Marcha Fúnebre Saudades (Anonymous). Free public domain sheet music from IMSLP / Petrucci Music Library. Jump to: navigation, search ...
from Google Alert - anonymous http://ift.tt/1Q61Dpj
via IFTTT
Saturday, January 16, 2016
Ravens: Ted Marchibroda, the only man to be head coach of both NFL franchises in Baltimore, dies at age 84 (ESPN)
from ESPN http://ift.tt/17lH5T2
via IFTTT
via IFTTT
Next Hacker to Organize Biggest Java Programming Competition In Germany
Great news for Hackers and Bug-hunters who enjoy Programming and playing around with Software. A worldwide group of like-minded computer programmers is hosting The Next Hacker IPPC event on the 26th and 27th of February in Berlin, Germany, where participants can meet hackers and programmers from around the world while getting an opportunity to participate in one of the major


from The Hacker News http://ift.tt/1PinsyL
via IFTTT
from The Hacker News http://ift.tt/1PinsyL
via IFTTT
Ocean City, MD's surf is Good
January 15, 2016 at 07:00PM, the surf is Good!
Ocean City, MD Summary
Surf: waist to shoulder high
Maximum: 1.224m (4.02ft)
Minimum: 0.918m (3.01ft)
Maryland-Delaware Summary
from Surfline http://ift.tt/1kVmigH
via IFTTT
Ocean City, MD Summary
Surf: waist to shoulder high
Maximum: 1.224m (4.02ft)
Minimum: 0.918m (3.01ft)
Maryland-Delaware Summary
from Surfline http://ift.tt/1kVmigH
via IFTTT
Approaches to anonymous feature engineering?
I'm just curious if any of you have any tips for engineering features when it comes to anonymous data. They don't even have to be specific to this ...
from Google Alert - anonymous http://ift.tt/1SUdZDB
via IFTTT
from Google Alert - anonymous http://ift.tt/1SUdZDB
via IFTTT
SportsCenter Video: Tim Kurkjian says Chris Davis' \"love\" for Baltimore is ultimately what pushed him to re-sign (ESPN)
from ESPN http://ift.tt/1eW1vUH
via IFTTT
via IFTTT
[FD] Correct answer Information Disclosure in TCExam <= 12.2.5
-----------------------------------------------------
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
Orioles: 1B Chris Davis' deal to return to Baltimore is worth $161 million over 7 years, according to MLB Network (ESPN)
from ESPN http://ift.tt/1eW1vUH
via IFTTT
via IFTTT
MLB: 1B Chris Davis to re-sign with the Orioles - MLB Network; led ML in HR (47) for 2nd time in last 3 seasons in 2015 (ESPN)
from ESPN http://ift.tt/1eW1vUH
via IFTTT
via IFTTT
Casino Sues Cyber Security Company Over Failure to Stop Hackers
IT security firm Trustwave has been sued by a Las Vegas-based casino operator for conducting an allegedly "woefully inadequate" investigation following a network breach of the casino operator’s system. Affinity Gaming, an operator of 5 casinos in Nevada and 6 elsewhere in the United States, has questioned Trustwave's investigation for failing to shut down breach that directly resulted in

from The Hacker News http://ift.tt/1RrEhxs
via IFTTT
from The Hacker News http://ift.tt/1RrEhxs
via IFTTT
Apple's Mac OS X Still Open to Malware, Thanks Gatekeeper
Apple Mac Computers are considered to be much safer than Windows computers at keeping out the viruses and malware, but the new Exploit discovered by researchers again proves it indeed quite false. Last year, The Hacker News reported a deadly simple exploit that completely bypassed one of the core security features in Mac OS X known as Gatekeeper. Apple released a patch in November, but

from The Hacker News http://ift.tt/1QcLkJf
via IFTTT
from The Hacker News http://ift.tt/1QcLkJf
via IFTTT
Wright Mons in Color
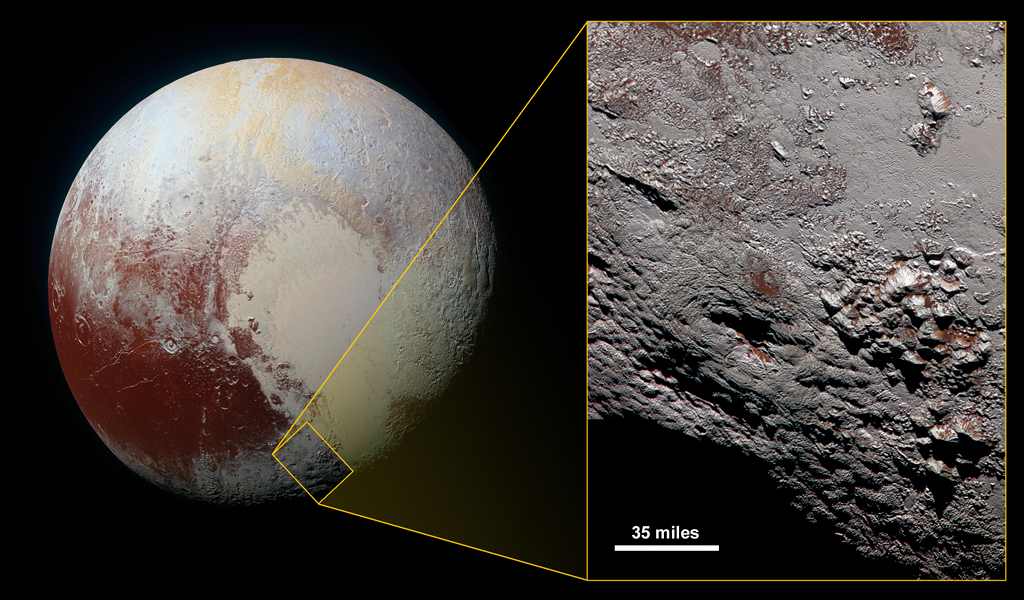
Informally named Wright Mons, a broad mountain about 150 kilometers across and 4 kilometers high with a wide, deep summit depression is featured in this inset image captured during the New Horizons flyby of Pluto in July 2015. Of course, broad mountains with summit craters are found elsewhere in the Solar System, like the large shield volcano Mauna Loa on planet Earth or giant Olympus Mons on Mars. New Horizons scientists note the striking similarity of Pluto's Wright Mons, and nearby Piccard Mons, to large shield volcanoes suggests the two could be giant cryovolcanoes that once erupted molten ice from the interior of the cold, distant world. In fact, found on a frozen dwarf planet Wright Mons could be the largest volcano in the outer Solar System. Since only one impact crater has been identified on its slopes, Wright Mons may well have been active late in Pluto's history. This highest resolution color image also reveals red material sparsely scattered around the region. via NASA http://ift.tt/1OTcyDI
IMERG Rainfall Accumulation over the United States for December 2015
A series of winter storms brought more than 20 inches of rainfall to the Midwest and southeastern United States in December 2015. Massive flooding followed throughout both the regions. This animation shows the accumulation of rainfall from December's three major storm systems that took place on Dec. 1 through 3, Dec. 13 through 16, and Dec. 21 through 31. The observations are from NASA's Global Precipitation Measurement (GPM) mission. Red colors indicate accumulate rainfall of 20 inches, yellow show 10-12 inches, green 6-10 inches, and shades of blue 2-6 inches. The extent of the area that drains into the Mississippi River is outlined in black. In the Midwest, rainwater swelled the banks of rivers and tributaries that then feed the Mississippi River, leading to flooding in Missouri, Illinois, Oklahoma, Arkansas and Mississippi. The crest of the Mississippi River travelled downstream through Louisiana toward the Gulf of Mexico the first week of January 2016, passing through New Orleans, which opened the Bonnet Carre Spillway north of the city to prevent flooding. Alabama and Georgia and other areas in the southeast were hardest hit by rainstorms that arrived Christmas week, which led to massive flooding and declarations of a state of emergency in Alabama and northern Georgia.
from NASA's Scientific Visualization Studio: Most Recent Items http://ift.tt/1KiDlnz
via IFTTT
from NASA's Scientific Visualization Studio: Most Recent Items http://ift.tt/1KiDlnz
via IFTTT
Friday, January 15, 2016
Orioles: 3B Manny Machado agrees to a 1-year, $5 million deal to avoid arbitration according to multiple reports (ESPN)
from ESPN http://ift.tt/1eW1vUH
via IFTTT
via IFTTT
Re: [FD] Combining DLL hijacking with USB keyboard emulation
While I agree that there is a lot you can do if you can plug a malicious USB device into a computer and that you might not need to take advantage of the DLL problem in order to successfully complete the attack, my point is that it could help. Consider that the attack could be carried out either by convincing the user to plug in the USB device or by sneakly plugging it into their computer while they're away. Therefore, reducing the time it takes to complete and how much fuzz it makes on the screen could be a great advantage in a lot of situations. In my own experiments, a payload that simply starts transfering a DLL completes in about six seconds. You can unplug the device in less time than that, right after it opens cmd and starts the execution of the one line of commands. This is quicker than any other I've seen before.
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
[FD] CCA on CoreProc/crypto-guard and an Appeal to PHP Programmers
Hi Full Disclosure Readers, Let's jump right into the vulnerability: In May of last year, I reported to CryptoGuard that their cryptography wasn't guarding against chosen-ciphertext attacks, which is the sort of oversight that would allow me to intercept a ciphertext message then keep feeding it back into the decryption process with slight alterations until I recovered the plaintext. http://ift.tt/1YRG6Vq And then several months passed, and I forgot it even existed. I got a notification last night that they closed the issue, and eagerly tagged a v1.0.0 release. So I looked again a bit more carefully and I discovered that they were using their IV as an HMAC key. http://ift.tt/1SmY3dD Experienced infosec folks are probably expecting me to say, "Don't roll your own crypto." And they're half right. You probably shouldn't write your own crypto code, be it for encrypting text, storing passwords, or storing all of your session state in a cookie (shudder). But I've come to realize that telling programmers not to write crypto is like telling teenagers to practice abstinence. Instead, I implore you to follow the advice of Taylor Hornby (Defuse Security, Crackstation, CryptoFails, etc.): http://ift.tt/1ACyqul Crypto Amateurs: Write Crypto Code! Don't Publish It!
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
[FD] Whatever happened with CVE-2015-0072?
It seems that this issue was originally disclosed here: http://ift.tt/1znn7Yf. Eventually a CVE was assigned: http://ift.tt/1C4yKGl and then MSFT released a patch: http://ift.tt/1B21NDp. But, according to http://ift.tt/1NbYrE6 (and local testing) it remains unpatched for Windows 8.1 on IE 11. Do anyone have any insight into what happened? I haven't seen any follow up to the issue as to why the patch didn't work (did it ever work and there was a regression or was the patch always broken)? And, more importantly, has there been any followup from MSFT? It would seem that Windows 8.1/IE 11 are still eligible for security updates, so I'm scratching my head on the lack of communication/patches here. Thanks!
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
[FD] FreeBSD bsnmpd information disclosure
-----BEGIN PGP SIGNED MESSAGE-
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
[FD] Qualys Security Advisory - Roaming through the OpenSSH client: CVE-2016-0777 and CVE-2016-0778
Qualys Security Advisory Roaming through the OpenSSH client: CVE-2016-0777 and CVE-2016-0778 ======================================================================== Contents ======================================================================== Summary Information Leak (CVE-2016-0777) - Analysis - Private Key Disclosure - Mitigating Factors - Examples Buffer Overflow (CVE-2016-0778) - Analysis - Mitigating Factors - File Descriptor Leak Acknowledgments Proof Of Concept ======================================================================== Summary ======================================================================== Since version 5.4 (released on March 8, 2010), the OpenSSH client supports an undocumented feature called roaming: if the connection to an SSH server breaks unexpectedly, and if the server supports roaming as well, the client is able to reconnect to the server and resume the suspended SSH session. Although roaming is not supported by the OpenSSH server, it is enabled by default in the OpenSSH client, and contains two vulnerabilities that can be exploited by a malicious SSH server (or a trusted but compromised server): an information leak (memory disclosure), and a buffer overflow (heap-based). The information leak is exploitable in the default configuration of the OpenSSH client, and (depending on the client's version, compiler, and operating system) allows a malicious SSH server to steal the client's private keys. This information leak may have already been exploited in the wild by sophisticated attackers, and high-profile sites or users may need to regenerate their SSH keys accordingly. The buffer overflow, on the other hand, is present in the default configuration of the OpenSSH client but its exploitation requires two non-default options: a ProxyCommand, and either ForwardAgent (-A) or ForwardX11 (-X). This buffer overflow is therefore unlikely to have any real-world impact, but provides a particularly interesting case study. All OpenSSH versions between 5.4 and 7.1 are vulnerable, but can be easily hot-fixed by setting the undocumented option "UseRoaming" to "no", as detailed in the Mitigating Factors section. OpenSSH version 7.1p2 (released on January 14, 2016) disables roaming by default. ======================================================================== Information Leak (CVE-2016-0777) ========================================================================
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
[FD] [TOOL] The Metabrik Platform
Hi list, I would like to introduce you to The Metabrik Platform, please find a complete description below. For the impatient, you can see it in action at the following link: http://ift.tt/1TLZf8b The Metabrik Platform bind togother a classic Shell with a Perl interpreter as a REPL (Read-Eval-Print-Loop) and a ton of small Briks. Briks are reusable components each performing a specific task. You chain Briks together using Perl variables, they are used to pass output of a Brik Command as input for another Brik Command. By chaining Briks together, you easily create new powerful tools, just like the UNIX pipe. Today, there is more than 170 Briks available. Metabrik goals: - Glue the Perl language with a shell - Give a standardised API to write reusable Briks - Self-documented Briks to make them easy to use - Only 4 main shell commands to remember: use, set, get, run Metabrik features: - Completion on Brik names, Commands and Attributes - Completion on file manipulation - Completion on Perl variable names - Command history and recalling - Customization support with a .rc file - Scripting support - Multiple Brik repositories support Metabrik helps you to concentrate on scenarios instead of wasting your time searching how to use a program. You just have to reuse available Briks to perform your everyday job. Briks also share the same syntax so you don’t have to scratch your head each time you use yet-another-tool, and they also feature integrated help. For more, visit http://ift.tt/1J7t2aR Regards,
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
[FD] [KIS-2016-01] CakePHP <= 3.2.0 "_method" CSRF Protection Bypass Vulnerability
-----------------------------------------------------------
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
Orioles: Team's offer to Yoenis Cespedes is yet another sign Baltimore is done with 1B Chris Davis, says Eddie Matz (ESPN)
from ESPN http://ift.tt/1eW1vUH
via IFTTT
via IFTTT
Anonymous function is from which version existing?
I want to know from which version does anonymous function start to exist. I am working on a fluid mechanics library written in MATLAB. In this library ...
from Google Alert - anonymous http://ift.tt/1OTzxOV
via IFTTT
from Google Alert - anonymous http://ift.tt/1OTzxOV
via IFTTT
ISS Daily Summary Report – 1/14/16
Fluid Shifts: Kornienko continued his Return minus 45 day (R-45) Fluid Shifts activities today in the Russian Segment with assistance from Kelly and Volkov and guidance from the ground team. He performed Optical Coherence Tomography (OCT), Cerebral and Cochlear Fluid Pressure (CCFP) and Distortion Product Otoacoustic Emissions (DPOAE) tests, and a Tonometry exam. He also completed the part of the experiment utilizing the Russian Chibis (Lower Body Negative Pressure – LBNP) suit during ultrasound measurements. Fluid Shifts investigates the causes for severe and lasting physical changes to astronaut’s eyes. Because the headward fluid shift is a hypothesized contributor to these changes, reversing this fluid shift with a lower body negative pressure device is investigated as a possible intervention. Results from this study may help to develop preventative measures against lasting changes in vision and eye damage. Sleep Log: Kelly recorded a Sleep Log entry today after waking. The Sleep ISS-12 experiment monitors ambient light exposure and crew member activity and collects subjective evaluations of sleep and alertness. The investigation examines the effects of space flight and ambient light exposure on sleep during a year-long mission on the ISS. Extravehicular Activity (EVA) Preparation: The USOS Crew carried out their final Equipment Lock and Tool preparations in support of tomorrow’s Sequential Shunt Unit (SSU) EVA. In addition, they printed and reviewed Cuff Checklist procedures, reviewed an EVA Briefing Package, Detailed Timeline, Tool Configuration Summary, Sharp Edge Briefing, and SSU Systems Briefing Package. Egress from the Joint Airlock is scheduled to occur tomorrow morning at 6:55am CST. Today’s Planned Activities All activities were completed unless otherwise noted. Morning Inspection, Laptop RS1(2) Reboot RSS 1, 2 Reboot IMMUNO. Saliva Sample (Session 1) Extravehicular Activity (EVA) Reminder for EVA In-Suit Light Exercise (ISLE) Preparation IMMUNO. First stress test, questionnaire data entry IMMUNO. Test-Tube Blood Collection (finger) IMMUNO. Blood Sample Processing IMMUNO. Equipment Stowage FLUID SHIFTS. Comm configuration for the experiment Final printout of EVA procedures Freon Analysis of SM Atmosphere Using Freon Leak Analyzer/Detector (ФИТ) (CМ1РО_4_402) USOS EVA Tool Configuration Pille Sensors setup for USOS EVA FLUID SHIFTS FS1 Server SW Installation to copy SOT data Life On The Station Photo and Video Audit of Personal Hygiene Articles (СЛГ). Selection of wipes for priority use IMS Delta File Prep PAO hardware setup TV Session with Time magazine and NTV Channel Relocating PBAs for upcoming EVA 24-hour ECG Monitoring (termination) USOS EVA Tool Audit 24-hour BP monitoring (terminate) Life On The Station Photo and Video Audit of Personal Hygiene Articles (СЛГ). Selection of wipes for priority use Equipment Lock Preparation Evening Work Prep Robotic Work Station (RWS) – Display and Control Unit (DCP) powerup Final printout of EVA procedures IMMUNO. Second stress test, questionnaire data entry EVA Procedure Review IMMUNO. Saliva Sample (Session 2) IMMUNO. Equipment Stowage Closeout CONTENT. Experiment Ops EVA Procedure Review US EVA Procedure Conference Earth photo/video ops Preparation of Reports for Roscosmos Web Site and Social Media Video Recording for All-Russia State Television and Radio Broadcasting Company (ВГТРК) URAGAN Observations and Photography ECON-M. Observations and Photography Completed Task List Items None Ground Activities All activities were completed unless otherwise noted. Nominal System Commanding Three-Day Look Ahead: Friday, 01/15: EVA #35 (SSU 1B) Saturday, 01/16: USOS Airlock Deconfiguration, EVA Tool Stow, EVA debrief with ground Sunday, 01/17: Crew Day Off QUICK ISS Status – Environmental Control Group: Component Status Elektron On Vozdukh Manual [СКВ] 1 – SM Air Conditioner System (“SKV1”) On [СКВ] 2 – SM Air Conditioner System (“SKV2”) Off Carbon Dioxide Removal Assembly (CDRA) Lab Standby Carbon Dioxide Removal Assembly (CDRA) Node 3 Operate Major Constituent Analyzer (MCA) Lab Idle Major Constituent Analyzer (MCA) Node 3 Operate Oxygen Generation Assembly (OGA) Process Urine Processing Assembly (UPA) Standby Trace Contaminant Control System (TCCS) Lab Full Up Trace Contaminant Control System (TCCS) Node 3 Off
from ISS On-Orbit Status Report http://ift.tt/1J6L3Gq
via IFTTT
from ISS On-Orbit Status Report http://ift.tt/1J6L3Gq
via IFTTT
Creator of MegalodonHTTP DDoS Botnet Arrested
Last month, the Norway police arrested five hackers accused of running the MegalodonHTTP Remote Access Trojan (RAT). The arrests came as part of the joint operation between Norway’s Kripos National Criminal Investigation Service and Europol, codenamed "OP Falling sTAR." According to the United States security firm, all the five men, aged between 16 and 24 years and located in Romania,

