from The Hacker News http://ift.tt/2mzkIuy
via IFTTT
from The Hacker News http://ift.tt/2mzkIuy
via IFTTT
Annular Eclipse After Sunrise

From northern Patagonia, morning skies were clear and blue on Sunday, February 26. This sweeping composite scene, overlooking Hermoso Valle, Facundo, Chubut, Argentina, follows the Sun after sunrise, capturing an annular solar eclipse. Created from a series of exposures at three minute intervals, it shows the year's first solar eclipse beginning well above the distant eastern horizon. An exposure close to mid-eclipse recorded the expected ring of fire, the silhouette of the New Moon only slightly too small to cover the bright Sun. At that location on planet Earth, the annular phase of the eclipse lasted a brief 45 seconds. via NASA http://ift.tt/2lwEkdM
Thursday, March 2, 2017
I have a new follower on Twitter
Keith Gutierrez
Founder and #InboundMarketing Evangelist @manageinbound. Marketing VP @modgility. Family man, blessed with twins. Doing what is a product of my own conclusion.
Westlake, OH
https://t.co/6idngq2DzN
Following: 18009 - Followers: 21932
March 02, 2017 at 09:58PM via Twitter http://twitter.com/keithgutierrez
Anonymous Noise
Showing 1-1 of 1 results for “Anonymous Noise”. Sorted by date added ... Cover image for Anonymous Noise, Volume 1 · Anonymous Noise, Volume 1.
from Google Alert - anonymous http://ift.tt/2mgvDrJ
via IFTTT
from Google Alert - anonymous http://ift.tt/2mgvDrJ
via IFTTT
[FD] Remote file upload vulnerability in Wordpress Plugin Mobile App Native 3.0
Title: Remote file upload vulnerability in Wordpress Plugin Mobile App Native 3.0 Vulnerability Date: 2017-02-27 Download: http://ift.tt/2cVeXTd Vendor: http://ift.tt/2misg41 Notified: 2017-02-27 Description: Mobile App WordPress plugin lets you turn your website into a full-featured mobile application in minutes using Mobile App Builder. Vulnerability: The code in file ./zen-mobile-app-native/server/images.php doesn't require authentication or check that the user is allowed to upload content. It also doesn't sanitize the file upload against executable code.
Truth and Regret in Online Scheduling. (arXiv:1703.00484v1 [cs.GT])
We consider a scheduling problem where a cloud service provider has multiple units of a resource available over time. Selfish clients submit jobs, each with an arrival time, deadline, length, and value. The service provider's goal is to implement a truthful online mechanism for scheduling jobs so as to maximize the social welfare of the schedule. Recent work shows that under a stochastic assumption on job arrivals, there is a single-parameter family of mechanisms that achieves near-optimal social welfare. We show that given any such family of near-optimal online mechanisms, there exists an online mechanism that in the worst case performs nearly as well as the best of the given mechanisms. Our mechanism is truthful whenever the mechanisms in the given family are truthful and prompt, and achieves optimal (within constant factors) regret.
We model the problem of competing against a family of online scheduling mechanisms as one of learning from expert advice. A primary challenge is that any scheduling decisions we make affect not only the payoff at the current step, but also the resource availability and payoffs in future steps. Furthermore, switching from one algorithm (a.k.a. expert) to another in an online fashion is challenging both because it requires synchronization with the state of the latter algorithm as well as because it affects the incentive structure of the algorithms. We further show how to adapt our algorithm to a non-clairvoyant setting where job lengths are unknown until jobs are run to completion. Once again, in this setting, we obtain truthfulness along with asymptotically optimal regret (within poly-logarithmic factors).
from cs.AI updates on arXiv.org http://ift.tt/2lzz353
via IFTTT
Learning Social Affordance Grammar from Videos: Transferring Human Interactions to Human-Robot Interactions. (arXiv:1703.00503v1 [cs.RO])
In this paper, we present a general framework for learning social affordance grammar as a spatiotemporal AND-OR graph (ST-AOG) from RGB-D videos of human interactions, and transfer the grammar to humanoids to enable a real-time motion inference for human-robot interaction (HRI). Based on Gibbs sampling, our weakly supervised grammar learning can automatically construct a hierarchical representation of an interaction with long-term joint sub-tasks of both agents and short term atomic actions of individual agents. Based on a new RGB-D video dataset with rich instances of human interactions, our experiments of Baxter simulation, human evaluation, and real Baxter test demonstrate that the model learned from limited training data successfully generates human-like behaviors in unseen scenarios and outperforms both baselines.
from cs.AI updates on arXiv.org http://ift.tt/2mgk8AR
via IFTTT
PMLB: A Large Benchmark Suite for Machine Learning Evaluation and Comparison. (arXiv:1703.00512v1 [cs.LG])
The selection, development, or comparison of machine learning methods in data mining can be a difficult task based on the target problem and goals of a particular study. Numerous publicly available real-world and simulated benchmark datasets have emerged from different sources, but their organization and adoption as standards have been inconsistent. As such, selecting and curating specific benchmarks remains an unnecessary burden on machine learning practitioners and data scientists. The present study introduces an accessible, curated, and developing public benchmark resource to facilitate identification of the strengths and weaknesses of different machine learning methodologies. We compare meta-features among the current set of benchmark datasets in this resource to characterize the diversity of available data. Finally, we apply a number of established machine learning methods to the entire benchmark suite and analyze how datasets and algorithms cluster in terms of performance. This work is an important first step towards understanding the limitations of popular benchmarking suites and developing a resource that connects existing benchmarking standards to more diverse and efficient standards in the future.
from cs.AI updates on arXiv.org http://ift.tt/2lzDoW5
via IFTTT
Evolving Deep Neural Networks. (arXiv:1703.00548v1 [cs.NE])
The success of deep learning depends on finding an architecture to fit the task. As deep learning has scaled up to more challenging tasks, the architectures have become difficult to design by hand. This paper proposes an automated method, CoDeepNEAT, for optimizing deep learning architectures through evolution. By extending existing neuroevolution methods to topology, components, and hyperparameters, this method achieves results comparable to best human designs in standard benchmarks in object recognition and language modeling. It also supports building a real-world application of automated image captioning on a magazine website. Given the anticipated increases in available computing power, evolution of deep networks is promising approach to constructing deep learning applications in the future.
from cs.AI updates on arXiv.org http://ift.tt/2mgjtPY
via IFTTT
Conversion Rate Optimization through Evolutionary Computation. (arXiv:1703.00556v1 [cs.HC])
Conversion optimization means designing a web interface so that as many users as possible take a desired action on it, such as register or purchase. Such design is usually done by hand, testing one change at a time through A/B testing, or a limited number of combinations through multivariate testing, making it possible to evaluate only a small fraction of designs in a vast design space. This paper describes Sentient Ascend, an automatic conversion optimization system that uses evolutionary optimization to create effective web interface designs. Ascend makes it possible to discover and utilize interactions between the design elements that are difficult to identify otherwise. Moreover, evaluation of design candidates is done in parallel online, i.e. with a large number of real users interacting with the system. A case study on a lead generation site learnhotobecome.org shows that significant improvements (i.e. over 43%) are possible beyond human design. Ascend can therefore be seen as an approach to massively multivariate conversion optimization, based on a massively parallel interactive evolution.
from cs.AI updates on arXiv.org http://ift.tt/2m1FtMe
via IFTTT
Adaptive Matching for Expert Systems with Uncertain Task Types. (arXiv:1703.00674v1 [cs.AI])
Online two-sided matching markets such as Q&A forums (e.g. StackOverflow, Quora) and online labour platforms (e.g. Upwork) critically rely on the ability to propose adequate matches based on imperfect knowledge of the two parties to be matched. This prompts the following question: Which matching recommendation algorithms can, in the presence of such uncertainty, lead to efficient platform operation?
To answer this question, we develop a model of a task / server matching system. For this model, we give a necessary and sufficient condition for an incoming stream of tasks to be manageable by the system. We further identify a so-called back-pressure policy under which the throughput that the system can handle is optimized. We show that this policy achieves strictly larger throughput than a natural greedy policy. Finally, we validate our model and confirm our theoretical findings with experiments based on logs of Math.StackExchange, a StackOverflow forum dedicated to mathematics.
from cs.AI updates on arXiv.org http://ift.tt/2myJJFU
via IFTTT
Sampling Variations of Lead Sheets. (arXiv:1703.00760v1 [cs.AI])
Machine-learning techniques have been recently used with spectacular results to generate artefacts such as music or text. However, these techniques are still unable to capture and generate artefacts that are convincingly structured. In this paper we present an approach to generate structured musical sequences. We introduce a mechanism for sampling efficiently variations of musical sequences. Given a input sequence and a statistical model, this mechanism samples a set of sequences whose distance to the input sequence is approximately within specified bounds. This mechanism is implemented as an extension of belief propagation, and uses local fields to bias the generation. We show experimentally that sampled sequences are indeed closely correlated to the standard musical similarity measure defined by Mongeau and Sankoff. We then show how this mechanism can used to implement composition strategies that enforce arbitrary structure on a musical lead sheet generation problem.
from cs.AI updates on arXiv.org http://ift.tt/2lzDoFz
via IFTTT
SLIM: Semi-Lazy Inference Mechanism for Plan Recognition. (arXiv:1703.00838v1 [cs.AI])
Plan Recognition algorithms require to recognize a complete hierarchy explaining the agent's actions and goals. While the output of such algorithms is informative to the recognizer, the cost of its calculation is high in run-time, space, and completeness. Moreover, performing plan recognition online requires the observing agent to reason about future actions that have not yet been seen and maintain a set of hypotheses to support all possible options. This paper presents a new and efficient algorithm for online plan recognition called SLIM (Semi-Lazy Inference Mechanism). It combines both a bottom-up and top-down parsing processes, which allow it to commit only to the minimum necessary actions in real-time, but still provide complete hypotheses post factum. We show both theoretically and empirically that although the computational cost of this process is still exponential, there is a significant improvement in run-time when compared to a state of the art of plan recognition algorithm.
from cs.AI updates on arXiv.org http://ift.tt/2mg9Oc3
via IFTTT
Unsupervised Image-to-Image Translation Networks. (arXiv:1703.00848v1 [cs.CV])
Most of the existing image-to-image translation frameworks---mapping an image in one domain to a corresponding image in another---are based on supervised learning, i.e., pairs of corresponding images in two domains are required for learning the translation function. This largely limits their applications, because capturing corresponding images in two different domains is often a difficult task. To address the issue, we propose the UNsupervised Image-to-image Translation (UNIT) framework, which is based on variational autoencoders and generative adversarial networks. The proposed framework can learn the translation function without any corresponding images in two domains. We enable this learning capability by combining a weight-sharing constraint and an adversarial training objective. Through visualization results from various unsupervised image translation tasks, we verify the effectiveness of the proposed framework. An ablation study further reveals the critical design choices. Moreover, we apply the UNIT framework to the unsupervised domain adaptation task and achieve better results than competing algorithms do in benchmark datasets.
from cs.AI updates on arXiv.org http://ift.tt/2lzw3Wh
via IFTTT
Unsupervised Domain Adaptation Using Approximate Label Matching. (arXiv:1602.04889v3 [cs.LG] UPDATED)
Domain adaptation addresses the problem created when training data is generated by a so-called source distribution, but test data is generated by a significantly different target distribution. In this work, we present approximate label matching (ALM), a new unsupervised domain adaptation technique that creates and leverages a rough labeling on the test samples, then uses these noisy labels to learn a transformation that aligns the source and target samples. We show that the transformation estimated by ALM has favorable properties compared to transformations estimated by other methods, which do not use any kind of target labeling. Our model is regularized by requiring that a classifier trained to discriminate source from transformed target samples cannot distinguish between the two. We experiment with ALM on simulated and real data, and show that it outperforms techniques commonly used in the field.
from cs.AI updates on arXiv.org http://ift.tt/1VlBqVv
via IFTTT
An Online Mechanism for Ridesharing in Autonomous Mobility-on-Demand Systems. (arXiv:1603.02208v3 [cs.AI] UPDATED)
With proper management, Autonomous Mobility-on-Demand (AMoD) systems have great potential to satisfy the transport demands of urban populations by providing safe, convenient, and affordable ridesharing services. Meanwhile, such systems can substantially decrease private car ownership and use, and thus significantly reduce traffic congestion, energy consumption, and carbon emissions. To achieve this objective, an AMoD system requires private information about the demand from passengers. However, due to self-interestedness, passengers are unlikely to cooperate with the service providers in this regard. Therefore, an online mechanism is desirable if it incentivizes passengers to truthfully report their actual demand. For the purpose of promoting ridesharing, we hereby introduce a posted-price, integrated online ridesharing mechanism (IORS) that satisfies desirable properties such as ex-post incentive compatibility, individual rationality, and budget-balance. Numerical results indicate the competitiveness of IORS compared with two benchmarks, namely the optimal assignment and an offline, auction-based mechanism.
from cs.AI updates on arXiv.org http://ift.tt/1RxybXB
via IFTTT
Inference Compilation and Universal Probabilistic Programming. (arXiv:1610.09900v2 [cs.AI] UPDATED)
We introduce a method for using deep neural networks to amortize the cost of inference in models from the family induced by universal probabilistic programming languages, establishing a framework that combines the strengths of probabilistic programming and deep learning methods. We call what we do "compilation of inference" because our method transforms a denotational specification of an inference problem in the form of a probabilistic program written in a universal programming language into a trained neural network denoted in a neural network specification language. When at test time this neural network is fed observational data and executed, it performs approximate inference in the original model specified by the probabilistic program. Our training objective and learning procedure are designed to allow the trained neural network to be used as a proposal distribution in a sequential importance sampling inference engine. We illustrate our method on mixture models and Captcha solving and show significant speedups in the efficiency of inference.
from cs.AI updates on arXiv.org http://ift.tt/2egA1CR
via IFTTT
Reinforcement Learning With Temporal Logic Rewards. (arXiv:1612.03471v2 [cs.AI] UPDATED)
Reinforcement learning (RL) depends critically on the choice of reward functions used to capture the de- sired behavior and constraints of a robot. Usually, these are handcrafted by a expert designer and represent heuristics for relatively simple tasks. Real world applications typically involve more complex tasks with rich temporal and logical structure. In this paper we take advantage of the expressive power of temporal logic (TL) to specify complex rules the robot should follow, and incorporate domain knowledge into learning. We propose Truncated Linear Temporal Logic (TLTL) as specifications language, that is arguably well suited for the robotics applications, together with quantitative semantics, i.e., robustness degree. We propose a RL approach to learn tasks expressed as TLTL formulae that uses their associated robustness degree as reward functions, instead of the manually crafted heuristics trying to capture the same specifications. We show in simulated trials that learning is faster and policies obtained using the proposed approach outperform the ones learned using heuristic rewards in terms of the robustness degree, i.e., how well the tasks are satisfied. Furthermore, we demonstrate the proposed RL approach in a toast-placing task learned by a Baxter robot.
from cs.AI updates on arXiv.org http://ift.tt/2gujOrn
via IFTTT
Survey of reasoning using Neural networks. (arXiv:1702.06186v2 [cs.LG] UPDATED)
Reason and inference require process as well as memory skills by humans. Neural networks are able to process tasks like image recognition (better than humans) but in memory aspects are still limited (by attention mechanism, size). Recurrent Neural Network (RNN) and it's modified version LSTM are able to solve small memory contexts, but as context becomes larger than a threshold, it is difficult to use them. The Solution is to use large external memory. Still, it poses many challenges like, how to train neural networks for discrete memory representation, how to describe long term dependencies in sequential data etc. Most prominent neural architectures for such tasks are Memory networks: inference components combined with long term memory and Neural Turing Machines: neural networks using external memory resources. Also, additional techniques like attention mechanism, end to end gradient descent on discrete memory representation are needed to support these solutions. Preliminary results of above neural architectures on simple algorithms (sorting, copying) and Question Answering (based on story, dialogs) application are comparable with the state of the art. In this paper, I explain these architectures (in general), the additional techniques used and the results of their application.
from cs.AI updates on arXiv.org http://ift.tt/2kJOf4a
via IFTTT
Beating the World's Best at Super Smash Bros. with Deep Reinforcement Learning. (arXiv:1702.06230v2 [cs.LG] UPDATED)
There has been a recent explosion in the capabilities of game-playing artificial intelligence. Many classes of RL tasks, from Atari games to motor control to board games, are now solvable by fairly generic algorithms, based on deep learning, that learn to play from experience with minimal knowledge of the specific domain of interest. In this work, we will investigate the performance of these methods on Super Smash Bros. Melee (SSBM), a popular console fighting game. The SSBM environment has complex dynamics and partial observability, making it challenging for human and machine alike. The multi-player aspect poses an additional challenge, as the vast majority of recent advances in RL have focused on single-agent environments. Nonetheless, we will show that it is possible to train agents that are competitive against and even surpass human professionals, a new result for the multi-player video game setting.
from cs.AI updates on arXiv.org http://ift.tt/2l5Qn27
via IFTTT
performance testing of named or anonymous functions
Revisions. You can edit these tests or add even more tests to this page by appending /edit to the URL. Revision 1: published Stephen Mathieson on ...
from Google Alert - anonymous http://ift.tt/2lk6jSt
via IFTTT
from Google Alert - anonymous http://ift.tt/2lk6jSt
via IFTTT
Anonymous Noise, Volume 1
Nino Arisugawa, a girl who loves to sing, experiences her first heart-wrenching goodbye when her beloved childhood friend, Momo, moves away.