from The Hacker News http://ift.tt/233YAoM
via IFTTT
from The Hacker News http://ift.tt/233YAoM
via IFTTT
Re: [psutil] Add basic NetBSD support. (#557)
The process is long-running and still exists. The test failure on that process is repeatable for me. I'm not quite sure how you're extracting information for that process, but here's the listing from /proc/142: ls -l /proc/142/ total 176 -r--r--r-- 1 wiz users 0 Jan 15 11:10 cmdline --
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
Critical OpenSSH Flaw Leaks Private Crypto Keys to Hackers
A 'Serious' security vulnerability has been discovered and fixed in OpenSSH – one of the most widely used open-source implementations of the Secure Shell (SSH) Protocol. The critical vulnerability could be exploited by hackers to force clients to leak their secret private cryptographic keys, potentially exposing users to Man-in-the-Middle (MITM) attacks. What Causes the Flaw to occur?

from The Hacker News http://ift.tt/233RXma
via IFTTT
from The Hacker News http://ift.tt/233RXma
via IFTTT
http://ift.tt/fvZjIzanonymous/a14be256861899d01c43 | Parchment - College admissions ...
http://ift.tt/fvZjIzanonymous/a14be256861899d01c43 ... http://ift.tt/fvZjIzanonymous/a. by Anonymous. of a blog item at National Review ...
from Google Alert - anonymous http://ift.tt/1WdM9lw
via IFTTT
from Google Alert - anonymous http://ift.tt/1WdM9lw
via IFTTT
Infrared Portrait of the Large Magellanic Cloud

Cosmic dust clouds ripple across this infrared portrait of our Milky Way's satellite galaxy, the Large Magellanic Cloud. In fact, the remarkable composite image from the Herschel Space Observatory and the Spitzer Space Telescope show that dust clouds fill this neighboring dwarf galaxy, much like dust along the plane of the Milky Way itself. The dust temperatures tend to trace star forming activity. Spitzer data in blue hues indicate warm dust heated by young stars. Herschel's instruments contributed the image data shown in red and green, revealing dust emission from cooler and intermediate regions where star formation is just beginning or has stopped. Dominated by dust emission, the Large Magellanic Cloud's infrared appearance is different from views in optical images. But this galaxy's well-known Tarantula Nebula still stands out, easily seen here as the brightest region to the left of center. A mere 160,000 light-years distant, the Large Cloud of Magellan is about 30,000 light-years across. via NASA http://ift.tt/1SQ3gtN
Thursday, January 14, 2016
Analysis of Algorithms and Partial Algorithms. (arXiv:1601.03411v1 [cs.AI])
We present an alternative methodology for the analysis of algorithms, based on the concept of expected discounted reward. This methodology naturally handles algorithms that do not always terminate, so it can (theoretically) be used with partial algorithms for undecidable problems, such as those found in artificial general intelligence (AGI) and automated theorem proving. We mention new approaches to self-improving AGI and logical uncertainty enabled by this methodology.
from cs.AI updates on arXiv.org http://ift.tt/1lbZZHF
via IFTTT
Paisley Schottisch (Anonymous)
Paisley Schottisch (Anonymous). Add File. Add Sheet MusicAdd Your Own ArrangementAdd Your Own CompositionAdd Your Own EditionAdd ...
from Google Alert - anonymous http://ift.tt/1RRzy6Q
via IFTTT
from Google Alert - anonymous http://ift.tt/1RRzy6Q
via IFTTT
I have a new follower on Twitter
Impellus
The UK's most influential ILM Accredited Leadership & Management Training Centre. Open courses at 15 venues nationwide. Specialist Business Performance Training
London, St Albans, UK Delivery
http://t.co/TgY76SCqau
Following: 1655 - Followers: 1948
January 14, 2016 at 08:07PM via Twitter http://twitter.com/ImpellusUK
Orioles Buzz: OF Yoenis Cespedes receives offer from team; no financial details available - report; 35 HR last season (ESPN)
from ESPN http://ift.tt/1eW1vUH
via IFTTT
via IFTTT
Add the option for specify anonymous email and name
Please add the option for specify customs the anonymous email and name, instead the anonymous_XXXXX@example.com . Now is not convenient to ...
from Google Alert - anonymous http://ift.tt/1J5FzvF
via IFTTT
from Google Alert - anonymous http://ift.tt/1J5FzvF
via IFTTT
Mel Kiper's Mock Draft 1.0: Ravens select Notre Dame OT Ronnie Stanley No. 6 overall; last picked 1st-round OT in 2009 (ESPN)
from ESPN http://ift.tt/17lH5T2
via IFTTT
via IFTTT
Orioles: Mark Trumbo agrees to $9.15M deal to avoid salary arbitration - Jerry Crasnick; acquired Dec. 2 from Mariners (ESPN)
from ESPN http://ift.tt/1eW1vUH
via IFTTT
via IFTTT
Asian Couples Seek Anonymous Asian Donors. Make $7000+ SO Much More!!
Attention Women 21-30: Become an Anonymous Egg Donor! Make up to $8000 + MORE While Helping Others! Would you like to make up to $8000+ ...
from Google Alert - anonymous http://ift.tt/1Skdu6h
via IFTTT
from Google Alert - anonymous http://ift.tt/1Skdu6h
via IFTTT
ISS Daily Summary Report – 1/13/16
Fluid Shifts Before, During and After Prolonged Space Flight and Their Association with Intracranial Pressure and Visual Impairment (Fluid Shifts): Kelly continued his Return minus 45 day (R-45) Fluid Shifts activities today in the Russian Segment with assistance from Kornienko and Volkov and guidance from the ground team. He performed Optical Coherence Tomography (OCT), Cerebral and Cochlear Fluid Pressure (CCFP) and Distortion Product Otoacoustic Emissions (DPOAE) tests, and a Tonometry exam. He also completed the part of the experiment utilizing the Russian Chibis (Lower Body Negative Pressure – LBNP) suit during ultrasound measurements. Fluid Shifts investigates the causes for severe and lasting physical changes to astronaut’s eyes. Because the headward fluid shift is a hypothesized contributor to these changes, reversing this fluid shift with a lower body negative pressure device is investigated as a possible intervention. Results from this study may help to develop preventative measures against lasting changes in vision and eye damage. Sprint Ultrasound: Kopra performed his Flight Day 30 thigh and calf ultrasound scans today with assistance from Peake and guidance from the Sprint ground team. Ultrasound scans are used to evaluate spaceflight-induced changes in the muscle volume. The Sprint investigation evaluates the use of high intensity, low volume exercise training to minimize loss of muscle, bone, and cardiovascular function in ISS crewmembers during long-duration missions. Upon completion of this study, investigators expect to provide an integrated resistance and aerobic exercise training protocol capable of maintaining muscle, bone and cardiovascular health while reducing total exercise time over the course of a long-duration space flight. This will provide valuable information in support of the long term goal of protecting human fitness for even longer space exploration missions. Fine Motor Skills: Kopra completed a session of the Fine Motor Skills experiment today. During the experiment he performed a series of interactive tasks on a touchscreen tablet. This investigation is the first fine motor skills study to measure long-term microgravity exposure, different phases of microgravity adaptation, and sensorimotor recovery after returning to Earth gravity. Mobile Servicing System (MSS) Operations: Yesterday afternoon, ground controllers successfully performed a periodic survey of the Space Communications and Navigation (SCaN) Testbed Experiment on ExPRESS Logistics Carrier (ELC)-3. Once the survey was complete, they commanded a Mobile Transporter (MT) translation from Worksite (WS)-7 to WS-2. The move was required in order to provide camera support during Friday’s Sequential Shunt Unit (SSU) 1B Extravehicular Activity (EVA) and to preposition the Space Station Remote Manipulator System (SSRMS) for next week’s Main Bus Switching Unit (MBSU) demonstration activity. Orbital ATK (OA)-4 Cargo Operations: Kelly, Kopra, and Peake continued transferring cargo from Cygnus to ISS today. Approximately 33 hours of cargo operations remain. Cardiopulmonary Resuscitation (CPR) Training: The 45S Crew (Malenchenko, Kopra, and Peake) participated in medical contingency training. This on-board training provides crewmembers the opportunity to work as a team in resolving a simulated medical emergency. The training also allows the crew to practice communication and coordination necessary to perform medical emergency procedures. They located medical emergency procedures and appropriate Health Maintenance System (HMS) components utilized during an emergency and determined the deployed configuration. Finally, they reviewed individual methods of CPR delivery in micro-gravity. Today’s Planned Activities All activities were completed unless otherwise noted. Morning Inspection. SM ПСС (Caution & Warning Panel) Test Biochemical Urine Test FLUID SHIFTS Comm configuration FLUID SHIFTS. Gathering and Connecting Equipment for TV coverage URISYS Hardware Stowage Fine Motor Skills – Examination FLUID SHIFTS Experiment Operations ECLSS Recycle Tank Remove and Replace Soyuz 719 Samsung Tablet Recharge – Initiate On MCC GO Regeneration of БМП Ф2 Micropurification Cartridge Pre-EVA Crew Health Status – Prep Periodic Health Evaluation before EVA WRS – Recycle Tank Fill USND2 – Hardware Activation SPRINT – Hardware prep and installation KULONOVSKIY KRISTALL. Experiment Ops Battery Charging for EVA Camera setup SPRINT – Operator Assistance with the Experiment KULONOVSKIY KRISTALL. Copy and Downlink Data Replacement of urine receptacle (МП) and filter-insert (Ф-В) in АСУ. Install Urine Receptacle No. 0550035 (00067297R, СМ1РО_1_138_1), Filter-Insert No. 1406277 (00064551R, СМ1РО_1_138_1, Cover 1200024 b/c 00045144R). Stow the removed unit in ТКГ 429 for disposal KULONOVSKIY KRISTALL. Hardware Teardown FLUID SHIFTS. Copying Data from CCFP/DPOAE devices and their deactivation in RS HAM radio session from Columbus DOSETRK – Medication Tracking Update USND2 – Data Transfer Private Psychological Conference WRS – Recycle Tank Fill Soyuz 719 Samsung Tablet Recharge – terminate CheCS OBT WRS – Recycle Tank Fill RGN REC-TNK – Remove depress hose for nominal operations 24-hour ECG monitoring USND2 – Hardware Deactivation MATRYOSHKA-R. Gathering and Initialization of Bubble-Dosimeter Detectors HABIT – Questionnaire Completion Private Psychological Conference JRNL – Journal Entry WRS Maintenance WRS – Recycle Tank Fill 24-hour BP monitoring DOSETRK – Medication Tracking Update IMS and Stowage Conference RGN – Initiate drain into EDV MATRYOSHKA-R. Handover of BUBBLE-dosimeters to USOS RADIN – Handover of Detectors from/to RS MATRYOSHKA-R. BUBBLE-dosimeter detector initialization and deployment for exposure RADIN – Dosimeter Deployment INTERACTION-2. Experiment Ops Soyuz 718 Samsung Tablet Recharge – Initiate WRS Maintenance RGN – Terminate water drain into EDV IMS Delta File Prep USOS EVA – Camera Setup СОЖ Maintenance IMMUNO. Preparing Saliva-Immuno Kit for the experiment Cygnus Cargo Operations Evening Work Prep Soyuz 718 Samsung Tablet Recharge – terminate On MCC GO БМП Ф2 Absorption Cartridge Regeneration Preparation of Reports for Roscosmos Web Site and Social Media Video Recording for All-Russia State Television and Radio Broadcasting Company (ВГТРК) URAGAN Observations and Photography ECON-M. Observations and Photography Completed Task List Items EVA Tool Configuration Ground Activities All activities were completed unless otherwise noted. Nominal System Commanding Three-Day Look Ahead: Thursday, 01/14: EVA Procedure Review, EVA Tool Audit, Equipment Lock Preparation Friday, 01/15: EVA #35 (SSU 1B) Saturday, 01/16: USOS Airlock Deconfiguration, EVA Tool Stow, EVA debrief with ground QUICK ISS Status – Environmental Control Group: Component Status Elektron On Vozdukh Manual [СКВ] 1 – SM Air Conditioner System (“SKV1”) On [СКВ] 2 – SM Air Conditioner System (“SKV2”) Off Carbon Dioxide Removal Assembly (CDRA) […]
from ISS On-Orbit Status Report http://ift.tt/1OR6Ou1
via IFTTT
from ISS On-Orbit Status Report http://ift.tt/1OR6Ou1
via IFTTT
Conan Has Angered "Anonymous"
Conan Has Angered "Anonymous". January 14, 2016 Share 0 Comments · Share on Reddit.com. There's an audience member in a Guy Fawkes mask ...
from Google Alert - anonymous http://ift.tt/1URspmv
via IFTTT
from Google Alert - anonymous http://ift.tt/1URspmv
via IFTTT
Hacker group Anonymous declares war on Thai police over British backpacker murders
Hacker group Anonymous declared war on ISIS in wake of the terrorist attacks in Paris. Now, the organization has declared war on a different group: ...
from Google Alert - anonymous http://ift.tt/1RnapSY
via IFTTT
from Google Alert - anonymous http://ift.tt/1RnapSY
via IFTTT
A SNEAK PEEK AT DARK KNIGHT UNIVERSE PRESENTS
A SNEAK PEEK AT DARK KNIGHT UNIVERSE PRESENTS: GREEN LANTERN. By Anonymous Wednesday, January 13th, 2016. 0 Comments.
from Google Alert - anonymous http://ift.tt/1nkt2dH
via IFTTT
from Google Alert - anonymous http://ift.tt/1nkt2dH
via IFTTT
Reflections on the 1970s