from Google Alert - anonymous http://ift.tt/2lFk5v0
via IFTTT
from Google Alert - anonymous http://ift.tt/2lFk5v0
via IFTTT
Venite adoremus in F major (Anonymous)
Work Title, Venite adoremus in F major. Alternative. Title. Composer, Anonymous. Key, F mahor. Year/Date of CompositionY/D of Comp. 1895 or ...
from Google Alert - anonymous http://ift.tt/2ljWd49
via IFTTT
from Google Alert - anonymous http://ift.tt/2ljWd49
via IFTTT
auth proxies can't proxy anonymous requests
auth proxies can't proxy anonymous requests #42437. Open. deads2k opened this Issue an hour ago · 0 comments ...
from Google Alert - anonymous http://ift.tt/2lF7Gar
via IFTTT
from Google Alert - anonymous http://ift.tt/2lF7Gar
via IFTTT
Anorexics and Bulimics Anonymous: We Bite Back
Anorexics and Bulimics Anonymous is a Fellowship of individuals whose primary purpose is to find and maintain sobriety in our eating practices, and ...
from Google Alert - anonymous http://ift.tt/2lz2jsx
via IFTTT
from Google Alert - anonymous http://ift.tt/2lz2jsx
via IFTTT
Free Agency: Expect Ravens to be active in one of most crucial offseasons in franchise history - Jamison Hensley (ESPN)
from ESPN http://ift.tt/17lH5T2
via IFTTT
via IFTTT
Trump's New FCC Chairman Allows ISPs Sell Your Private Data Without Your Consent
Bad News for privacy concerned people! It will be once again easier for Internet Service Providers (ISPs) to sell your personal data for marketing or advertisement purposes without taking your permission. Last October, the United States Federal Communications Commission (FCC) passed a set of privacy rules on ISPs that restrict them from sharing your online data with third parties without

from The Hacker News http://ift.tt/2lihprm
via IFTTT
from The Hacker News http://ift.tt/2lihprm
via IFTTT
ISS Daily Summary Report – 3/01/2017
Lab Carbon Dioxide Removal Assembly (CDRA) Maintenance: Yesterday the crew removed Lab CDRA from the rack, and disassemble it by removing all of the valves and ducting to access the beds. They also removed the old beds. Today, the crew installed the newer generation beds, like those in Node 3 CDRA, mated Hydraflow Couplings, and electrical connectors. The crew is scheduled to reinstall the Lab CDRA on Thursday. Japanese Experiment Module (JEM) Microbe Sensor Installation: The crew installed the JEM Microbe Sensor at the Deck 7 location in the JEM Pressurized Module (JPM). They connected the power cable to the JEM Power Supply-120 (PS-120) Junction Box, and connected the Ethernet Cable JEM Ethernet Hub. Microbe Sensor visualizes airborne microbe of JPM. The Microbe Sensor will monitor the JPM cabin environment real time, instead of sample collect and return to ground, which will allow quick feedback on the quality of the cabin environment. JEM Local Area Network (LAN) Monitor Installation: Today, the crew installed three JEM LAN Monitors and connected the JEM LAN Monitor Pwr Cable, LAN Cables (one each) and two Universal Serial Bus (USB) Memories. The JEM LAN Monitor will serve as an ethernet packet capture device on the JEM PL LAN. This device will introduce new capabilities to monitor, analyze, troubleshoot network issues over the JEM PL LAN. Once the JEM LAN Monitor is installed, crew time for the troubleshooting is expected to be saved. JAXA Freezer-Refrigerator Of STirling cycle (FROST) 2 Installation: The crew installed the second FROST in the JEM Pressurized Module (JPM). FROST was delivered over two flights, SpaceX-10 and HTV-6 and will deliver conditioned stowage capability. The next planned use of FROST2 is for the Moderate Temperature Protein Crystal Growth (MT PCG) experiment scheduled to fly on SpX-11. Rodent Research (RR) Habitat Restock: The crew restocked the four habitats today. The habitats were emptied, cleaned, and new food bars installed. The rodents were then transferred back into the habitats and then secured the habitats back into their individual stowage locations. The Tissue Regeneration-Bone Defect (RR-4) investigation studies what prevents vertebrates such as rodents and humans from regrowing lost bone and tissue, and how the microgravity extraterrestrial condition impacts the process. Results could lead to tissue regeneration efforts in space and a better understanding of limitations of limb regrowth at wound sites. Astronaut Energy Requirements for Long-Term Space Flight (Energy): The crew started Energy Day 0 today. The subject donned an armband monitor, set up the Pulmonary Function System (PFS) hardware, and started to eat a controlled diet. For this part of the investigation, additionally, a control subject participated as well, with both crewmembers collecting urine samples at approximately the same time over the next 11 days (Day 0 through Day 10). Energy measures change in energy balance in crewmembers following long term space flight. Energy also measures adaptations in the components of total energy expenditure of crewmembers, so that an equation to determine the energy requirements of crewmembers during space flight may be derived. Such knowledge of energy requirements is of a great importance to ensure health, good performance and the overall success of a mission, and also contributes to ensure adequate exercise load and cargo allotments for food during space flight. Mobile Servicing System (MSS) Operations: Last night the Robotics Ground Controllers translated the Mobile Transporter (MT) from Worksite 7 (WS7) to WS6. The MSS was subsequently powered up and the Space Station Remote Manipulator System (SSRMS) and Special Purpose Dexterous Manipulator (SPDM) were maneuvered to stow the SPDM on the Lab Power Data Grapple Fixture (PDGF). The SSRMS was then walked off Mobile Base System (MBS) PDGF4 onto the Node 2 PDGF and the SSRMS was maneuvered to unstow the SPDM. Finally SPDM Arm2 rotated the SPDM Enhanced Orbital Replacement Unit (ORU) Temporary Platform (EOTP) thus completing the MSS reconfiguration required for the start of the Stratospheric Aerosol and Gas Experiment (SAGE) Instrument Panel (IP) extraction from the SpX-10 Dragon Trunk on 02 Mar 17. MSS performance was nominal. ISS Reboost: Overnight the ISS is scheduled to perform a reboost using the SM main engines at 3:10 GMT (21:10 CST). The purpose of the reboost is to set up the planned conditions for the upcoming landing of 48S on April 10th and launch of 50S on April 20th. Today’s Planned Activities All activities were completed unless otherwise noted. Photo/TV JEM MPEG Activation KONYUGATSIYA. Rekomb-K retrieval from Thermostat (+4C) and installation in Thermostat +29C. Fine Motor Skills Experiment Test – Subject БД-2 Treadmill Belt R&R (r/g review, hardware pre-gather). ISS HAM Service Module Pass Rodent Research Node 2 Camcorder Video Setup In-flight Maintenance (IFM) Carbon Dioxide Removal Assembly (CDRA) Bed Installation Soyuz 732 Samsung Tablet Recharge (if charge level is below 80%) KONJUGATSIYA. Activation, location in termostat on +29 degrees C PRODUTSENT. Removal from Thermostat ТБУ-В # 2 (+29 °С) and transfer to Thermostat ТБУ-В # 4 (+4°С) MICROVIR. Photography of Lower Cell Condition Кассеты-М # 2-3, 2-4. Closeout Ops Nikon Camera Time Sync Crew Medical Officer (CMO) Proficiency Training JEM Freezer-Refrigerator Of STirling cycle 2 (FROST2) Installation KONYUGATSIYA. Activation process termination, insertion in Thermostat (+29 °С). KONYUGATSIYA. Photography during deactivation. Crew Prep for PAO Event Public Affairs Office (PAO) High Definition (HD) Config LAB Setup BIOPLENKA. Removal of samples from thermostat, Fixation of Constanta No.1-4 cassette biofilm. Total Organic Carbon Analyzer (TOCA) Water Recovery System (WRS) Sample Analysis Carbon Dioxide Removal Assembly (CDRA) Pin Kit Gather APEX-04 Petri Plate Photo Environmental Health System (EHS) – Rad Detector Relocate KONYUGATSIYA. Removal from Thermostat (+29 °С) and перенос в термостат (+4 °С). KONYUGATSIYA. ТБУ-В Thermostat No.2 deactivation JEM Microbe Sensor Installation TV-session with students of the City Pedagogical University of Moscow (Ku+S-band) Soyuz 732 Samsung Tablet Battery Recharge End (if needed) EDV (KOV) separation for ELEKTRON or EVD-SV Separate EDV(КОВ) №1201 (ФГБ1ПГО_1_108), using EDV №1239 (ФГБ1ПГО_1_109) Lab Carbon Dioxide Removal Assembly (CDRA) Component Group Install JEM LAN Monitor Installation СОЖ maintenance Preventive Maintenance of FS1 Laptop RS БРИ maintenance. Network standart mode checkout […]
from ISS On-Orbit Status Report http://ift.tt/2mJSUR0
via IFTTT
from ISS On-Orbit Status Report http://ift.tt/2mJSUR0
via IFTTT
Google Employees Help Thousands Of Open Source Projects Patch Critical ‘Mad Gadget Bug’
Last year Google employees took an initiative to help thousands of Open Source Projects patch a critical remote code execution vulnerability in a widely used Apache Commons Collections (ACC) library. Dubbed Operation Rosehub, the initiative was volunteered by some 50 Google employees, who utilized 20 percent of their work time to patch thousands of open source projects on Github, those were

from The Hacker News http://ift.tt/2lZIpch
via IFTTT
from The Hacker News http://ift.tt/2lZIpch
via IFTTT
I have a new follower on Twitter
SDLC Teacher Recruit
Learn more about living and working in Southwest Florida. Your source for information on teacher recruitment for the School District of Lee County.