The 1970s are sometimes ignored by astronomers, like this beautiful grouping of reflection nebulae in Orion - NGC 1977, NGC 1975, and NGC 1973 - usually overlooked in favor of the substantial glow from the nearby stellar nursery better known as the Orion Nebula. Found along Orion's sword just north of the bright Orion Nebula complex, these reflection nebulae are also associated with Orion's giant molecular cloud about 1,500 light-years away, but are dominated by the characteristic blue color of interstellar dust reflecting light from hot young stars. In this sharp color image a portion of the Orion Nebula appears along the bottom border with the cluster of reflection nebulae at picture center. NGC 1977 stretches across the field just below center, separated from NGC 1973 (above right) and NGC 1975 (above left) by dark regions laced with faint red emission from hydrogen atoms. Taken together, the dark regions suggest to many the shape of a running man. via NASA http://ift.tt/1Q54iRX
Wednesday, January 13, 2016
Helias tuition costs drop, thanks to anonymous donor
The cost of going to Helias Catholic High School will go down, thanks to an anonymous donor.The tuition cost for a Catholic student will go down 40%, ...
from Google Alert - anonymous http://ift.tt/1JLECsb
via IFTTT
from Google Alert - anonymous http://ift.tt/1JLECsb
via IFTTT
An Application of the Generalized Rectangular Fuzzy Model to Critical Thinking Assessment. (arXiv:1601.03065v1 [cs.AI])
The authors apply the Generalized Rectangular Model to assessing critical thinking skills and its relations with their language competency.
from cs.AI updates on arXiv.org http://ift.tt/1RmsLDB
via IFTTT
Submodular Optimization under Noise. (arXiv:1601.03095v1 [cs.DS])
We consider the problem of maximizing monotone submodular functions under noise, which to the best of our knowledge has not been studied in the past. There has been a great deal of work on optimization of submodular functions under various constraints, with many algorithms that provide desirable approximation guarantees. However, in many applications we do not have access to the submodular function we aim to optimize, but rather to some erroneous or noisy version of it. This raises the question of whether provable guarantees are obtainable in presence of error and noise. We provide initial answers, by focusing on the question of maximizing a monotone submodular function under cardinality constraints when given access to a noisy oracle of the function. We show that:
For a cardinality constraint $k \geq 2$, there is an approximation algorithm whose approximation ratio is arbitrarily close to $1-1/e$;
For $k=1$ there is an approximation algorithm whose approximation ratio is arbitrarily close to $1/2$ in expectation. No randomized algorithm can obtain an approximation ratio in expectation better than $1/2+O(1/\sqrt n)$ and $(2k - 1)/2k + O(1/\sqrt{n})$ for general $k$;
If the noise is adversarial, no non-trivial approximation guarantee can be obtained.
from cs.AI updates on arXiv.org http://ift.tt/1PYTPpp
via IFTTT
Online Prediction of Dyadic Data with Heterogeneous Matrix Factorization. (arXiv:1601.03124v1 [cs.AI])
Dyadic Data Prediction (DDP) is an important problem in many research areas. This paper develops a novel fully Bayesian nonparametric framework which integrates two popular and complementary approaches, discrete mixed membership modeling and continuous latent factor modeling into a unified Heterogeneous Matrix Factorization~(HeMF) model, which can predict the unobserved dyadics accurately. The HeMF can determine the number of communities automatically and exploit the latent linear structure for each bicluster efficiently. We propose a Variational Bayesian method to estimate the parameters and missing data. We further develop a novel online learning approach for Variational inference and use it for the online learning of HeMF, which can efficiently cope with the important large-scale DDP problem. We evaluate the performance of our method on the EachMoive, MovieLens and Netflix Prize collaborative filtering datasets. The experiment shows that, our model outperforms state-of-the-art methods on all benchmarks. Compared with Stochastic Gradient Method (SGD), our online learning approach achieves significant improvement on the estimation accuracy and robustness.
from cs.AI updates on arXiv.org http://ift.tt/1RmsLDx
via IFTTT
How to stay anonymous if you win the $1.5B POWERBALL
However in Virginia: When you win the Lottery in Virginia, it's not a secret! Your name, hometown, prize amount, date of win and where you bought the ...
from Google Alert - anonymous http://ift.tt/1mWCCTB
via IFTTT
from Google Alert - anonymous http://ift.tt/1mWCCTB
via IFTTT
[FD] EasyDNNnews Reflected XSS
Details ======= Product: EasyDNNnews Vulnerability: Reflected XSS Author: Peter Lapp, lappsec () gmail com CVE: None Vulnerable Versions: <7.5 Fixed Version: 7.5 Summary ======= From the vendor's website: "EasyDNNnews is a very powerful DotNetNuke module that enables non-technical users to publish and manage articles, news, press releases, stories and editorials." During an engagement it was discovered that reflected XSS could be achieved in two locations by appending a bogus GET parameter that contained JavaScript in the parameter name. After alerting EasyDNNsolutions of the vulnerability, they informed me that one of the vulnerabilities had already been fixed and the other would be fixed in an upcoming release. Example ================= http://ift.tt/200lwTf Solution ======== Upgrade to 7.5 Timeline ======== 08/31/15 - Contacted EasyDNNnews about the vulnerability. 09/01/15 - Vendor responds and says the first vulnerability has been fixed and the other will be in the next release, which was 7.5.
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
How to Hack WiFi Password from Smart Doorbells
The buzz around The Internet of Things (IoT) is growing, and it is growing at a great pace. Every day the technology industry tries to connect another household object to the Internet. One such internet-connected household device is a Smart Doorbell. Gone are the days when we have regular doorbells and need to open the door every time the doorbell rings to see who is around. <!-- adsense

from The Hacker News http://ift.tt/1ninjVF
via IFTTT
from The Hacker News http://ift.tt/1ninjVF
via IFTTT
ISS Daily Summary Report – 1/12/16
Electrostatic Levitation Furnaces 1 and 2 (ELF 1 & 2) Setup: Kelly and Peake set up the Japan Aerospace Exploration Agency (JAXA) ELF equipment for installation in the Multi-purpose Small Payload Rack 2 (MSPR2) work volume in the Japanese Experiment Module (JEM). The crew was unable to complete all of the installation activities today. They will be completed at the earliest opportunity. The ELF is an experimental facility designed to levitate, melt and solidify materials employing containerless processing techniques that use the electrostatic levitation method with charged samples and electrodes. With this facility, thermophysical properties of high temperature melts can be measured and solidification from deeply undercooled melts can be achieved. Fluid Shifts Before, During and After Prolonged Space Flight and Their Association with Intracranial Pressure and Visual Impairment (Fluid Shifts): Kelly and Kornienko continued their Return minus 45 day (R-45) Fluid Shifts activities today in the Russian Segment with assistance from Volkov. This third part of the Fluid Shifts experiment utilizes the Russian Chibis (Lower Body Negative Pressure – LBNP) suit during ultrasound measurements. Fluid Shifts investigates the causes for severe and lasting physical changes to astronaut’s eyes. Because the headward fluid shift is a hypothesized contributor to these changes, reversing this fluid shift with a lower body negative pressure device is investigated as a possible intervention. Results from this study may help to develop preventative measures against lasting changes in vision and eye damage. Japanese Experiment Module (JEM) Airlock Pressurization and Leak Check: In preparation for removal of the Robotics Refueling Mission (RRM) Task Board 4 and the Robotic Micro Conical Tool (RMCT)-1 from the JEM Airlock Slide Table later this month, Kelly has pressurized the JEM Airlock and performed a leak check today. Extravehicular Activity (EVA) Tool Preparation: Kopra and Peake continued to prepare for Friday’s Sequential Shunt Unit (SSU) EVA. Today, they re-familiarized themselves with the tools needed to perform the SSU change out, installed a long term tether onto the EPIC MDM Ethernet Cable bundle to allow for external stowage without being plugged in, if required. In addition, they packed the Internal Docking Adapter (IDA) EVA bag with the required cabling. Intermodule Ventilation (IMV) Flow Measurements: As part of system health monitoring, Kopra utilized a Velocicalc tool in order to obtain measurements of selected ventilation inlets and outlets within the USOS. Today’s measurements took place within the Joint Airlock, Node1, Node 2, Node 3, Cupola, and the Lab. Mobile Servicing System (MSS) Operations: This afternoon, ground controllers are performing a periodic survey of the Scan Testbed Experiment on ExPRESS Logistics Carrier (ELC)-3. Once the survey is complete, they will command an Mobile Transporter (MT) translation from Worksite (WS)-7 to WS-2. The move is required in order to provide camera support during Friday’s Sequential Shunt Unit (SSU) 1B Extravehicular Activity (EVA) and to preposition the Space Station Remote Manipulator System (SSRMS) for next week’s Main Bus Switching Unit (MBSU) demonstation activity. Today’s Planned Activities All activities were completed unless otherwise noted. Morning Inspection. SM ПСС (Caution & Warning Panel) Test Laptop RS1(2) Reboot RSS 1, 2 Reboot Hematocrit Test MO – Experiment Ops Hematocrit Hardware Stowage JEM Airlock Pressurization On MCC GO Regeneration of БМП Ф1 Micropurification Cartridge БСПН Log-File Dump RGN – Initiate drain into EDV FLUID SHIFTS ISS Crew Handover JEM Airlock Leak Check Fine Motor Skills – Examination RGN – Terminate water drain into EDV MELFI 3 TDR – Battery Swap Collect SM and FGB Air Samples Using АК-1М Sampler WRS – Recycle Tank Fill ELF S/U- Procedure Review SM Air Sampling for FREON Using АК-1М Sampler XF305 Camcorder Settings Adjustment VEG-01 – Plant Photo MSPR2 – Software Setup СОЖ Maintenance MSPR2 – Configuration Setup MSPR2 – Software Setup KULONOVSKIY KRISTALL. Experiment Ops EVA Tool Config ALGOMETRIA. Experiment Ops IMS Delta File Prep SM Ventilation System Preventive Maintenance. Group В1 Evening Work Prep EXPOSE-R. Copy and Downlink Data WRS – Recycle Tank Fill INTERACTION-2. Experiment Ops IMV Flow Measurement USND2 – Hardware installation and activation URYSIS Setup for Operation On MCC GO БМП Ф1 Absorption Cartridge Regeneration Preparation of Reports for Roscosmos Web Site and Social Media Video Recording for All-Russia State Television and Radio Broadcasting Company (ВГТРК) ECON-M. Observation and Photography Completed Task List Items None Ground Activities All activities were completed unless otherwise noted. Scan Test Bed Survey with MSS MT translation from WS-7 to WS-2 Three-Day Look Ahead: Wednesday, 01/13: Fluid Shifts, Sprint Ultrsound, Circadian Rhythms, Medical Emergency Training, Cygnus Cargo Ops Thursday, 01/14: EVA Procedure Review, EVA Tool Audit, Equipment Lock Preparation Friday, 01/15: SSU 1B EVA QUICK ISS Status – Environmental Control Group: Component Status Elektron On Vozdukh Manual [СКВ] 1 – SM Air Conditioner System (“SKV1”) Off [СКВ] 2 – SM Air Conditioner System (“SKV2”) Off Carbon Dioxide Removal Assembly (CDRA) Lab Standby Carbon Dioxide Removal Assembly (CDRA) Node 3 Operate Major Constituent Analyzer (MCA) Lab Idle Major Constituent Analyzer (MCA) Node 3 Operate Oxygen Generation Assembly (OGA) Process Urine Processing Assembly (UPA) Standby Trace Contaminant Control System (TCCS) Lab Full Up Trace Contaminant Control System (TCCS) Node 3 Off
from ISS On-Orbit Status Report http://ift.tt/1PWRVWb
via IFTTT
from ISS On-Orbit Status Report http://ift.tt/1PWRVWb
via IFTTT
Someone Just Leaked Hard-Coded Password Backdoor for Fortinet Firewalls
Are millions of enterprise users, who rely on the next-generation firewalls for protection, actually protected from hackers? Probably Not. Just less than a month after an unauthorized backdoor found in Juniper Networks firewalls, an anonymous security researcher has discovered highly suspicious code in FortiOS firewalls from enterprise security vendor Fortinet. According to the

from The Hacker News http://ift.tt/1W6FVnj
via IFTTT
from The Hacker News http://ift.tt/1W6FVnj
via IFTTT
US Intelligence Chief Hacked by the Teen Who Hacked CIA Director
Nation's Top Spy Chief Got Hacked! The same teenage hacker who broke into the AOL email inbox of CIA Director John Brennan last October has now claimed to have broken into personal email and phone accounts of the US Director of National Intelligence James Clapper. <!-- adsense --> Clapper was targeted by the teenage hacker, who called himself Cracka and claimed to be a member of the

from The Hacker News http://ift.tt/1Oqn6Xc
via IFTTT
from The Hacker News http://ift.tt/1Oqn6Xc
via IFTTT
The California Nebula

What's California doing in space? Drifting through the Orion Arm of the spiral Milky Way Galaxy, this cosmic cloud by chance echoes the outline of California on the west coast of the United States. Our own Sun also lies within the Milky Way's Orion Arm, only about 1,500 light-years from the California Nebula. Also known as NGC 1499, the classic emission nebula is around 100 light-years long. On the featured image, the most prominent glow of the California Nebula is the red light characteristic of hydrogen atoms recombining with long lost electrons, stripped away (ionized) by energetic starlight. The star most likely providing the energetic starlight that ionizes much of the nebular gas is the bright, hot, bluish Xi Persei just to the right of the nebula. A regular target for astrophotographers, the California Nebula can be spotted with a wide-field telescope under a dark sky toward the constellation of Perseus, not far from the Pleiades. via NASA http://ift.tt/1OfMqBf
Tuesday, January 12, 2016
Phys. Rev. A 93, 012318
In this paper, an efficient quantum anonymous ranking protocol with single particles is proposed. A semitrusted server is introduced to help multiple ...
from Google Alert - anonymous http://ift.tt/1PVZxZ6
via IFTTT
from Google Alert - anonymous http://ift.tt/1PVZxZ6
via IFTTT
Inference rules for RDF(S) and OWL in N3Logic. (arXiv:1601.02650v1 [cs.DB])
This paper presents inference rules for Resource Description Framework (RDF), RDF Schema (RDFS) and Web Ontology Language (OWL). Our formalization is based on Notation 3 Logic, which extended RDF by logical symbols and created Semantic Web logic for deductive RDF graph stores. We also propose OWL-P that is a lightweight formalism of OWL and supports soft inferences by omitting complex language constructs.
from cs.AI updates on arXiv.org http://ift.tt/1mTZset
via IFTTT
Robobarista: Learning to Manipulate Novel Objects via Deep Multimodal Embedding. (arXiv:1601.02705v1 [cs.RO])
There is a large variety of objects and appliances in human environments, such as stoves, coffee dispensers, juice extractors, and so on. It is challenging for a roboticist to program a robot for each of these object types and for each of their instantiations. In this work, we present a novel approach to manipulation planning based on the idea that many household objects share similarly-operated object parts. We formulate the manipulation planning as a structured prediction problem and learn to transfer manipulation strategy across different objects by embedding point-cloud, natural language, and manipulation trajectory data into a shared embedding space using a deep neural network. In order to learn semantically meaningful spaces throughout our network, we introduce a method for pre-training its lower layers for multimodal feature embedding and a method for fine-tuning this embedding space using a loss-based margin. In order to collect a large number of manipulation demonstrations for different objects, we develop a new crowd-sourcing platform called Robobarista. We test our model on our dataset consisting of 116 objects and appliances with 249 parts along with 250 language instructions, for which there are 1225 crowd-sourced manipulation demonstrations. We further show that our robot with our model can even prepare a cup of a latte with appliances it has never seen before.
from cs.AI updates on arXiv.org http://ift.tt/1TTDpPX
via IFTTT
Basic Reasoning with Tensor Product Representations. (arXiv:1601.02745v1 [cs.AI])
In this paper we present the initial development of a general theory for mapping inference in predicate logic to computation over Tensor Product Representations (TPRs; Smolensky (1990), Smolensky & Legendre (2006)). After an initial brief synopsis of TPRs (Section 0), we begin with particular examples of inference with TPRs in the 'bAbI' question-answering task of Weston et al. (2015) (Section 1). We then present a simplification of the general analysis that suffices for the bAbI task (Section 2). Finally, we lay out the general treatment of inference over TPRs (Section 3). We also show the simplification in Section 2 derives the inference methods described in Lee et al. (2016); this shows how the simple methods of Lee et al. (2016) can be formally extended to more general reasoning tasks.
from cs.AI updates on arXiv.org http://ift.tt/1SNvdCv
via IFTTT
Essence' Description. (arXiv:1601.02865v1 [cs.AI])
A description of the Essence' language as used by the tool Savile Row.
from cs.AI updates on arXiv.org http://ift.tt/1mTZpzw
via IFTTT
The minimal hitting set generation problem: algorithms and computation. (arXiv:1601.02939v1 [cs.DS])
Finding inclusion-minimal "hitting sets" for a given collection of sets is a fundamental combinatorial problem with applications in domains as diverse as Boolean algebra, computational biology, and data mining. Much of the algorithmic literature focuses on the problem of *recognizing* the collection of minimal hitting sets; however, in many of the applications, it is more important to *generate* these hitting sets. We survey twenty algorithms from across a variety of domains, considering their history, classification, useful features, and computational performance on a variety of synthetic and real-world inputs. We also provide a suite of implementations of these algorithms with a ready-to-use, platform-agnostic interface based on Docker containers and the AlgoRun framework, so that interested computational scientists can easily perform similar tests with inputs from their own research areas on their own computers or through a convenient Web interface.
from cs.AI updates on arXiv.org http://ift.tt/1SNvfdy
via IFTTT
Indicators of Good Student Performance in Moodle Activity Data. (arXiv:1601.02975v1 [cs.CY])
In this paper we conduct an analysis of Moodle activity data focused on identifying early predictors of good student performance. The analysis shows that three relevant hypotheses are largely supported by the data. These hypotheses are: early submission is a good sign, a high level of activity is predictive of good results and evening activity is even better than daytime activity. We highlight some pathological examples where high levels of activity correlates with bad results.
from cs.AI updates on arXiv.org http://ift.tt/1mTZpiU
via IFTTT
Mapping-equivalence and oid-equivalence of single-function object-creating conjunctive queries. (arXiv:1503.01707v2 [cs.DB] UPDATED)
Conjunctive database queries have been extended with a mechanism for object creation to capture important applications such as data exchange, data integration, and ontology-based data access. Object creation generates new object identifiers in the result, that do not belong to the set of constants in the source database. The new object identifiers can be also seen as Skolem terms. Hence, object-creating conjunctive queries can also be regarded as restricted second-order tuple-generating dependencies (SO tgds), considered in the data exchange literature.
In this paper, we focus on the class of single-function object-creating conjunctive queries, or sifo CQs for short. We give a new characterization for oid-equivalence of sifo CQs that is simpler than the one given by Hull and Yoshikawa and places the problem in the complexity class NP. Our characterization is based on Cohen's equivalence notions for conjunctive queries with multiplicities. We also solve the logical entailment problem for sifo CQs, showing that also this problem belongs to NP. Results by Pichler et al. have shown that logical equivalence for more general classes of SO tgds is either undecidable or decidable with as yet unknown complexity upper bounds.
from cs.AI updates on arXiv.org http://ift.tt/1FgRrUs
via IFTTT
Anonymous tip leads to drug arrests
Two North Vernon residents remain behind bars in Jefferson County on drug-related charges after police received an anonymous tip Saturday night.
from Google Alert - anonymous http://ift.tt/1Sh4RcN
via IFTTT
from Google Alert - anonymous http://ift.tt/1Sh4RcN
via IFTTT
Confirmation Not Accessible to Anonymous User?
It looks like users who are not admin cannot access the Webform Submission Confirmation page when the webform is anonymized. I am wondering if ...
from Google Alert - anonymous http://ift.tt/1mVmLp5
via IFTTT
from Google Alert - anonymous http://ift.tt/1mVmLp5
via IFTTT
Quant voi le douz tens bel et cler (Anonymous)
Quant voi le douz tens bel et cler (Anonymous). Add File. Add Sheet MusicAdd Your Own ArrangementAdd Your Own CompositionAdd Your Own ...
from Google Alert - anonymous http://ift.tt/1mVmLoQ
via IFTTT
from Google Alert - anonymous http://ift.tt/1mVmLoQ
via IFTTT
'Ridiculous' Bug in Popular Antivirus Allows Hackers to Steal all Your Passwords
If you have installed Trend Micro's Antivirus on your Windows computer, then Beware. Your computer can be remotely hijacked, or infected with any malware by even through a website – Thanks to a critical vulnerability in Trend Micro Security Software. The Popular antivirus maker and security firm Trend Micro has released an emergency patch to fix critical flaws in its anti-virus product