Lee County, FL
http://t.co/kgN6ewWKU7
Following: 2988 - Followers: 3306
March 02, 2017 at 03:53AM via Twitter http://twitter.com/LeeSchoolCareer
Yahoo Reveals 32 Million Accounts Were Hacked Using 'Cookie Forging Attack'
Yahoo has just revealed that around 32 million user accounts were accessed by hackers in the last two years using a sophisticated cookie forging attack without any password. These compromised accounts are in addition to the Yahoo accounts affected by the two massive data breaches that the company disclosed in last few months. The former tech giant said that in a regulatory filing Wednesday

from The Hacker News http://ift.tt/2lWJxyP
via IFTTT
from The Hacker News http://ift.tt/2lWJxyP
via IFTTT
A Solar Eclipse with a Beaded Ring of Fire

What kind of eclipse is this? On Sunday, visible in parts of Earth's southern hemisphere, the Moon blocked part of the Sun during a partial solar eclipse. In some locations, though, the effect was a rare type of partial eclipse called an annular eclipse. There, since the Moon is too far from the Earth to block the entire Sun, sunlight streamed around the edges of the Moon creating a "ring of fire". At some times, though, the effect was a rare type of annular eclipse. Then, an edge of the Moon nearly aligned with an edge of the Sun, allowing sunlight to stream through only low areas on the Moon. Called a "Baily's bead" or a "diamond ring", this doubly rare effect was captured Sunday in the feature photograph from Chubut, Argentina, in South America. This summer a total solar eclipse will swoop across North America. via NASA http://ift.tt/2m80EhH
Wednesday, March 1, 2017
I have a new follower on Twitter
Ade Odutola
Founder & MD @solvitursystems #entrepreneur #cybersecurity #cloud #healthIT #FinTech #IoT #payments #startups Follow/RT/Fav ≠ endorsement Tweets are all mine
https://t.co/Z84rbvmLhd
Following: 11261 - Followers: 13947
March 01, 2017 at 09:58PM via Twitter http://twitter.com/odutola
Provable Optimal Algorithms for Generalized Linear Contextual Bandits. (arXiv:1703.00048v1 [cs.LG])
Contextual bandits are widely used in Internet services from news recommendation to advertising. Generalized linear models (logistical regression in particular) have demonstrated stronger performance than linear models in many applications. However, most theoretical analyses on contextual bandits so far are on linear bandits. In this work, we propose an upper confidence bound based algorithm for generalized linear contextual bandits, which achieves an $\tilde{O}(\sqrt{dT})$ regret over $T$ rounds with $d$ dimensional feature vectors. This regret matches the minimax lower bound, up to logarithmic terms, and improves on the best previous result by a $\sqrt{d}$ factor, assuming the number of arms is fixed. A key component in our analysis is to establish a new, sharp finite-sample confidence bound for maximum-likelihood estimates in generalized linear models, which may be of independent interest. We also analyze a simpler upper confidence bound algorithm, which is useful in practice, and prove it to have optimal regret for the certain cases.
from cs.AI updates on arXiv.org http://ift.tt/2mMUu3p
via IFTTT
Learning Conversational Systems that Interleave Task and Non-Task Content. (arXiv:1703.00099v1 [cs.CL])
Task-oriented dialog systems have been applied in various tasks, such as automated personal assistants, customer service providers and tutors. These systems work well when users have clear and explicit intentions that are well-aligned to the systems' capabilities. However, they fail if users intentions are not explicit. To address this shortcoming, we propose a framework to interleave non-task content (i.e. everyday social conversation) into task conversations. When the task content fails, the system can still keep the user engaged with the non-task content. We trained a policy using reinforcement learning algorithms to promote long-turn conversation coherence and consistency, so that the system can have smooth transitions between task and non-task content. To test the effectiveness of the proposed framework, we developed a movie promotion dialog system. Experiments with human users indicate that a system that interleaves social and task content achieves a better task success rate and is also rated as more engaging compared to a pure task-oriented system.
from cs.AI updates on arXiv.org http://ift.tt/2lB4uMY
via IFTTT
Learning A Physical Long-term Predictor. (arXiv:1703.00247v1 [cs.AI])
Evolution has resulted in highly developed abilities in many natural intelligences to quickly and accurately predict mechanical phenomena. Humans have successfully developed laws of physics to abstract and model such mechanical phenomena. In the context of artificial intelligence, a recent line of work has focused on estimating physical parameters based on sensory data and use them in physical simulators to make long-term predictions. In contrast, we investigate the effectiveness of a single neural network for end-to-end long-term prediction of mechanical phenomena. Based on extensive evaluation, we demonstrate that such networks can outperform alternate approaches having even access to ground-truth physical simulators, especially when some physical parameters are unobserved or not known a-priori. Further, our network outputs a distribution of outcomes to capture the inherent uncertainty in the data. Our approach demonstrates for the first time the possibility of making actionable long-term predictions from sensor data without requiring to explicitly model the underlying physical laws.
from cs.AI updates on arXiv.org http://ift.tt/2mHbpoQ
via IFTTT
Tracing Linguistic Relations in Winning and Losing Sides of Explicit Opposing Groups. (arXiv:1703.00317v1 [cs.CL])
Linguistic relations in oral conversations present how opinions are constructed and developed in a restricted time. The relations bond ideas, arguments, thoughts, and feelings, re-shape them during a speech, and finally build knowledge out of all information provided in the conversation. Speakers share a common interest to discuss. It is expected that each speaker's reply includes duplicated forms of words from previous speakers. However, linguistic adaptation is observed and evolves in a more complex path than just transferring slightly modified versions of common concepts. A conversation aiming a benefit at the end shows an emergent cooperation inducing the adaptation. Not only cooperation, but also competition drives the adaptation or an opposite scenario and one can capture the dynamic process by tracking how the concepts are linguistically linked. To uncover salient complex dynamic events in verbal communications, we attempt to discover self-organized linguistic relations hidden in a conversation with explicitly stated winners and losers. We examine open access data of the United States Supreme Court. Our understanding is crucial in big data research to guide how transition states in opinion mining and decision-making should be modeled and how this required knowledge to guide the model should be pinpointed, by filtering large amount of data.
from cs.AI updates on arXiv.org http://ift.tt/2lBce1R
via IFTTT
Investigating the Characteristics of One-Sided Matching Mechanisms Under Various Preferences and Risk Attitudes. (arXiv:1703.00320v1 [cs.GT])
One-sided matching mechanisms are fundamental for assigning a set of indivisible objects to a set of self-interested agents when monetary transfers are not allowed. Two widely-studied randomized mechanisms in multiagent settings are the Random Serial Dictatorship (RSD) and the Probabilistic Serial Rule (PS). Both mechanisms require only that agents specify ordinal preferences and have a number of desirable economic and computational properties. However, the induced outcomes of the mechanisms are often incomparable and thus there are challenges when it comes to deciding which mechanism to adopt in practice. In this paper, we first consider the space of general ordinal preferences and provide empirical results on the (in)comparability of RSD and PS. We analyze their respective economic properties under general and lexicographic preferences. We then instantiate utility functions with the goal of gaining insights on the manipulability, efficiency, and envyfreeness of the mechanisms under different risk-attitude models. Our results hold under various preference distribution models, which further confirm the broad use of RSD in most practical applications.
from cs.AI updates on arXiv.org http://ift.tt/2mfZqRM
via IFTTT
Do Reichenbachian Common Cause Systems of Arbitrary Finite Size Exist?. (arXiv:1703.00352v1 [stat.OT])
The principle of common cause asserts that positive correlations between causally unrelated events ought to be explained through the action of some shared causal factors. Reichenbachian common cause systems are probabilistic structures aimed at accounting for cases where correlations of the aforesaid sort cannot be explained through the action of a single common cause. The existence of Reichenbachian common cause systems of arbitrary finite size for each pair of non-causally correlated events was allegedly demonstrated by Hofer-Szab\'o and R\'edei in 2006. This paper shows that their proof is logically deficient, and we propose an improved proof.