from The Hacker News http://ift.tt/1P7NSDl
via IFTTT
from The Hacker News http://ift.tt/1P7NSDl
via IFTTT
Order revision shows Anonymous at order completion phase
I am having a problem with my orders, they all become changed to Anonymous, after the payment is completed. I am using TouchNet for my payment ...
from Google Alert - anonymous http://ift.tt/1ZitRPU
via IFTTT
from Google Alert - anonymous http://ift.tt/1ZitRPU
via IFTTT
Transformation and Recovery: Spiritual Implications of the Alcoholics Anonymous Twelve-Step ...
Abstract: The purpose of this study was to examine spiritual implications and program involvement among Alcoholics Anonymous members (N = 116).
from Google Alert - anonymous http://ift.tt/1J11kwA
via IFTTT
from Google Alert - anonymous http://ift.tt/1J11kwA
via IFTTT
ISS Daily Summary Report – 1/11/16
Neuromapping: Kopra completed a NeuroMapping Neurocognitive test on a Human Research Facility laptop. The Neuromapping experiment studies whether long-duration spaceflight causes any changes to the brain, including brain structure and function, motor control, and multi-tasking; as well as measuring how long it takes for the brain and body to recover from those possible changes. Previous research and anecdotal evidence from crewmembers returning from a long-duration spaceflight suggests that movement control and cognition are affected in microgravity. Skin-B: Peake completed a session today for the European Space Agency (ESA) Skin-B investigation. He took Corneometer measurements of the hydration level of the stratus coreum (outer layer of the skin), Tewameter measurements of the skin barrier function, and Visioscan measurements of skin surface topography. The Skin-B investigation aims to improve the understanding of skin aging, which is greatly accelerated in space. The data will also be used to verify the results from previous testing for the SkinCare investigation on the ISS. Veg-01 Observation: Ground experts identified in downlinked photographs potential mold on one of the three remaining plants for the Veg-01 experiment. Yesterday Scott trimmed all the area with spots, double bagged them and placed them into Minus Eighty Degree Celsius Laboratory Freezer for ISS (MELFI). The Veg-01 investigation is used to assess on-orbit function and performance of the Veggie facility, focusing on the growth and development of seedlings in the spaceflight environment and the composition of microbial flora on the plants and the facility. For this run, Zinnias will be grown for 60 days and are expected to produce flowers. Cognition: Kopra performed his Flight Day 27 session of the Cognition experiment today. The Individualized Real-Time Neurocognitive Assessment Toolkit for Space Flight Fatigue (Cognition) investigation is a battery of tests that measure how spaceflight-related physical changes, such as microgravity and lack of sleep, can affect cognitive performance. Cognition includes ten brief computerized tests that cover a wide range of cognitive functions, and provides immediate feedback on current and past test results. The software used allows for real-time measurement of cognitive performance while in space. Habitability: Today Kopra documented his recent observations and Kelly recorded a walk-through video of an area or activity and provided insights related to human factors and habitability. The Habitability investigation results will be used to assess the relationship between crew members and their environment in order to better prepare for future long-duration spaceflights to destinations, such as near earth asteroids and Mars. Observations recorded during 6 month and 1 year missions can help spacecraft designers determine how much habitable volume is required, and whether a mission’s duration impacts how much space crew members need. Extravehicular Activity (EVA) Preparations: The USOS Crew prepared the Equipment Lock, Extravehicular Mobility Units (EMU), and ancillary hardware to support upcoming Sequential Shunt Unit (SSU) EVA scheduled for Friday, January 15th. In addition, they conducted an EMU On-Orbit Fit Verification (OFV) for Peake in order to confirm the correct sizing on EMU 3008. ISS Reboost: ISS performed a reboost Sunday night using the Progress 61P thrusters. The delta-V for the burn was 1.65 meters per second. This reboost is the first in a series of reboosts to target the planned conditions for the Soyuz 44 landing on March 2nd, Soyuz 46 four orbit rendezvous on March 19th, and Progress 63 four orbit rendezvous on March 31st. Today’s Planned Activities All activities were completed unless otherwise noted. WRS – Recycle Tank Fill MO – Saliva collection equipment setup WHC – fill SKNB- Experiment Ops FLUID SHIFTS. USOS H/W Gathering ISS Crew Handover / Handover Recommendations (РПС) WRS Water Sample Analysis Physical Fitness Evaluation (on the treadmill) FLUID SHIFTS VIBROLAB. Monitoring hardware activation Verification of ИП-1 Flow Sensor Position UDOD. Experiment Ops with DYKNANIYE-1 and SPRUT-2 Sets. Tagup with specialists EVA – Equipment Lock Preparation IFM Deep Socket Relocate [Aborted] SEISMOPROGNOZ. Downlink data from Control and Data Acquisition Module (МКСД) HDD Download Pille Dosimeter Readings UDOD. Photography of the Experiment Ops MRM1 Fans Screen Cleaning (group B). Cleaning behind panels 405, 406 MELF2 – Temperature Data Recorder (TDR) Battery Swap WRS Maintenance WRS – Recycle Tank Fill TOCA Data Recording WRS Maintenance TOCA Waste Water Bag (WWB) Changeout IDENTIFICATION. Copy ИМУ-Ц micro-accelerometer data to laptop SEISMOPROGNOZ. Downlink data from Control and Data Acquisition Module (МКСД) HDD (end) and start backup. Tagup with specialists HABIT – Video during the experiment Replacement of ТА251М (ЛКТ4В2) Life On The Station Photo and Video ТКГ 431 (DC1) Transfers and IMS Ops NMAP. Test Ops Countermeasure System (CMS) HABIT – Questionnaire Completion EMU On-Orbit Fitcheck Verification Physical Fitness Evaluation (on the treadmill) Exercise Data Downlink via OCA Photography of Plume Impingement and Deposit Monitoring Unit (БКДО) position on MRM2 through SM window No.13 VIBROLAB. Copy and Downlink Data Evening Work Prep Environmental Health System (EHS) – Relocation of Intravehicular Tissue Equivalent Proportional Counter (IV-TEPC) IMS Delta File Prep Evening Work Prep Hematocrit Hardware Setup COGNITION – Experiment Ops and Filling Questionnaire Preparation of Reports for Roscosmos Web Site and Social Media Video Recording for All-Russia State Television and Radio Broadcasting Company (ВГТРК) ECON-M. Observation and Photography Completed Task List Items None Ground Activities All activities were completed unless otherwise noted. UHF Activation in support of EMU OFV activity Three-Day Look Ahead: Tuesday, 01/12: Fluid Shifts using Chibis, MSPR2 ELF, EVA Tool Config, IMV Flow Measurements Wednesday, 01/13: Fluid Shifts, Sprint Ultrsound, Circadian Rhythms, Medical Emergency Training, Cygnus Cargo Ops Thursday, 01/14: EVA Procedure Review, EVA Tool Audit, Equipment Lock Preparation QUICK ISS Status – Environmental Control Group: Component Status Elektron On Vozdukh Manual [СКВ] 1 – SM Air Conditioner System (“SKV1”) On [СКВ] 2 – SM Air Conditioner System (“SKV2”) Off Carbon Dioxide Removal Assembly (CDRA) Lab Standby Carbon Dioxide Removal Assembly (CDRA) Node 3 Operate Major Constituent Analyzer (MCA) Lab Idle Major Constituent Analyzer (MCA) Node 3 Operate Oxygen Generation Assembly (OGA) Process Urine Processing Assembly (UPA) Standby Trace Contaminant Control System (TCCS) Lab Full Up Trace Contaminant […]
from ISS On-Orbit Status Report http://ift.tt/1ZYfenf
via IFTTT
from ISS On-Orbit Status Report http://ift.tt/1ZYfenf
via IFTTT
From Today Onwards, Don't You Even Dare to Use Microsoft Internet Explorer
Yes, from today, Microsoft is ending the support for versions 8, 9 and 10 of its home-built browser Internet Explorer, thereby encouraging Windows users to switch on to Internet Explorer version 11 or its newest Edge browser. Microsoft is going to release one last patch update for IE8, IE9 and IE10 today, but this time along with an "End of Life" notice, meaning Microsoft will no longer

from The Hacker News http://ift.tt/1RjGXgA
via IFTTT
from The Hacker News http://ift.tt/1RjGXgA
via IFTTT
Simple Yet Effective eBay Bug Allows Hackers to Steal Passwords
A simple, yet effective flaw discovered on eBay's website exposed hundreds of millions of its customers to an advance Phishing Attack. An Independent Security Researcher reported a critical vulnerability to eBay last month that had the capability to allow hackers to host a fake login page, i.e. phishing page, on eBay website in an effort to steal users' password and harvest credentials

from The Hacker News http://ift.tt/1OMRVJk
via IFTTT
from The Hacker News http://ift.tt/1OMRVJk
via IFTTT
[FD] SEC Consult whitepaper: Bypassing McAfee Application Whitelisting for Critical Infrastructure Systems
SEC Consult Vulnerability Lab released a new whitepaper titled: "Bypassing McAfee Application Whitelisting for Critical Infrastructure Systems" - the dinosaurs want their vuln back Link to blog overview:
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
A Colorful Solar Corona over the Himalayas