from cs.AI updates on arXiv.org http://ift.tt/2mvqzAY
via IFTTT
The Statistical Recurrent Unit. (arXiv:1703.00381v1 [cs.LG])
Sophisticated gated recurrent neural network architectures like LSTMs and GRUs have been shown to be highly effective in a myriad of applications. We develop an un-gated unit, the statistical recurrent unit (SRU), that is able to learn long term dependencies in data by only keeping moving averages of statistics. The SRU's architecture is simple, un-gated, and contains a comparable number of parameters to LSTMs; yet, SRUs perform favorably to more sophisticated LSTM and GRU alternatives, often outperforming one or both in various tasks. We show the efficacy of SRUs as compared to LSTMs and GRUs in an unbiased manner by optimizing respective architectures' hyperparameters in a Bayesian optimization scheme for both synthetic and real-world tasks.
from cs.AI updates on arXiv.org http://ift.tt/2mMQjF0
via IFTTT
A Hypercat-enabled Semantic Internet of Things Data Hub: Technical Report. (arXiv:1703.00391v1 [cs.AI])
An increasing amount of information is generated from the rapidly increasing number of sensor networks and smart devices. A wide variety of sources generate and publish information in different formats, thus highlighting interoperability as one of the key prerequisites for the success of Internet of Things (IoT). The BT Hypercat Data Hub provides a focal point for the sharing and consumption of available datasets from a wide range of sources. In this work, we propose a semantic enrichment of the BT Hypercat Data Hub, using well-accepted Semantic Web standards and tools. We propose an ontology that captures the semantics of the imported data and present the BT SPARQL Endpoint by means of a mapping between SPARQL and SQL queries. Furthermore, federated SPARQL queries allow queries over multiple hub-based and external data sources. Finally, we provide two use cases in order to illustrate the advantages afforded by our semantic approach.
from cs.AI updates on arXiv.org http://ift.tt/2ltTd0r
via IFTTT
Virtual-to-real Deep Reinforcement Learning: Continuous Control of Mobile Robots for Mapless Navigation. (arXiv:1703.00420v1 [cs.RO])
Deep Reinforcement Learning has been successful in various virtual tasks, but it is still rarely used in real world applications especially for continuous control of mobile robots navigation. In this paper, we present a learning-based mapless motion planner by taking the 10-dimensional range findings and the target position as input and the continuous steering commands as output. Traditional motion planners for mobile ground robots with a laser range sensor mostly depend on the map of the navigation environment where both the highly precise laser sensor and the map building work of the environment are indispensable. We show that, through an asynchronous deep reinforcement learning method, a mapless motion planner can be trained end-to-end without any manually designed features and prior demonstrations. The trained planner can be directly applied in unseen virtual and real environments. We also evaluated this learning-based motion planner and compared it with the traditional motion planning method, both in virtual and real environments. The experiments show that the proposed mapless motion planner can navigate the nonholonomic mobile robot to the desired targets without colliding with any obstacles.
from cs.AI updates on arXiv.org http://ift.tt/2mHm2YY
via IFTTT
HolStep: A Machine Learning Dataset for Higher-order Logic Theorem Proving. (arXiv:1703.00426v1 [cs.AI])
Large computer-understandable proofs consist of millions of intermediate logical steps. The vast majority of such steps originate from manually selected and manually guided heuristics applied to intermediate goals. So far, machine learning has generally not been used to filter or generate these steps. In this paper, we introduce a new dataset based on Higher-Order Logic (HOL) proofs, for the purpose of developing new machine learning-based theorem-proving strategies. We make this dataset publicly available under the BSD license. We propose various machine learning tasks that can be performed on this dataset, and discuss their significance for theorem proving. We also benchmark a set of simple baseline machine learning models suited for the tasks (including logistic regression, convolutional neural networks and recurrent neural networks). The results of our baseline models show the promise of applying machine learning to HOL theorem proving.
from cs.AI updates on arXiv.org http://ift.tt/2mgbzq9
via IFTTT
Fast k-Nearest Neighbour Search via Prioritized DCI. (arXiv:1703.00440v1 [cs.LG])
Most exact methods for k-nearest neighbour search suffer from the curse of dimensionality; that is, their query times exhibit exponential dependence on either the ambient or the intrinsic dimensionality. Dynamic Continuous Indexing (DCI) offers a promising way of circumventing the curse by avoiding space partitioning and achieves a query time that grows sublinearly in the intrinsic dimensionality. In this paper, we develop a variant of DCI, which we call Prioritized DCI, and show a further improvement in the dependence on the intrinsic dimensionality compared to standard DCI, thereby improving the performance of DCI on datasets with high intrinsic dimensionality. We also demonstrate empirically that Prioritized DCI compares favourably to standard DCI and Locality-Sensitive Hashing (LSH) both in terms of running time and space consumption at all levels of approximation quality. In particular, relative to LSH, Prioritized DCI reduces the number of distance evaluations by a factor of 5 to 30 and the space consumption by a factor of 47 to 55.
from cs.AI updates on arXiv.org http://ift.tt/2mMVfK3
via IFTTT
Learning to Optimize Neural Nets. (arXiv:1703.00441v1 [cs.LG])
Learning to Optimize is a recently proposed framework for learning optimization algorithms using reinforcement learning. In this paper, we explore learning an optimization algorithm for training shallow neural nets. Such high-dimensional stochastic optimization problems present interesting challenges for existing reinforcement learning algorithms. We develop an extension that is suited to learning optimization algorithms in this setting and demonstrate that the learned optimization algorithm consistently outperforms other known optimization algorithms even on unseen tasks and is robust to changes in stochasticity of gradients and the neural net architecture. More specifically, we show that an optimization algorithm trained with the proposed method on the problem of training a neural net on MNIST generalizes to the problems of training neural nets on the Toronto Faces Dataset, CIFAR-10 and CIFAR-100.
from cs.AI updates on arXiv.org http://ift.tt/2mgeP4N
via IFTTT
OptNet: Differentiable Optimization as a Layer in Neural Networks. (arXiv:1703.00443v1 [cs.LG])
This paper presents OptNet, a network architecture that integrates optimization problems (here, specifically in the form of quadratic programs) as individual layers in larger end-to-end trainable deep networks. These layers allow complex dependencies between the hidden states to be captured that traditional convolutional and fully-connected layers are not able to capture. In this paper, we develop the foundations for such an architecture: we derive the equations to perform exact differentiation through these layers and with respect to layer parameters; we develop a highly efficient solver for these layers that exploits fast GPU-based batch solves within a primal-dual interior point method, and which provides backpropagation gradients with virtually no additional cost on top of the solve; and we highlight the application of these approaches in several problems. In one particularly standout example, we show that the method is capable of learning to play Sudoku given just input and output games, with no a priori information about the rules of the game; this task is virtually impossible for other neural network architectures that we have experimented with, and highlights the representation capabilities of our approach.
from cs.AI updates on arXiv.org http://ift.tt/2mMMejY
via IFTTT
Building and Measuring Privacy-Preserving Predictive Blacklists. (arXiv:1512.04114v4 [cs.CR] UPDATED)
Collaborative security initiatives are increasingly often advocated to improve timeliness and effectiveness of threat mitigation. Among these, collaborative predictive blacklisting (CPB) aims to forecast attack sources based on alerts contributed by multiple organizations that might be targeted in similar ways. Alas, CPB proposals thus far have only focused on improving hit counts, but overlooked the impact of collaboration on false positives and false negatives. Moreover, sharing threat intelligence often prompts important privacy, confidentiality, and liability issues. In this paper, we first provide a comprehensive measurement analysis of two state-of-the-art CPB systems: one that uses a trusted central party to collect alerts [Soldo et al., Infocom'10] and a peer-to-peer one relying on controlled data sharing [Freudiger et al., DIMVA'15], studying the impact of collaboration on both correct and incorrect predictions. Then, we present a novel privacy-friendly approach that significantly improves over previous work, achieving a better balance of true and false positive rates, while minimizing information disclosure. Finally, we present an extension that allows our system to scale to very large numbers of organizations.
from cs.AI updates on arXiv.org http://ift.tt/1NtM7Aq
via IFTTT
A Motion Planning Strategy for the Active Vision-Based Mapping of Ground-Level Structures. (arXiv:1602.06667v2 [cs.RO] UPDATED)
This paper presents a strategy to guide a mobile ground robot equipped with a camera or depth sensor, in order to autonomously map the visible part of a bounded three-dimensional structure. We describe motion planning algorithms that determine appropriate successive viewpoints and attempt to fill holes automatically in a point cloud produced by the sensing and perception layer. The emphasis is on accurately reconstructing a 3D model of a structure of moderate size rather than mapping large open environments, with applications for example in architecture, construction and inspection. The proposed algorithms do not require any initialization in the form of a mesh model or a bounding box, and the paths generated are well adapted to situations where the vision sensor is used simultaneously for mapping and for localizing the robot, in the absence of additional absolute positioning system. We analyze the coverage properties of our policy, and compare its performance to the classic frontier based exploration algorithm. We illustrate its efficacy for different structure sizes, levels of localization accuracy and range of the depth sensor, and validate our design on a real-world experiment.
from cs.AI updates on arXiv.org http://ift.tt/1Qd82k8
via IFTTT
A Comprehensive Performance Evaluation of Deformable Face Tracking "In-the-Wild". (arXiv:1603.06015v2 [cs.CV] UPDATED)
Recently, technologies such as face detection, facial landmark localisation and face recognition and verification have matured enough to provide effective and efficient solutions for imagery captured under arbitrary conditions (referred to as "in-the-wild"). This is partially attributed to the fact that comprehensive "in-the-wild" benchmarks have been developed for face detection, landmark localisation and recognition/verification. A very important technology that has not been thoroughly evaluated yet is deformable face tracking "in-the-wild". Until now, the performance has mainly been assessed qualitatively by visually assessing the result of a deformable face tracking technology on short videos. In this paper, we perform the first, to the best of our knowledge, thorough evaluation of state-of-the-art deformable face tracking pipelines using the recently introduced 300VW benchmark. We evaluate many different architectures focusing mainly on the task of on-line deformable face tracking. In particular, we compare the following general strategies: (a) generic face detection plus generic facial landmark localisation, (b) generic model free tracking plus generic facial landmark localisation, as well as (c) hybrid approaches using state-of-the-art face detection, model free tracking and facial landmark localisation technologies. Our evaluation reveals future avenues for further research on the topic.
from cs.AI updates on arXiv.org http://ift.tt/1XIClju
via IFTTT
A Hierarchical Genetic Optimization of a Fuzzy Logic System for Flow Control in Micro Grids. (arXiv:1604.04789v3 [cs.AI] UPDATED)
Bio-inspired algorithms like Genetic Algorithms and Fuzzy Inference Systems (FIS) are nowadays widely adopted as hybrid techniques in commercial and industrial environment. In this paper we present an interesting application of the fuzzy-GA paradigm to Smart Grids. The main aim consists in performing decision making for power flow management tasks in the proposed microgrid model equipped by renewable sources and an energy storage system, taking into account the economical profit in energy trading with the main-grid. In particular, this study focuses on the application of a Hierarchical Genetic Algorithm (HGA) for tuning the Rule Base (RB) of a Fuzzy Inference System (FIS), trying to discover a minimal fuzzy rules set in a Fuzzy Logic Controller (FLC) adopted to perform decision making in the microgrid. The HGA rationale focuses on a particular encoding scheme, based on control genes and parametric genes applied to the optimization of the FIS parameters, allowing to perform a reduction in the structural complexity of the RB. This approach will be referred in the following as fuzzy-HGA. Results are compared with a simpler approach based on a classic fuzzy-GA scheme, where both FIS parameters and rule weights are tuned, while the number of fuzzy rules is fixed in advance. Experiments shows how the fuzzy-HGA approach adopted for the synthesis of the proposed controller outperforms the classic fuzzy-GA scheme, increasing the accounting profit by 67\% in the considered energy trading problem yielding at the same time a simpler RB.
from cs.AI updates on arXiv.org http://ift.tt/1Vf09ya
via IFTTT
Deep Predictive Coding Networks for Video Prediction and Unsupervised Learning. (arXiv:1605.08104v5 [cs.LG] UPDATED)
While great strides have been made in using deep learning algorithms to solve supervised learning tasks, the problem of unsupervised learning - leveraging unlabeled examples to learn about the structure of a domain - remains a difficult unsolved challenge. Here, we explore prediction of future frames in a video sequence as an unsupervised learning rule for learning about the structure of the visual world. We describe a predictive neural network ("PredNet") architecture that is inspired by the concept of "predictive coding" from the neuroscience literature. These networks learn to predict future frames in a video sequence, with each layer in the network making local predictions and only forwarding deviations from those predictions to subsequent network layers. We show that these networks are able to robustly learn to predict the movement of synthetic (rendered) objects, and that in doing so, the networks learn internal representations that are useful for decoding latent object parameters (e.g. pose) that support object recognition with fewer training views. We also show that these networks can scale to complex natural image streams (car-mounted camera videos), capturing key aspects of both egocentric movement and the movement of objects in the visual scene, and the representation learned in this setting is useful for estimating the steering angle. Altogether, these results suggest that prediction represents a powerful framework for unsupervised learning, allowing for implicit learning of object and scene structure.
from cs.AI updates on arXiv.org http://ift.tt/1sdSBj0
via IFTTT
Estimating individual treatment effect: generalization bounds and algorithms. (arXiv:1606.03976v4 [stat.ML] UPDATED)
There is intense interest in applying machine learning to problems of causal inference in fields such as healthcare, economics and education. In particular, individual-level causal inference has important applications such as precision medicine. We give a new theoretical analysis and family of algorithms for predicting individual treatment effect (ITE) from observational data, under the assumption known as strong ignorability. The algorithms learn a "balanced" representation such that the induced treated and control distributions look similar. We give a novel, simple and intuitive generalization-error bound showing that the expected ITE estimation error of a representation is bounded by a sum of the standard generalization-error of that representation and the distance between the treated and control distributions induced by the representation. We use Integral Probability Metrics to measure distances between distributions, deriving explicit bounds for the Wasserstein and Maximum Mean Discrepancy (MMD) distances. Experiments on real and simulated data show the new algorithms match or outperform the state-of-the-art.
from cs.AI updates on arXiv.org http://ift.tt/1UwrExD
via IFTTT
On the Expressive Power of Deep Neural Networks. (arXiv:1606.05336v5 [stat.ML] UPDATED)
We propose a novel approach to the problem of neural network expressivity, which seeks to characterize how structural properties of a neural network family affect the functions it is able to compute. Understanding expressivity is a classical issue in the study of neural networks, but it has remained challenging at both a conceptual and a practical level. Our approach is based on an interrelated set of measures of expressivity, unified by the novel notion of trajectory length, which measures how the output of a network changes as the input sweeps along a one-dimensional path. We show how our framework provides insight both into randomly initialized networks (the starting point for most standard optimization methods) and for trained networks. Our findings can be summarized as follows:
(1) The complexity of the computed function grows exponentially with depth. We design measures of expressivity that capture the non-linearity of the computed function. These measures grow exponentially with the depth of the network architecture, due to the way the network transforms its input.
(2) All weights are not equal (initial layers matter more). We find that trained networks are far more sensitive to their lower (initial) layer weights: they are much less robust to noise in these layer weights, and also perform better when these weights are optimized well.
from cs.AI updates on arXiv.org http://ift.tt/1tznj7m
via IFTTT
Unifying task specification in reinforcement learning. (arXiv:1609.01995v2 [cs.AI] UPDATED)
Reinforcement learning tasks are typically specified as Markov decision processes. This formalism has been highly successful, though specifications often couple the dynamics of the environment and the learning objective. This lack of modularity can complicate generalization of the task specification, as well as obfuscate connections between different task settings, such as episodic and continuing. In this work, we introduce the RL task formalism, that provides a unification through simple constructs including a generalization to transition-based discounting. Through a series of examples, we demonstrate the generality and utility of this formalism. Finally, we extend standard learning constructs, including Bellman operators, and extend some seminal theoretical results, including approximation errors bounds. Overall, we provide a well-understood and sound formalism on which to build theoretical results and simplify algorithm use and development.
from cs.AI updates on arXiv.org http://ift.tt/2c8rGgQ
via IFTTT
Visual Question Answering: Datasets, Algorithms, and Future Challenges. (arXiv:1610.01465v3 [cs.CV] UPDATED)
Visual Question Answering (VQA) is a recent problem in computer vision and natural language processing that has garnered a large amount of interest from the deep learning, computer vision, and natural language processing communities. In VQA, an algorithm needs to answer text-based questions about images. Since the release of the first VQA dataset in 2014, additional datasets have been released and many algorithms have been proposed. In this review, we critically examine the current state of VQA in terms of problem formulation, existing datasets, evaluation metrics, and algorithms. In particular, we discuss the limitations of current datasets with regard to their ability to properly train and assess VQA algorithms. We then exhaustively review existing algorithms for VQA. Finally, we discuss possible future directions for VQA and image understanding research.
from cs.AI updates on arXiv.org http://ift.tt/2cUI3xg
via IFTTT
Transferring Vision-based Robotic Reaching Skills from Simulation to Real World. (arXiv:1610.06781v2 [cs.RO] UPDATED)
This paper describes a deep network architecture that maps visual input to control actions for a robotic planar reaching task with an average accuracy of 2.6 pixels in 20 real-world trials. The network is trained in simulation and fine-tuned by a limited number of real-world images. To facilitate successful and fast transfer of deep visuomotor policies to real world settings we introduce a bottleneck between perception and control, allowing the networks to be trained independently.