What are those colorful rings around the Sun? A corona visible only to Earth observers in the right place at the right time. Rings like this will sometimes appear when the Sun or Moon is seen through thin clouds. The effect is created by the quantum mechanical diffraction of light around individual, similarly-sized water droplets in an intervening but mostly-transparent cloud. Since light of different colors has different wavelengths, each color diffracts differently. Solar Coronae are one of the few quantum color effects that can be easily seen with the unaided eye. This type of solar corona is a visual effect due to water in Earth's atmosphere and is altogether different from the solar corona that exists continually around the Sun -- and stands out during a total solar eclipse. In the foreground is the famous Himalayan mountain peak Ama Dablam (Mother's Necklace), via NASA http://ift.tt/1IYFPwq
Monday, January 11, 2016
Re: [FD] Executable installers are vulnerable^WEVIL (case 20): TrueCrypt's installers allow arbitrary (remote) code execution and escalation of privilege
TrueCrypt ceased development back in 2014. Please refer to the below link to migrate to an alternative (BitLocker) from TrueCrypt. http://ift.tt/1oKN6Sl
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
same cache for anonymous and authentificated user
hello, I'am looking for a way / hook for indicate that authentificated user get the same cache than anonymous user. I tried to play with the following ...
from Google Alert - anonymous http://ift.tt/1OeVWVv
via IFTTT
from Google Alert - anonymous http://ift.tt/1OeVWVv
via IFTTT
Identifying Stable Patterns over Time for Emotion Recognition from EEG. (arXiv:1601.02197v1 [cs.HC])
In this paper, we investigate stable patterns of electroencephalogram (EEG) over time for emotion recognition using a machine learning approach. Up to now, various findings of activated patterns associated with different emotions have been reported. However, their stability over time has not been fully investigated yet. In this paper, we focus on identifying EEG stability in emotion recognition. To validate the efficiency of the machine learning algorithms used in this study, we systematically evaluate the performance of various popular feature extraction, feature selection, feature smoothing and pattern classification methods with the DEAP dataset and a newly developed dataset for this study. The experimental results indicate that stable patterns exhibit consistency across sessions; the lateral temporal areas activate more for positive emotion than negative one in beta and gamma bands; the neural patterns of neutral emotion have higher alpha responses at parietal and occipital sites; and for negative emotion, the neural patterns have significant higher delta responses at parietal and occipital sites and higher gamma responses at prefrontal sites. The performance of our emotion recognition system shows that the neural patterns are relatively stable within and between sessions.
from cs.AI updates on arXiv.org http://ift.tt/1OeGkkR
via IFTTT
On Clustering Time Series Using Euclidean Distance and Pearson Correlation. (arXiv:1601.02213v1 [cs.LG])
For time series comparisons, it has often been observed that z-score normalized Euclidean distances far outperform the unnormalized variant. In this paper we show that a z-score normalized, squared Euclidean Distance is, in fact, equal to a distance based on Pearson Correlation. This has profound impact on many distance-based classification or clustering methods. In addition to this theoretically sound result we also show that the often used k-Means algorithm formally needs a mod ification to keep the interpretation as Pearson correlation strictly valid. Experimental results demonstrate that in many cases the standard k-Means algorithm generally produces the same results.
from cs.AI updates on arXiv.org http://ift.tt/1Ka9NbA
via IFTTT
A Synthetic Approach for Recommendation: Combining Ratings, Social Relations, and Reviews. (arXiv:1601.02327v1 [cs.IR])
Recommender systems (RSs) provide an effective way of alleviating the information overload problem by selecting personalized choices. Online social networks and user-generated content provide diverse sources for recommendation beyond ratings, which present opportunities as well as challenges for traditional RSs. Although social matrix factorization (Social MF) can integrate ratings with social relations and topic matrix factorization can integrate ratings with item reviews, both of them ignore some useful information. In this paper, we investigate the effective data fusion by combining the two approaches, in two steps. First, we extend Social MF to exploit the graph structure of neighbors. Second, we propose a novel framework MR3 to jointly model these three types of information effectively for rating prediction by aligning latent factors and hidden topics. We achieve more accurate rating prediction on two real-life datasets. Furthermore, we measure the contribution of each data source to the proposed framework.
from cs.AI updates on arXiv.org http://ift.tt/1JGDp5p
via IFTTT
Git4Voc: Git-based Versioning for Collaborative Vocabulary Development. (arXiv:1601.02433v1 [cs.AI])
Collaborative vocabulary development in the context of data integration is the process of finding consensus between the experts of the different systems and domains. The complexity of this process is increased with the number of involved people, the variety of the systems to be integrated and the dynamics of their domain. In this paper we advocate that the realization of a powerful version control system is the heart of the problem. Driven by this idea and the success of Git in the context of software development, we investigate the applicability of Git for collaborative vocabulary development. Even though vocabulary development and software development have much more similarities than differences there are still important differences. These need to be considered within the development of a successful versioning and collaboration system for vocabulary development. Therefore, this paper starts by presenting the challenges we were faced with during the creation of vocabularies collaboratively and discusses its distinction to software development. Based on these insights we propose Git4Voc which comprises guidelines how Git can be adopted to vocabulary development. Finally, we demonstrate how Git hooks can be implemented to go beyond the plain functionality of Git by realizing vocabulary-specific features like syntactic validation and semantic diffs.
from cs.AI updates on arXiv.org http://ift.tt/1JGDoP4
via IFTTT
Evaluating the Performance of a Speech Recognition based System. (arXiv:1601.02543v1 [cs.CL])
Speech based solutions have taken center stage with growth in the services industry where there is a need to cater to a very large number of people from all strata of the society. While natural language speech interfaces are the talk in the research community, yet in practice, menu based speech solutions thrive. Typically in a menu based speech solution the user is required to respond by speaking from a closed set of words when prompted by the system. A sequence of human speech response to the IVR prompts results in the completion of a transaction. A transaction is deemed successful if the speech solution can correctly recognize all the spoken utterances of the user whenever prompted by the system. The usual mechanism to evaluate the performance of a speech solution is to do an extensive test of the system by putting it to actual people use and then evaluating the performance by analyzing the logs for successful transactions. This kind of evaluation could lead to dissatisfied test users especially if the performance of the system were to result in a poor transaction completion rate. To negate this the Wizard of Oz approach is adopted during evaluation of a speech system. Overall this kind of evaluations is an expensive proposition both in terms of time and cost. In this paper, we propose a method to evaluate the performance of a speech solution without actually putting it to people use. We first describe the methodology and then show experimentally that this can be used to identify the performance bottlenecks of the speech solution even before the system is actually used thus saving evaluation time and expenses.
from cs.AI updates on arXiv.org http://ift.tt/1P5b5G3
via IFTTT
Clustering Markov Decision Processes For Continual Transfer. (arXiv:1311.3959v2 [cs.AI] UPDATED)
We present algorithms to effectively represent a set of Markov decision processes (MDPs), whose optimal policies have already been learned, by a smaller source subset for lifelong, policy-reuse-based transfer learning in reinforcement learning. This is necessary when the number of previous tasks is large and the cost of measuring similarity counteracts the benefit of transfer. The source subset forms an `$\epsilon$-net' over the original set of MDPs, in the sense that for each previous MDP $M_p$, there is a source $M^s$ whose optimal policy has $<\epsilon$ regret in $M_p$. Our contributions are as follows. We present EXP-3-Transfer, a principled policy-reuse algorithm that optimally reuses a given source policy set when learning for a new MDP. We present a framework to cluster the previous MDPs to extract a source subset. The framework consists of (i) a distance $d_V$ over MDPs to measure policy-based similarity between MDPs; (ii) a cost function $g(\cdot)$ that uses $d_V$ to measure how good a particular clustering is for generating useful source tasks for EXP-3-Transfer and (iii) a provably convergent algorithm, MHAV, for finding the optimal clustering. We validate our algorithms through experiments in a surveillance domain.
from cs.AI updates on arXiv.org http://ift.tt/1hQHbuA
via IFTTT
What to talk about and how? Selective Generation using LSTMs with Coarse-to-Fine Alignment. (arXiv:1509.00838v2 [cs.CL] UPDATED)
We propose an end-to-end, domain-independent neural encoder-aligner-decoder model for selective generation, i.e., the joint task of content selection and surface realization. Our model first encodes a full set of over-determined database event records via an LSTM-based recurrent neural network, then utilizes a novel coarse-to-fine aligner to identify the small subset of salient records to talk about, and finally employs a decoder to generate free-form descriptions of the aligned, selected records. Our model achieves the best selection and generation results reported to-date (with 59% relative improvement in generation) on the benchmark WeatherGov dataset, despite using no specialized features or linguistic resources. Using an improved k-nearest neighbor beam filter helps further. We also perform a series of ablations and visualizations to elucidate the contributions of our key model components. Lastly, we evaluate the generalizability of our model on the RoboCup dataset, and get results that are competitive with or better than the state-of-the-art, despite being severely data-starved.
from cs.AI updates on arXiv.org http://ift.tt/1LM9FRU
via IFTTT
Client Profiling for an Anti-Money Laundering System. (arXiv:1510.00878v2 [cs.LG] UPDATED)
We present a data mining approach for profiling bank clients in order to support the process of detection of anti-money laundering operations. We first present the overall system architecture, and then focus on the relevant component for this paper. We detail the experiments performed on real world data from a financial institution, which allowed us to group clients in clusters and then generate a set of classification rules. We discuss the relevance of the founded client profiles and of the generated classification rules. According to the defined overall agent-based architecture, these rules will be incorporated in the knowledge base of the intelligent agents responsible for the signaling of suspicious transactions.
from cs.AI updates on arXiv.org http://ift.tt/1VCaK1z
via IFTTT
Highway Long Short-Term Memory RNNs for Distant Speech Recognition. (arXiv:1510.08983v2 [cs.NE] UPDATED)
In this paper, we extend the deep long short-term memory (DLSTM) recurrent neural networks by introducing gated direct connections between memory cells in adjacent layers. These direct links, called highway connections, enable unimpeded information flow across different layers and thus alleviate the gradient vanishing problem when building deeper LSTMs. We further introduce the latency-controlled bidirectional LSTMs (BLSTMs) which can exploit the whole history while keeping the latency under control. Efficient algorithms are proposed to train these novel networks using both frame and sequence discriminative criteria. Experiments on the AMI distant speech recognition (DSR) task indicate that we can train deeper LSTMs and achieve better improvement from sequence training with highway LSTMs (HLSTMs). Our novel model obtains $43.9/47.7\%$ WER on AMI (SDM) dev and eval sets, outperforming all previous works. It beats the strong DNN and DLSTM baselines with $15.7\%$ and $5.3\%$ relative improvement respectively.
from cs.AI updates on arXiv.org http://ift.tt/1k3dOIR
via IFTTT
Deep Reinforcement Learning with an Unbounded Action Space. (arXiv:1511.04636v3 [cs.AI] UPDATED)
In this paper, we propose the deep reinforcement relevance network (DRRN), a novel deep architecture, to design a better model for handling an unbounded action space with applications to language understanding for text-based games. For a particular class of games, a user must choose among a variable number of actions described by text, with the goal of maximizing long-term reward. In these games, the best action is typically that which best fits to the current situation (modeled as a state in the DRRN), also described by text. Because of the exponential complexity of natural language with respect to sentence length, there is typically an unbounded set of unique actions. Therefore, it is difficult to pre-define the action set. To address this challenge, the DRRN extracts separate high-level embedding vectors from the texts that describe states and actions, respectively, using a general interaction function, exploring inner product, bilinear, and DNN interaction, between these embedding vectors to approximate the Q-function. We evaluate the DRRN on two popular text games, showing superior performance over other deep Q-learning architectures.
from cs.AI updates on arXiv.org http://ift.tt/1MiWHMd
via IFTTT
Diego Mejia Ospina (@DiegoMejiaO) retweeted your Tweet!
@mistermcguire: [FD] Google Chrome - Javascript Execution Via Default Search Engines Diego Mejia Ospina retweeted your Tweet. View Patrick McGuire @mistermcguire = [FD] Google Chrome - Javascript Execution Via Default Search Engines ift.tt/1OevHhQ Settings | Help | Opt-out | Download app Twitter, Inc. 1355 Market Street, Suite 900 San Francisco, CA 94103
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
Javascript Digest (@javascriptd) retweeted your Tweet!
@mistermcguire: [FD] Google Chrome - Javascript Execution Via Default Search Engines Javascript Digest retweeted your Tweet. View Patrick McGuire @mistermcguire = [FD] Google Chrome - Javascript Execution Via Default Search Engines ift.tt/1OevHhQ Settings | Help | Opt-out | Download app Twitter, Inc. 1355 Market Street, Suite 900 San Francisco, CA 94103
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
Re: [FD] Combining DLL hijacking with USB keyboard emulation
On 2016-01-08 00:50:51 -0200, Rodrigo Menezes wrote: > Many of us have now been long aware of the possibility of > programming an USB device to emulate a keyboard and automatically > send keystrokes in order to perform malicious actions on a > computer. Some of the most interesting payloads that can be used > with this technique are based around downloading or creating an > executable file and then running it. > I'd like to bring to light that this attack could be combined > with DLL hijacking, with some benefits for the attacker. > For instance, a payload which simply downloads a DLL to the > current user's folder tends to complete faster and be more > reliable than one which tries to transfer an executable > AND immediately run it. The DLL would then most likely > be found and executed by a vulnerable installer [...] This way, > there would be no need for embeeding in the payload a complicated > attempt of bypassing the active defense mechanisms. Once you can fool the user to plug the USB device, you don't need anything else. The device may appear as 1. A mass storage, and 2. A keyboard or any other HID, and 3. Some unknown hardware Once the W-ndows enumerates this hardware, it will try to find and automatically install drivers for it. With a mass storage and a keyboard it will succeed, thus immediately bringing them to use, and unknown hardware would bring up a "search for drivers" dialog, where the attacker may (after some delay) send keystrokes to choose "search removable devices for drivers". Obviously, the mass storage part of the USB device would contain suitable .inf file pointing to malicious binaries. The USB device capable of performing such attack may be as simple as ATtiny85 + 25Q64 chips (both are available in a 3*4 mm SOP8), with a total cost of 1 EUR. The 25Q64 offers 8 Mbyte of storage, which is well enough for almost anything.
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
[FD] New BlackArch Linux ISOs (2016.01.10) released