from cs.AI updates on arXiv.org http://ift.tt/2em31Mk
via IFTTT
Flexible constrained sampling with guarantees for pattern mining. (arXiv:1610.09263v2 [cs.AI] UPDATED)
Pattern sampling has been proposed as a potential solution to the infamous pattern explosion. Instead of enumerating all patterns that satisfy the constraints, individual patterns are sampled proportional to a given quality measure. Several sampling algorithms have been proposed, but each of them has its limitations when it comes to 1) flexibility in terms of quality measures and constraints that can be used, and/or 2) guarantees with respect to sampling accuracy. We therefore present Flexics, the first flexible pattern sampler that supports a broad class of quality measures and constraints, while providing strong guarantees regarding sampling accuracy. To achieve this, we leverage the perspective on pattern mining as a constraint satisfaction problem and build upon the latest advances in sampling solutions in SAT as well as existing pattern mining algorithms. Furthermore, the proposed algorithm is applicable to a variety of pattern languages, which allows us to introduce and tackle the novel task of sampling sets of patterns. We introduce and empirically evaluate two variants of Flexics: 1) a generic variant that addresses the well-known itemset sampling task and the novel pattern set sampling task as well as a wide range of expressive constraints within these tasks, and 2) a specialized variant that exploits existing frequent itemset techniques to achieve substantial speed-ups. Experiments show that Flexics is both accurate and efficient, making it a useful tool for pattern-based data exploration.
from cs.AI updates on arXiv.org http://ift.tt/2fuEfIP
via IFTTT
Capacity and Trainability in Recurrent Neural Networks. (arXiv:1611.09913v2 [stat.ML] UPDATED)
Two potential bottlenecks on the expressiveness of recurrent neural networks (RNNs) are their ability to store information about the task in their parameters, and to store information about the input history in their units. We show experimentally that all common RNN architectures achieve nearly the same per-task and per-unit capacity bounds with careful training, for a variety of tasks and stacking depths. They can store an amount of task information which is linear in the number of parameters, and is approximately 5 bits per parameter. They can additionally store approximately one real number from their input history per hidden unit. We further find that for several tasks it is the per-task parameter capacity bound that determines performance. These results suggest that many previous results comparing RNN architectures are driven primarily by differences in training effectiveness, rather than differences in capacity. Supporting this observation, we compare training difficulty for several architectures, and show that vanilla RNNs are far more difficult to train, yet have higher capacity. Finally, we propose two novel RNN architectures, one of which is easier to train than the LSTM or GRU.
from cs.AI updates on arXiv.org http://ift.tt/2gzTLjU
via IFTTT
Reasoning in Non-Probabilistic Uncertainty: Logic Programming and Neural-Symbolic Computing as Examples. (arXiv:1701.05226v2 [cs.AI] UPDATED)
This article aims to achieve two goals: to show that probability is not the only way of dealing with uncertainty (and even more, that there are kinds of uncertainty which are for principled reasons not addressable with probabilistic means); and to provide evidence that logic-based methods can well support reasoning with uncertainty. For the latter claim, two paradigmatic examples are presented: Logic Programming with Kleene semantics for modelling reasoning from information in a discourse, to an interpretation of the state of affairs of the intended model, and a neural-symbolic implementation of Input/Output logic for dealing with uncertainty in dynamic normative contexts.
from cs.AI updates on arXiv.org http://ift.tt/2iHuVDE
via IFTTT
Borrowing Treasures from the Wealthy: Deep Transfer Learning through Selective Joint Fine-tuning. (arXiv:1702.08690v1 [cs.CV])
Deep neural networks require a large amount of labeled training data during supervised learning. However, collecting and labeling so much data might be infeasible in many cases. In this paper, we introduce a source-target selective joint fine-tuning scheme for improving the performance of deep learning tasks with insufficient training data. In this scheme, a target learning task with insufficient training data is carried out simultaneously with another source learning task with abundant training data. However, the source learning task does not use all existing training data. Our core idea is to identify and use a subset of training images from the original source learning task whose low-level characteristics are similar to those from the target learning task, and jointly fine-tune shared convolutional layers for both tasks. Specifically, we compute descriptors from linear or nonlinear filter bank responses on training images from both tasks, and use such descriptors to search for a desired subset of training samples for the source learning task.
Experiments demonstrate that our selective joint fine-tuning scheme achieves state-of-the-art performance on multiple visual classification tasks with insufficient training data for deep learning. Such tasks include Caltech 256, MIT Indoor 67, Oxford Flowers 102 and Stanford Dogs 120. In comparison to fine-tuning without a source domain, the proposed method can improve the classification accuracy by 2% - 10% using a single model.
from cs.AI updates on arXiv.org http://ift.tt/2l9qhzz
via IFTTT
Analysing Congestion Problems in Multi-agent Reinforcement Learning. (arXiv:1702.08736v1 [cs.MA])
Congestion problems are omnipresent in today's complex networks and represent a challenge in many research domains. In the context of Multi-agent Reinforcement Learning (MARL), approaches like difference rewards and resource abstraction have shown promising results in tackling such problems. Resource abstraction was shown to be an ideal candidate for solving large-scale resource allocation problems in a fully decentralized manner. However, its performance and applicability strongly depends on some, until now, undocumented assumptions. Two of the main congestion benchmark problems considered in the literature are: the Beach Problem Domain and the Traffic Lane Domain. In both settings the highest system utility is achieved when overcrowding one resource and keeping the rest at optimum capacity. We analyse how abstract grouping can promote this behaviour and how feasible it is to apply this approach in a real-world domain (i.e., what assumptions need to be satisfied and what knowledge is necessary). We introduce a new test problem, the Road Network Domain (RND), where the resources are no longer independent, but rather part of a network (e.g., road network), thus choosing one path will also impact the load on other paths having common road segments. We demonstrate the application of state-of-the-art MARL methods for this new congestion model and analyse their performance. RND allows us to highlight an important limitation of resource abstraction and show that the difference rewards approach manages to better capture and inform the agents about the dynamics of the environment.
from cs.AI updates on arXiv.org http://ift.tt/2ltIhzL
via IFTTT
Alcoholics Anonymous (AA)
Alcoholics Anonymous (AA) meetings on campus are: Wednesdays, 7:00 PM - 3rd Fl. Hammes-Mowbray Hall. Fridays, 12:00 PM - Room 215, The ...
from Google Alert - anonymous http://ift.tt/2mg18mk
via IFTTT
from Google Alert - anonymous http://ift.tt/2mg18mk
via IFTTT
anonymous-gist.rb
module LineProfile. def run *a. report_profile lineprof(/./) {. super. } end. def report_profile profile. file = profile.keys.first.
from Google Alert - anonymous http://ift.tt/2mMClCQ
via IFTTT
from Google Alert - anonymous http://ift.tt/2mMClCQ
via IFTTT
Did Trump Act As An Anonymous Source
Now it appears that Trump may have become his own anonymous source. According to the NY Daily News, on Tuesday before his speech ,a report ...
from Google Alert - anonymous http://ift.tt/2mg482h
via IFTTT
from Google Alert - anonymous http://ift.tt/2mg482h
via IFTTT
Trump Acts as an Anonymous Source After Complaining About Anonymous Sources
Of course, the story that Trump was an anonymous source is based on . . . an anonymous source. So we have to keep our skeptical hats on as we ...