Dear list, Today, we released new BlackArch Linux ISOs which include more than 1337 tools and comes with lots of improvements. The armv6h and armv7h repositories are filled with about 1200 tools. A short ChangeLog of the Live-ISOs: - added more than 30 new tools - updated system packages and userland files (etc/) - included linux kernel 4.3.3 - added bluetooth packages: bluez, bluez-firmware, bluez-hid2hci, bluez-utils - replaced 2nd browser opera with midori - replaced mplayer with mpv - package-fix: beef: use ruby 2 in beef - added few missing security tools from community - added package: htop If you're not already familiar with BlackArch Linux, please read the DESCRIPTION section below. [ DOWNLOAD ] You can download the new ISOs here: http://ift.tt/1mRMbnj [ DESCRIPTION ] BlackArch Linux is an Arch-based GNU/Linux distribution for pentesters and security researchers. The BlackArch package repository is compatible with existing Arch installs. Here are some of BlackArch's features: - Support for i686, x86_64, armv6h and armv7h architectures - Over 1300 tools (constantly increasing) - Modular package groups - A live ISO with multiple window managers, including dwm, fluxbox, openbox, awesome, wmii, i3 and spectrwm. - An optional installer with the ability to build from source. [ CONTACT ] We mostly work on BlackArch Linux for our personal use. We share it in the hopes that you will contribute by reporting bugs and sharing tools and ideas. We have a relaxed project structure. We welcome pull requests of all sizes through any means, including Github[0] and email[1]. Also see our Twitter account[2] and IRC channel[3]. Although BlackArch is the primary topic in the channel, we also have pleasant conversations about other things. Come join us. It's a happy place. [ THANKS ] We wish to thank all of BlackArch's users, mirrors, and supporters. Thanks your help. [ REFERENCES ] [0] http://ift.tt/19stv6i [1] blackarchlinux () gmail com [2] https://twitter.com/blackarchlinux [3] irc://irc.freenode.net/blackarch
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
[FD] CVE-2015-8397: GDCM out-of-bounds read in JPEGLSCodec::DecodeExtent
Grassroots DICOM (GDCM) is a C++ library for processing DICOM medical images. It provides routines to view and manipulate a wide range of image formats and can be accessed through many popular programming languages like Python, C#, Java and PHP. GDCM versions 2.6.0 and 2.6.1 (and possibly previous versions) are prone to an out-of-bounds read vulnerability due to missing checks. The vulnerability occurs during the decoding of JPEG-LS images when the dimensions of the embedded JPEG-LS image (as specified in the JPEG headers) are smaller than the ones of the selected region (set by gdcm::ImageRegionReader::SetRegion and usually based on DICOM header values). More information about this vulnerability can be found at http://ift.tt/1l1ihLF The GDCM project has released version 2.6.2 that addresses this issue. It is advised to upgrade all GDCM installations to the latest stable release. Disclosure Timeline
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
[FD] CVE-2015-8396: GDCM buffer overflow in ImageRegionReader::ReadIntoBuffer
Grassroots DICOM (GDCM) is a C++ library for processing DICOM medical images. It provides routines to view and manipulate a wide range of image formats and can be accessed through many popular programming languages like Python, C#, Java and PHP. GDCM versions 2.6.0 and 2.6.1 (and possibly previous versions) are prone to an integer overflow vulnerability which leads to a buffer overflow and potentially to remote code execution. The vulnerability is triggered by the exposed function gdcm::ImageRegionReader::ReadIntoBuffer, which copies DICOM image data to a buffer. ReadIntoBuffer checks whether the supplied buffer is large enough to hold the necessary data, however in this check it fails to detect the occurrence of an integer overflow, which leads to a buffer overflow later on in the code. The buffer overflow will occur regardless of the size of the buffer supplied to the ReadIntoBuffer call. More information about this vulnerability can be found at http://ift.tt/1RHrndr The GDCM project has released version 2.6.2 that addresses this issue. It is advised to upgrade all GDCM installations to the latest stable release. Disclosure Timeline
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
[FD] Linux user namespaces overlayfs local root
-----BEGIN PGP SIGNED MESSAGE-
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
[FD] Exploiting XXE vulnerabilities in AMF libraries
Hello, AMF (aka "Action Message Format") is a binary format used by Flash applications communicating with server-side components. A few data types supported by AMF deal with XML content (for example the "XML Document" type in AMF0). In 2015, several AMF libraries (including BlazeDS and PyAMF) were identified as vulnerable to XXE (aka "XML External Entity") and SSRF (aka "Server Side Forgery") attacks. I wrote a blog-post detailing: - server-side exploitation of the PyAMF vulnerability - server-side exploitation of the BlazeDS vulnerability - client-side exploitation of the BlazeDS vulnerability The article also includes a basic AMF client (in Python) used to exploit these vulnerabilities (or interact with AMF gateways at large). Link: http://ift.tt/1JirUeY Cheers, Nicolas Grégoire
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
I have a new follower on Twitter
Concussion News
Sharing news and insights on the available treatments for concussions.
USA
http://t.co/jhmdUZjvDu
Following: 3736 - Followers: 3192
January 11, 2016 at 05:20PM via Twitter http://twitter.com/concussion_news
[FD] Google Chrome - Javascript Execution Via Default Search Engines
Google Chrome allows execution of Javascript via the Default Search Engines feature. An exploit can be created to take advantage of this issue by manipulating the master_preferences file on a victim's machine. Video Example: https://www.youtube.com/watch?v=WoF-LkA6fMk Walkthrough: http://ift.tt/1IZmD1u
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
Passing variables to an anonymous function when using fminbnd
I'm trying to run a bounded minimization problem on an anonymous function, but am having difficulties both defining the variable bounds AND listing ...
from Google Alert - anonymous http://ift.tt/1RivGNJ
via IFTTT
from Google Alert - anonymous http://ift.tt/1RivGNJ
via IFTTT
Collect additional information on vote from anonymous users
I would like to be able to collect additional information from anonymous users upon voting, like name, phone and etc. I have tryed adding the Webform ...
from Google Alert - anonymous http://ift.tt/1ZWZPU4
via IFTTT
from Google Alert - anonymous http://ift.tt/1ZWZPU4
via IFTTT
Anonymous: The Canaries
Anonymous: The Canaries. Click for samples. Anonymous. The Canaries. For Keyboard. Y2-004Y019. Anonymous: The Canaries. Pages of music: 1.
from Google Alert - anonymous http://ift.tt/1UJGkuB
via IFTTT
from Google Alert - anonymous http://ift.tt/1UJGkuB
via IFTTT
OpenCV panorama stitching
In today’s blog post, I’ll demonstrate how to perform image stitching and panorama construction using Python and OpenCV. Given two images, we’ll “stitch” them together to create a simple panorama, as seen in the example above.
To construct our image panorama, we’ll utilize computer vision and image processing techniques such as: keypoint detection and local invariant descriptors; keypoint matching; RANSAC; and perspective warping.
Since there are major differences in how OpenCV 2.4.X and OpenCV 3.X handle keypoint detection and local invariant descriptors (such as SIFT and SURF), I’ve taken special care to provide code that is compatible with both versions (provided that you compiled OpenCV 3 with
opencv_contribsupport, of course).
In future blog posts we’ll extend our panorama stitching code to work with multiple images rather than just two.
Read on to find out how panorama stitching with OpenCV is done.
Looking for the source code to this post?
Jump right to the downloads section.
OpenCV panorama stitching
Our panorama stitching algorithm consists of four steps:
- Step #1: Detect keypoints (DoG, Harris, etc.) and extract local invariant descriptors (SIFT, SURF, etc.) from the two input images.
- Step #2: Match the descriptors between the two images.
- Step #3: Use the RANSAC algorithm to estimate a homography matrix using our matched feature vectors.
- Step #4: Apply a warping transformation using the homography matrix obtained from Step #3.
We’ll encapsulate all four of these steps inside
panorama.py, where we’ll define a
Stitcherclass used to construct our panoramas.
The
Stitcherclass will rely on the imutils Python package, so if you don’t already have it installed on your system, you’ll want to go ahead and do that now:
$ pip install imutils
Let’s go ahead and get started by reviewing
panorama.py:
# import the necessary packages
import numpy as np
import imutils
import cv2
class Stitcher:
def __init__(self):
# determine if we are using OpenCV v3.X
self.isv3 = imutils.is_cv3()
We start off on Lines 2-4 by importing our necessary packages. We’ll be using NumPy for matrix/array operations,
imutilsfor a set of OpenCV convenience methods, and finally
cv2for our OpenCV bindings.
From there, we define the
Stitcherclass on Line 6. The constructor to
Stitchersimply checks which version of OpenCV we are using by making a call to the
is_cv3method. Since there are major differences in how OpenCV 2.4 and OpenCV 3 handle keypoint detection and local invariant descriptors, it’s important that we determine the version of OpenCV that we are using.
Next up, let’s start working on the
stitchmethod:
# import the necessary packages
import numpy as np
import imutils
import cv2
class Stitcher:
def __init__(self):
# determine if we are using OpenCV v3.X
self.isv3 = imutils.is_cv3()
def stitch(self, images, ratio=0.75, reprojThresh=4.0,
showMatches=False):
# unpack the images, then detect keypoints and extract
# local invariant descriptors from them
(imageB, imageA) = images
(kpsA, featuresA) = self.detectAndDescribe(imageA)
(kpsB, featuresB) = self.detectAndDescribe(imageB)
# match features between the two images
M = self.matchKeypoints(kpsA, kpsB,
featuresA, featuresB, ratio, reprojThresh)
# if the match is None, then there aren't enough matched
# keypoints to create a panorama
if M is None:
return None
The
stitchmethod requires only a single parameter,
images, which is the list of (two) images that we are going to stitch together to form the panorama.
We can also optionally supply
ratio, used for David Lowe’s ratio test when matching features (more on this ratio test later in the tutorial),
reprojThreshwhich is the maximum pixel “wiggle room” allowed by the RANSAC algorithm, and finally
showMatches, a boolean used to indicate if the keypoint matches should be visualized or not.
Line 15 unpacks the
imageslist (which again, we presume to contain only two images). The ordering to the
imageslist is important: we expect images to be supplied in left-to-right order. If images are not supplied in this order, then our code will still run — but our output panorama will only contain one image, not both.
Once we have unpacked the
imageslist, we make a call to the
detectAndDescribemethod on Lines 16 and 17. This method simply detects keypoints and extracts local invariant descriptors (i.e., SIFT) from the two images.
Given the keypoints and features, we use
matchKeypoints(Lines 20 and 21) to match the features in the two images. We’ll define this method later in the lesson.
If the returned matches
Mare
None, then not enough keypoints were matched to create a panorama, so we simply return to the calling function (Lines 25 and 26).
Otherwise, we are now ready to apply the perspective transform:
# import the necessary packages
import numpy as np
import imutils
import cv2
class Stitcher:
def __init__(self):
# determine if we are using OpenCV v3.X
self.isv3 = imutils.is_cv3()
def stitch(self, images, ratio=0.75, reprojThresh=4.0,
showMatches=False):
# unpack the images, then detect keypoints and extract
# local invariant descriptors from them
(imageB, imageA) = images
(kpsA, featuresA) = self.detectAndDescribe(imageA)
(kpsB, featuresB) = self.detectAndDescribe(imageB)
# match features between the two images
M = self.matchKeypoints(kpsA, kpsB,
featuresA, featuresB, ratio, reprojThresh)
# if the match is None, then there aren't enough matched
# keypoints to create a panorama
if M is None:
return None
# otherwise, apply a perspective warp to stitch the images
# together
(matches, H, status) = M
result = cv2.warpPerspective(imageA, H,
(imageA.shape[1] + imageB.shape[1], imageA.shape[0]))
result[0:imageB.shape[0], 0:imageB.shape[1]] = imageB
# check to see if the keypoint matches should be visualized
if showMatches:
vis = self.drawMatches(imageA, imageB, kpsA, kpsB, matches,
status)
# return a tuple of the stitched image and the
# visualization
return (result, vis)
# return the stitched image
return result
Provided that
Mis not
None, we unpack the tuple on Line 30, giving us a list of keypoint
matches, the homography matrix
Hderived from the RANSAC algorithm, and finally
status, a list of indexes to indicate which keypoints in
matcheswere successfully spatially verified using RANSAC.
Given our homography matrix
H, we are now ready to stitch the two images together. First, we make a call to
cv2.warpPerspectivewhich requires three arguments: the image we want to warp (in this case, the right image), the 3 x 3 transformation matrix (
H), and finally the shape out of the output image. We derive the shape out of the output image by taking the sum of the widths of both images and then using the height of the second image.
Line 30 makes a check to see if we should visualize the keypoint matches, and if so, we make a call to
drawMatchesand return a tuple of both the panorama and visualization to the calling method (Lines 37-42).
Otherwise, we simply returned the stitched image (Line 45).
Now that the
stitchmethod has been defined, let’s look into some of the helper methods that it calls. We’ll start with
detectAndDescribe:
# import the necessary packages
import numpy as np
import imutils
import cv2
class Stitcher:
def __init__(self):
# determine if we are using OpenCV v3.X
self.isv3 = imutils.is_cv3()
def stitch(self, images, ratio=0.75, reprojThresh=4.0,
showMatches=False):
# unpack the images, then detect keypoints and extract
# local invariant descriptors from them
(imageB, imageA) = images
(kpsA, featuresA) = self.detectAndDescribe(imageA)
(kpsB, featuresB) = self.detectAndDescribe(imageB)
# match features between the two images
M = self.matchKeypoints(kpsA, kpsB,
featuresA, featuresB, ratio, reprojThresh)
# if the match is None, then there aren't enough matched
# keypoints to create a panorama
if M is None:
return None
# otherwise, apply a perspective warp to stitch the images
# together
(matches, H, status) = M
result = cv2.warpPerspective(imageA, H,
(imageA.shape[1] + imageB.shape[1], imageA.shape[0]))
result[0:imageB.shape[0], 0:imageB.shape[1]] = imageB
# check to see if the keypoint matches should be visualized
if showMatches:
vis = self.drawMatches(imageA, imageB, kpsA, kpsB, matches,
status)
# return a tuple of the stitched image and the
# visualization
return (result, vis)
# return the stitched image
return result
def detectAndDescribe(self, image):
# convert the image to grayscale
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# check to see if we are using OpenCV 3.X
if self.isv3:
# detect and extract features from the image
descriptor = cv2.xfeatures2d.SIFT_create()
(kps, features) = descriptor.detectAndCompute(image, None)
# otherwise, we are using OpenCV 2.4.X
else:
# detect keypoints in the image
detector = cv2.FeatureDetector_create("SIFT")
kps = detector.detect(gray)
# extract features from the image
extractor = cv2.DescriptorExtractor_create("SIFT")
(kps, features) = extractor.compute(gray, kps)
# convert the keypoints from KeyPoint objects to NumPy
# arrays
kps = np.float32([kp.pt for kp in kps])
# return a tuple of keypoints and features
return (kps, features)
As the name suggests, the
detectAndDescribemethod accepts an image, then detects keypoints and extracts local invariant descriptors. In our implementation we use the Difference of Gaussian (DoG) keypoint detector and the SIFT feature extractor.
On Line 52 we check to see if we are using OpenCV 3.X. If we are, then we use the
cv2.xfeatures2d.SIFT_createfunction to instantiate both our DoG keypoint detector and SIFT feature extractor. A call to
detectAndComputehandles extracting the keypoints and features (Lines 54 and 55).
It’s important to note that you must have compiled OpenCV 3.X with opencv_contrib support enabled. If you did not, you’ll get an error such as
AttributeError: 'module' object has no attribute 'xfeatures2d'. If that’s the case, head over to my OpenCV 3 tutorials page where I detail how to install OpenCV 3 with
opencv_contribsupport enabled for a variety of operating systems and Python versions.
Lines 58-65 handle if we are using OpenCV 2.4. The
cv2.FeatureDetector_createfunction instantiates our keypoint detector (DoG). A call to
detectreturns our set of keypoints.
From there, we need to initialize
cv2.DescriptorExtractor_createusing the
SIFTkeyword to setup our SIFT feature
extractor. Calling the
computemethod of the
extractorreturns a set of feature vectors which quantify the region surrounding each of the detected keypoints in the image.
Finally, our keypoints are converted from
KeyPointobjects to a NumPy array (Line 69) and returned to the calling method (Line 72).
Next up, let’s look at the
matchKeypointsmethod:
# import the necessary packages
import numpy as np
import imutils
import cv2
class Stitcher:
def __init__(self):
# determine if we are using OpenCV v3.X
self.isv3 = imutils.is_cv3()
def stitch(self, images, ratio=0.75, reprojThresh=4.0,
showMatches=False):
# unpack the images, then detect keypoints and extract
# local invariant descriptors from them
(imageB, imageA) = images
(kpsA, featuresA) = self.detectAndDescribe(imageA)
(kpsB, featuresB) = self.detectAndDescribe(imageB)
# match features between the two images
M = self.matchKeypoints(kpsA, kpsB,
featuresA, featuresB, ratio, reprojThresh)
# if the match is None, then there aren't enough matched
# keypoints to create a panorama
if M is None:
return None
# otherwise, apply a perspective warp to stitch the images
# together
(matches, H, status) = M
result = cv2.warpPerspective(imageA, H,
(imageA.shape[1] + imageB.shape[1], imageA.shape[0]))
result[0:imageB.shape[0], 0:imageB.shape[1]] = imageB
# check to see if the keypoint matches should be visualized
if showMatches:
vis = self.drawMatches(imageA, imageB, kpsA, kpsB, matches,
status)
# return a tuple of the stitched image and the
# visualization
return (result, vis)
# return the stitched image
return result
def detectAndDescribe(self, image):
# convert the image to grayscale
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# check to see if we are using OpenCV 3.X
if self.isv3:
# detect and extract features from the image
descriptor = cv2.xfeatures2d.SIFT_create()
(kps, features) = descriptor.detectAndCompute(image, None)
# otherwise, we are using OpenCV 2.4.X
else:
# detect keypoints in the image
detector = cv2.FeatureDetector_create("SIFT")
kps = detector.detect(gray)
# extract features from the image
extractor = cv2.DescriptorExtractor_create("SIFT")
(kps, features) = extractor.compute(gray, kps)
# convert the keypoints from KeyPoint objects to NumPy
# arrays
kps = np.float32([kp.pt for kp in kps])
# return a tuple of keypoints and features
return (kps, features)
def matchKeypoints(self, kpsA, kpsB, featuresA, featuresB,
ratio, reprojThresh):
# compute the raw matches and initialize the list of actual
# matches
matcher = cv2.DescriptorMatcher_create("BruteForce")
rawMatches = matcher.knnMatch(featuresA, featuresB, 2)
matches = []
# loop over the raw matches
for m in rawMatches:
# ensure the distance is within a certain ratio of each
# other (i.e. Lowe's ratio test)
if len(m) == 2 and m[0].distance < m[1].distance * ratio:
matches.append((m[0].trainIdx, m[0].queryIdx))
The
matchKeypointsfunction requires four arguments: the keypoints and feature vectors associated with the first image, followed by the keypoints and feature vectors associated with the second image. David Lowe’s
ratiotest variable and RANSAC re-projection threshold are also be supplied.
Matching features together is actually a fairly straightforward process. We simply loop over the descriptors from both images, compute the distances, and find the smallest distance for each pair of descriptors. Since this is a very common practice in computer vision, OpenCV has a built-in function called
cv2.DescriptorMatcher_createthat constructs the feature matcher for us. The
BruteForcevalue indicates that we are going to exhaustively compute the Euclidean distance between all feature vectors from both images and find the pairs of descriptors that have the smallest distance.
A call to
knnMatchon Line 79 performs k-NN matching between the two feature vector sets using k=2 (indicating the top two matches for each feature vector are returned).
The reason we want the top two matches rather than just the top one match is because we need to apply David Lowe’s ratio test for false-positive match pruning.
Again, Line 79 computes the
rawMatchesfor each pair of descriptors — but there is a chance that some of these pairs are false positives, meaning that the image patches are not actually true matches. In an attempt to prune these false-positive matches, we can loop over each of the
rawMatchesindividually (Line 83) and apply Lowe’s ratio test, which is used to determine high-quality feature matches. Typical values for Lowe’s ratio are normally in the range [0.7, 0.8].
Once we have obtained the
matchesusing Lowe’s ratio test, we can compute the homography between the two sets of keypoints:
# import the necessary packages
import numpy as np
import imutils
import cv2
class Stitcher:
def __init__(self):
# determine if we are using OpenCV v3.X
self.isv3 = imutils.is_cv3()
def stitch(self, images, ratio=0.75, reprojThresh=4.0,
showMatches=False):
# unpack the images, then detect keypoints and extract
# local invariant descriptors from them
(imageB, imageA) = images
(kpsA, featuresA) = self.detectAndDescribe(imageA)
(kpsB, featuresB) = self.detectAndDescribe(imageB)
# match features between the two images
M = self.matchKeypoints(kpsA, kpsB,
featuresA, featuresB, ratio, reprojThresh)
# if the match is None, then there aren't enough matched
# keypoints to create a panorama
if M is None:
return None
# otherwise, apply a perspective warp to stitch the images
# together
(matches, H, status) = M
result = cv2.warpPerspective(imageA, H,
(imageA.shape[1] + imageB.shape[1], imageA.shape[0]))
result[0:imageB.shape[0], 0:imageB.shape[1]] = imageB
# check to see if the keypoint matches should be visualized
if showMatches:
vis = self.drawMatches(imageA, imageB, kpsA, kpsB, matches,
status)
# return a tuple of the stitched image and the
# visualization
return (result, vis)
# return the stitched image
return result
def detectAndDescribe(self, image):
# convert the image to grayscale
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# check to see if we are using OpenCV 3.X
if self.isv3:
# detect and extract features from the image
descriptor = cv2.xfeatures2d.SIFT_create()
(kps, features) = descriptor.detectAndCompute(image, None)
# otherwise, we are using OpenCV 2.4.X
else:
# detect keypoints in the image
detector = cv2.FeatureDetector_create("SIFT")
kps = detector.detect(gray)
# extract features from the image
extractor = cv2.DescriptorExtractor_create("SIFT")
(kps, features) = extractor.compute(gray, kps)
# convert the keypoints from KeyPoint objects to NumPy
# arrays
kps = np.float32([kp.pt for kp in kps])
# return a tuple of keypoints and features
return (kps, features)
def matchKeypoints(self, kpsA, kpsB, featuresA, featuresB,
ratio, reprojThresh):
# compute the raw matches and initialize the list of actual
# matches
matcher = cv2.DescriptorMatcher_create("BruteForce")
rawMatches = matcher.knnMatch(featuresA, featuresB, 2)
matches = []
# loop over the raw matches
for m in rawMatches:
# ensure the distance is within a certain ratio of each
# other (i.e. Lowe's ratio test)
if len(m) == 2 and m[0].distance < m[1].distance * ratio:
matches.append((m[0].trainIdx, m[0].queryIdx))
# computing a homography requires at least 4 matches
if len(matches) > 4:
# construct the two sets of points
ptsA = np.float32([kpsA[i] for (_, i) in matches])
ptsB = np.float32([kpsB[i] for (i, _) in matches])
# compute the homography between the two sets of points
(H, status) = cv2.findHomography(ptsA, ptsB, cv2.RANSAC,
reprojThresh)
# return the matches along with the homograpy matrix
# and status of each matched point
return (matches, H, status)
# otherwise, no homograpy could be computed
return None
Computing a homography between two sets of points requires at a bare minimum an initial set of four matches. For a more reliable homography estimation, we should have substantially more than just four matched points.
Finally, the last method in our
Stitchermethod,
drawMatchesis used to visualize keypoint correspondences between two images:
# import the necessary packages
import numpy as np
import imutils
import cv2
class Stitcher:
def __init__(self):
# determine if we are using OpenCV v3.X
self.isv3 = imutils.is_cv3()
def stitch(self, images, ratio=0.75, reprojThresh=4.0,
showMatches=False):
# unpack the images, then detect keypoints and extract
# local invariant descriptors from them
(imageB, imageA) = images
(kpsA, featuresA) = self.detectAndDescribe(imageA)
(kpsB, featuresB) = self.detectAndDescribe(imageB)
# match features between the two images
M = self.matchKeypoints(kpsA, kpsB,
featuresA, featuresB, ratio, reprojThresh)
# if the match is None, then there aren't enough matched
# keypoints to create a panorama
if M is None:
return None
# otherwise, apply a perspective warp to stitch the images
# together
(matches, H, status) = M
result = cv2.warpPerspective(imageA, H,
(imageA.shape[1] + imageB.shape[1], imageA.shape[0]))
result[0:imageB.shape[0], 0:imageB.shape[1]] = imageB
# check to see if the keypoint matches should be visualized
if showMatches:
vis = self.drawMatches(imageA, imageB, kpsA, kpsB, matches,
status)
# return a tuple of the stitched image and the
# visualization
return (result, vis)
# return the stitched image
return result
def detectAndDescribe(self, image):
# convert the image to grayscale
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# check to see if we are using OpenCV 3.X
if self.isv3:
# detect and extract features from the image
descriptor = cv2.xfeatures2d.SIFT_create()
(kps, features) = descriptor.detectAndCompute(image, None)
# otherwise, we are using OpenCV 2.4.X
else:
# detect keypoints in the image
detector = cv2.FeatureDetector_create("SIFT")
kps = detector.detect(gray)
# extract features from the image
extractor = cv2.DescriptorExtractor_create("SIFT")
(kps, features) = extractor.compute(gray, kps)
# convert the keypoints from KeyPoint objects to NumPy
# arrays
kps = np.float32([kp.pt for kp in kps])
# return a tuple of keypoints and features
return (kps, features)
def matchKeypoints(self, kpsA, kpsB, featuresA, featuresB,
ratio, reprojThresh):
# compute the raw matches and initialize the list of actual
# matches
matcher = cv2.DescriptorMatcher_create("BruteForce")
rawMatches = matcher.knnMatch(featuresA, featuresB, 2)
matches = []
# loop over the raw matches
for m in rawMatches:
# ensure the distance is within a certain ratio of each
# other (i.e. Lowe's ratio test)
if len(m) == 2 and m[0].distance < m[1].distance * ratio:
matches.append((m[0].trainIdx, m[0].queryIdx))
# computing a homography requires at least 4 matches
if len(matches) > 4:
# construct the two sets of points
ptsA = np.float32([kpsA[i] for (_, i) in matches])
ptsB = np.float32([kpsB[i] for (i, _) in matches])
# compute the homography between the two sets of points
(H, status) = cv2.findHomography(ptsA, ptsB, cv2.RANSAC,
reprojThresh)
# return the matches along with the homograpy matrix
# and status of each matched point
return (matches, H, status)
# otherwise, no homograpy could be computed
return None
def drawMatches(self, imageA, imageB, kpsA, kpsB, matches, status):
# initialize the output visualization image
(hA, wA) = imageA.shape[:2]
(hB, wB) = imageB.shape[:2]
vis = np.zeros((max(hA, hB), wA + wB, 3), dtype="uint8")
vis[0:hA, 0:wA] = imageA
vis[0:hB, wA:] = imageB
# loop over the matches
for ((trainIdx, queryIdx), s) in zip(matches, status):
# only process the match if the keypoint was successfully
# matched
if s == 1:
# draw the match
ptA = (int(kpsA[queryIdx][0]), int(kpsA[queryIdx][1]))
ptB = (int(kpsB[trainIdx][0]) + wA, int(kpsB[trainIdx][1]))
cv2.line(vis, ptA, ptB, (0, 255, 0), 1)
# return the visualization
return vis
This method requires that we pass in the two original images, the set of keypoints associated with each image, the initial matches after applying Lowe’s ratio test, and finally the
statuslist provided by the homography calculation. Using these variables, we can visualize the “inlier” keypoints by drawing a straight line from keypoint N in the first image to keypoint M in the second image.
Now that we have our
Stitcherclass defined, let’s move on to creating the
stitch.pydriver script:
# import the necessary packages
from pyimagesearch.panorama import Stitcher
import argparse
import imutils
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-f", "--first", required=True,
help="path to the first image")
ap.add_argument("-s", "--second", required=True,
help="path to the second image")
args = vars(ap.parse_args())
We start off by importing our required packages on Lines 2-5. Notice how we’ve placed the
panorama.pyand
Stitcherclass into the
pyimagesearchmodule just to keep our code tidy.
Note: If you are following along with this post and having trouble organizing your code, please be sure to download the source code using the form at the bottom of this post. The .zip of the code download will run out of the box without any errors.
From there, Lines 8-14 parse our command line arguments:
--first, which is the path to the first image in our panorama (the left-most image), and
--second, the path to the second image in the panorama (the right-most image).
Remember, these image paths need to be suppled in left-to-right order!
The rest of the
stitch.pydriver script simply handles loading our images, resizing them (so they can fit on our screen), and constructing our panorama:
# import the necessary packages
from pyimagesearch.panorama import Stitcher
import argparse
import imutils
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-f", "--first", required=True,
help="path to the first image")
ap.add_argument("-s", "--second", required=True,
help="path to the second image")
args = vars(ap.parse_args())
# load the two images and resize them to have a width of 400 pixels
# (for faster processing)
imageA = cv2.imread(args["first"])
imageB = cv2.imread(args["second"])
imageA = imutils.resize(imageA, width=400)
imageB = imutils.resize(imageB, width=400)
# stitch the images together to create a panorama
stitcher = Stitcher()
(result, vis) = stitcher.stitch([imageA, imageB], showMatches=True)
# show the images
cv2.imshow("Image A", imageA)
cv2.imshow("Image B", imageB)
cv2.imshow("Keypoint Matches", vis)
cv2.imshow("Result", result)
cv2.waitKey(0)
Once our images are loaded and resized, we initialize our
Stitcherclass on Line 23. We then call the
stitchmethod, passing in our two images (again, in left-to-right order) and indicate that we would like to visualize the keypoint matches between the two images.
Finally, Lines 27-31 display our output images to our screen.
Panorama stitching results
In mid-2014 I took a trip out to Arizona and Utah to enjoy the national parks. Along the way I stopped at many locations, including Bryce Canyon, Grand Canyon, and Sedona. Given that these areas contain beautiful scenic views, I naturally took a bunch of photos — some of which are perfect for constructing panoramas. I’ve included a sample of these images in today’s blog to demonstrate panorama stitching.
All that said, let’s give our OpenCV panorama stitcher a try. Open up a terminal and issue the following command:
$ python stitch.py --first images/bryce_left_01.png \
--second images/bryce_right_01.png
Figure 1: (Top) The two input images from Bryce canyon (in left-to-right order). (Bottom) The matched keypoint correspondences between the two images.
At the top of this figure, we can see two input images (resized to fit on my screen, the raw .jpg files are a much higher resolution). And on the bottom, we can see the matched keypoints between the two images.
Using these matched keypoints, we can apply a perspective transform and obtain the final panorama:
Figure 2: Constructing a panorama from our two input images.
As we can see, the two images have been successfully stitched together!
Note: On many of these example images, you’ll often see a visible “seam” running through the center of the stitched images. This is because I shot many of photos using either my iPhone or a digital camera with autofocus turned on, thus the focus is slightly different between each shot. Image stitching and panorama construction work best when you use the same focus for every photo. I never intended to use these vacation photos for image stitching, otherwise I would have taken care to adjust the camera sensors. In either case, just keep in mind the seam is due to varying sensor properties at the time I took the photo and was not intentional.
Let’s give another set of images a try:
$ python stitch.py --first images/bryce_left_02.png \
--second images/bryce_right_02.png
Figure 3: Another successful application of image stitching with OpenCV.
Again, our
Stitcherclass was able to construct a panorama from the two input images.
Now, let’s move on to the Grand Canyon:
$ python stitch.py --first images/grand_canyon_left_01.png \
--second images/grand_canyon_right_01.png
Figure 4: Applying image stitching and panorama construction using OpenCV.
In the above input images we can see heavy overlap between the two input images. The main addition to the panorama is towards the right side of the stitched images where we can see more of the “ledge” is added to the output.
Here’s another example from the Grand Canyon:
$ python stitch.py --first images/grand_canyon_left_02.png \
--second images/grand_canyon_right_02.png
Figure 5: Using image stitching to build a panorama using OpenCV and Python.
From this example, we can see that more of the huge expanse of the Grand Canyon has been added to the panorama.
Finally, let’s wrap up this blog post with an example image stitching from Sedona, AZ:
$ python stitch.py --first images/sedona_left_01.png \
--second images/sedona_right_01.png
Figure 6: One final example of applying image stitching.
Personally, I find the red rock country of Sedona to be one of the most beautiful areas I’ve ever visited. If you ever have a chance, definitely stop by — you won’t be disappointed.
So there you have it, image stitching and panorama construction using Python and OpenCV!
Summary
In this blog post we learned how to perform image stitching and panorama construction using OpenCV. Source code was provided for image stitching for both OpenCV 2.4 and OpenCV 3.
Our image stitching algorithm requires four steps: (1) detecting keypoints and extracting local invariant descriptors; (2) matching descriptors between images; (3) applying RANSAC to estimate the homography matrix; and (4) applying a warping transformation using the homography matrix.
While simple, this algorithm works well in practice when constructing panoramas for two images. In a future blog post, we’ll review how to construct panoramas and perform image stitching for more than two images.
Anyway, I hope you enjoyed this post! Be sure to use the form below to download the source code and give it a try.
Downloads:
The post OpenCV panorama stitching appeared first on PyImageSearch.
from PyImageSearch http://ift.tt/1OdNHZB
via IFTTT
Subscribe to:
Posts (Atom)