from Google Alert - anonymous http://ift.tt/2mMYfGd
via IFTTT
from Google Alert - anonymous http://ift.tt/2mMYfGd
via IFTTT
Ravens will not use franchise tag on NT Brandon Williams; designation would've cost $14.7 million (ESPN)
from ESPN http://ift.tt/17lH5T2
via IFTTT
via IFTTT
ISS Daily Summary Report – 2/28/2017
Lab Carbon Dioxide Removal Assembly (CDRA) Maintenance: The adsorbent material (Zeolite) inside the CDRA beds breaks down over time and creates dust. This dust eventually reduces airflow through the beds to the point where CDRA can no longer operate. The Node 3 CDRA has newer generation beds that can be disassembled and serviced on orbit. The Lab CDRA, however, still has older generation beds that cannot be serviced on orbit and are near end of life. Today, the crew removed Lab CDRA from the rack, and disassembled it by removing all of the valves and ducting to access the beds. During the removal of the CDRA from the rack, the original power cable (P12) that connects the ASVs to the Remote Power Control Module (RPCM) was left mated in one location and the cable was severed. Teams are looking into the issue. The crew also removed the old beds from Lab CDRA. Lab CDRA will be left in this configuration overnight. Tomorrow, the crew will replace the beds with the newer generation beds, like those in Node 3 CDRA. Extravehicular Mobility Unit (EMU) Suit Maintenance: The crew performed routine maintenance tasks on EMU 3003 and EMU 3010 including a loop scrub, a post-loop scrub water sample, suit and ion filter iodination and an EMU conductivity test. Rodent Research Status Check: This morning, the crew conducted a conference with ground teams then collected necessary equipment for tomorrow’s Habitat Restocking activities. The Tissue Regeneration-Bone Defect (RR-4) studies what prevents vertebrates such as rodents and humans from regrowing lost bone and tissue, and how the microgravity extraterrestrial condition impacts the process. Results could lead to tissue regeneration efforts in space and a better understanding of limitations of limb regrowth at wound sites. Microgravity Expanded Stem Cells (MESC) Microscope Operations: The crew removed a BioCell from the Space Automated Bioproduct Laboratory-2 (SABL2) and placed it on the microscope stage configured outside the Microgravity Science Glovebox (MSG). The crew worked with ground specialist to image areas of the BioCell plate. Following the focused imaging, the crew reinserted the BioCell back into the SABL. MESC will aid researches determine the efficiency of using a microgravity environment to accelerate expansion (replication) of stem cells for use in terrestrial clinical trials for treatment of disease. Mobile Servicing System (MSS) Operations: Overnight, the Robotics Ground Controllers maneuvered the Space Station Remote Manipulator System (SSRMS) and Special Purpose Dexterous Manipulator (SPDM) to stow the Optical PAyload for Lasercomm Science (OPALS) on the SPDM Enhanced Orbital Replacement Unit (ORU) Temporary Platform (EOTP). They then handed the Space Test Program – Houston 5 (STP-H5) payload from SPDM Arm 2 to Arm 1. This was done to switch from having Orbital Replaceable Unit (ORU) Tool Changeout Mechanism 2 (OTCM2) providing keep alive power to the STP-H5 to having OTCM1 grasping the STP-H5 Flight Releasable Attachment Mechanism (FRAM) so that the STP-H5 could be installed on EXpedite the PRocessing of Experiments to Space Station (EXPRESS) Logistics Carrier 1 (ELC1). After the STP-H5 had been installed, the SSRMS and SPDM were maneuvered to a Mobile Transporter (MT) translation configuration. MSS performance was nominal. Space Test Program – Houston 5 (STP-H5) Activation: The STP-H5 payload was installed on ELC-1 and successfully activated, one day earlier than originally planned. Initial data indicates that the STP-H5 equipment is healthy. Activation of individual experiment packages is ongoing. STP-H5 is an EXpedite PRocessing of Experiments to Space Station (EXPRESS) Pallet Adapter Flight Releasable Attachment Mechanism (ExPA-FRAM) based payload consisting of 13 individual experiments ranging from technology demonstrations to space and terrestrial weather measuring and monitoring. The experiments are provided and operated by the Department of Defense (DoD) and NASA agencies. Today’s Planned Activities All activities were completed unless otherwise noted. BIOPLENKA. Removal of Samples from the Thermostat, fixation of Constanta cassette No.1-2 biofilm. MICROVIR. Removal of Cassette-M No.2-3 and No.2-4 from ТБУ-В No.04 and setup on interior panel. Photography Virus Definition File Update on Auxiliary Computer System (ВКС) Laptops MICROVIR. Photography of upper cell content. Squeezing out and photography of Cassette-M No.№2-3, No.2-4 bottom cells. Setup in Cryogem-03 at +37 deg C Rodent Research Water Box and Light Check COLUMBUS Bay 4 clean-up ENERGY Big Picture Words Reading Verification of ИП-1 Flow Indicator Position Extravehicular Mobility Unit (EMU) Cooling Loop Maintenance Scrub Initiation Carbon Dioxide Removal Assembly (CDRA) Troubleshooting Cable Deconfiguration MICROVIR. Glovebox-S Closeout Ops COSMOCARD. Closeout Ops MICROVIR. Photography of Cassette-M lower cells No.2-1, No.2-2 and stowage in ТБУ-В No.04 at +4°С Habitability Narrated Task Video Setup – Subject ENERGY Equipment Pre-gather Rodent Research Gather 1 Habitability Narrated Task Video End – Subject MICROVIR. Photography of bottom cells Microscope Hardware Unstow Extravehicular Mobility Unit (EMU) Post Scrub Cooling Loop Water (H2O) Sample Scheduled monthly maintenance of Central Post Laptop. Laptop Log-File Downlink Microgravity Expanded Stem Cells Microscope Ops Extravehicular Mobility Unit (EMU) Cooling Loop Maintenance Iodination СКПФ1, СКПФ2 Dust Filter Replacement and MRM1 ГЖТ Cleaning Lab Carbon Dioxide Removal Assembly (CDRA) Removal for Dual Bed Replacement MICROVIR. Photography of bottom cells Microscope Hardware Temporary Stowage BIOPLENKA. Removal of Samples from the Thermostat, fixation of Constanta cassette No.1-3 biofilm. EVA Extravehicular Mobility Unit (EMU) Cooling Loop Scrub Deconfiguration СОЖ maintenance IMS Update APEX-04 Petri Plate Photo Extravehicular Mobility Unit (EMU) Conductivity Test Photo/TV JEM Camcorder to SSC MICROVIR. Photography of bottom cells Photo/TV JEM MPEG Activation Carbon Dioxide Removal Assembly (CDRA) Component Removal CONTENT. Experiment Ops Bringing ODF up to date using Progress 435 delivered files Extravehicular Mobility Unit (EMU) Swap Battery Stowage Assembly (BSA) Operation Initiation MICROVIR. Photography of cell condition. Start Video. Replacement of ПФ1, ПФ2 Dust Filters and Cleaning В1, B2 Fan Screens in MRM2 Lab Carbon Dioxide Removal Assembly (CDRA) Bed 201 and 202 Removal Onboard Training (OBT) Dragon Debrief Conference Photo/TV JEM Mpeg Deactivation Stow Syringes used in H2O Conductivity Test MICROVIR. Photography of cell condition. Terminate Video. See note 8 Completed Task List Items None Ground Activities All activities were completed unless otherwise noted. Capacity Test for Battery 1A2 MT Translation from WS7 […]
from ISS On-Orbit Status Report http://ift.tt/2mdzmqG
via IFTTT
from ISS On-Orbit Status Report http://ift.tt/2mdzmqG
via IFTTT
Dridex Banking Trojan Gains ‘AtomBombing’ Code Injection Ability to Evade Detection
Security researchers have discovered a new variant of Dridex – one of the most nefarious banking Trojans actively targeting financial sector – with a new, sophisticated code injection technique and evasive capabilities called "AtomBombing." On Tuesday, researchers with IBM X-Force disclosed new research, exposing the new Dridex version 4, which is the latest version of the infamous financial

from The Hacker News http://ift.tt/2lTiHYt
via IFTTT
from The Hacker News http://ift.tt/2lTiHYt
via IFTTT
I have a new follower on Twitter
@CrowdExposure
Visit https://t.co/HbD4reG1CZ today get your campaign promoted on Facebook 520,000+ & Twitter to 2,840,000+ Donors, Investors, & Angels
USA Canada UK EU Global
https://t.co/96a5bgsikm
Following: 95299 - Followers: 101740
March 01, 2017 at 08:08AM via Twitter http://twitter.com/CrowdExposure
THN Deal: Complete Linux Certification Training (Save 97%)
If you are also searching for the answers to what skills are needed for a job in cyber security, you should know that this varies widely based upon the responsibilities of a particular role, the type of company you want to work with, and especially on it’s IT architect. However, Linux is the most required skills in information technology and cyber security, as Linux are everywhere! Whether

from The Hacker News http://ift.tt/2lVJ9z1
via IFTTT
from The Hacker News http://ift.tt/2lVJ9z1
via IFTTT
9 Popular Password Manager Apps Found Leaking Your Secrets
Is anything safe? It's 2017, and the likely answer is NO. Making sure your passwords are secure is one of the first line of defense – for your computer, email, and information – against hacking attempts, and Password Managers are the one recommended by many security experts to keep all your passwords secure in one place. Password Managers are software that creates complex passwords, stores

from The Hacker News http://ift.tt/2mcQGMj
via IFTTT
from The Hacker News http://ift.tt/2mcQGMj
via IFTTT
[FD] SEC Consult SA-20170301 :: XXE and XSS vulnerabilities in Aruba AirWave
SEC Consult Vulnerability Lab Security Advisory < 20170301-0 > ======================================================================= title: XML External Entity Injection (XXE), Reflected Cross Site Scripting product: Aruba AirWave vulnerable version: <=8.2.3 fixed version: 8.2.3.1 CVE number: CVE-2016-8526, CVE-2016-8527 impact: high homepage: http://ift.tt/Xqtkz4 found: 2016-11-21 by: P. Morimoto (Office Bangkok) SEC Consult Vulnerability Lab An integrated part of SEC Consult Bangkok - Berlin - Linz - Luxembourg - Montreal - Moscow Kuala Lumpur - Singapore - Vienna (HQ) - Vilnius - Zurich http://ift.tt/1mGHMNR ======================================================================= Vendor description:
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
[InsideNothing] hitebook.net liked your post "[FD] Kajona 4.7: XSS & Directory Traversal"
|
Source: Gmail -> IFTTT-> Blogger
Subscribe to:
Posts (Atom)