Fertility Specialists Medical Group is seeking anonymous egg donors! Visit our website, http://ift.tt/1lINVdQ for the initial application.
from Google Alert - anonymous http://ift.tt/29etvJu
via IFTTT
Saturday, July 2, 2016
Why Anonymous Keeps Hacking
In this lengthy investigation, Vice explores the inner workings and motivations of Anonymous.
from Google Alert - anonymous http://ift.tt/29kKwoq
via IFTTT
from Google Alert - anonymous http://ift.tt/29kKwoq
via IFTTT
This Android Hacking Group is making $500,000 per day
Own an Android smartphone? Hackers can secretly install malicious apps, games, and pop-up adverts on your smartphone remotely in order to make large sums of money. Security researchers at Cheetah Mobile have uncovered one of the world's largest and most prolific Trojan families, infecting millions of Android devices around the world. Dubbed Hummer, the notorious mobile trojan stealthily


from The Hacker News http://ift.tt/29BuqD0
via IFTTT
from The Hacker News http://ift.tt/29BuqD0
via IFTTT
New Meditation Meeting
When: Saturday, 12 AM Midnight Meditation Format: CMA spirituality meeting with meditation Type: Open Location: The Rec Room 4138 North ...
from Google Alert - anonymous http://ift.tt/29ljPAg
via IFTTT
from Google Alert - anonymous http://ift.tt/29ljPAg
via IFTTT
Juno Approaching Jupiter

Approaching over the north pole after nearly a five-year journey, Juno enjoys a perspective on Jupiter not often seen, even by spacecraft from Earth that usually swing by closer to Jupiter's equator. Looking down toward the ruling gas giant from a distance of 10.9 million kilometers, the spacecraft's JunoCam captured this image with Jupiter's nightside and orbiting entourage of four large Galilean moons on June 21. JunoCam is intended to provide close-up views of the gas giant's cloudy zoned and belted atmosphere. On July 4 (July 5 UT) Juno is set to burn its main engine to slow down and be captured into its own orbit around the giant planet. If all goes well, it will be the first spacecraft to orbit the poles of Jupiter, skimming to within 5,000 kilometers of the Jovian cloud tops during the 20 month mission. via NASA http://ift.tt/298taqm
Friday, July 1, 2016
ISS Daily Summary Report – 07/01/16
62 Progress (62P) Undock: 62 Progress (62P) Undock: 62P is scheduled to undock from Docking Compartment (DC) 1 tomorrow, July 2 at 10:48PM CDT. This morning, a test was performed on the TORU manual docking system when the Progress undocked from the ISS, backed to a distance of approximately 600 feet, and re-docked under manual control by the crew. 3D Printing in Zero-G Experiment Operations: After successfully printing calibration and compression coupons in the Microgravity Science Glovebox (MSG) earlier this week, today the ground team remotely operated the 3D printer to produce another 3D printed test coupon, concluding 3D printer operations for the week. 3D printer operations will resume next week. The 3D Printing In Zero-G experiment demonstrates that a 3D printer works normally in space. In general, a 3D printer extrudes streams of heated plastic, metal or other material, building layer on top of layer to create 3 dimensional objects. Testing a 3D printer using relatively low-temperature plastic feedstock on the International Space Station is the first step towards establishing an on-demand machine shop in space, a critical enabling component for deep-space crewed missions and in-space manufacturing. Expedite the Processing of Experiments to Space Station (EXPRESS) Rack-3 Laptop Computer (ELC) Operations: The Common Software Release 10 was successfully installed on the EXPRESS Rack-3 Laptop in preparation for European Modular Cultivation System (EMCS) maintenance activities scheduled next week. Habitability Human Factors Directed Observations: The crew recorded and submitted a walk-through video documenting observations of an area or activity providing insight related to human factors and habitability. The Habitability investigation collects observations about the relationship between crew members and their environment on the International Space Station. Observations can help spacecraft designers understand how much habitable volume is required, and whether a mission’s duration impacts how much space crew members need. Advanced Resistive Exercise Device (ARED): The crew completed this regularly scheduled quarterly maintenance to inspect the x-rotation dashpots, cycle the main arm through full range of motion, and grease the Vibration Isolation and Stabilization (VIS) rails and rollers. Treadmill 2 (T2) Acoustic Blanket Installation: The crew installed four acoustic blankets around T2 in an effort to reduce noise levels in Node 3. Sound Level Meter (SLM) measurements were taken before, during and after installation of the blankets to verify the technology works as designed. Global Position System (GPS) Receiver/Processor 1 (GPS R/P 1) Ring Laser Gyro (RLG) Failure – On June 30th, during the OPM attitude maneuver to –XVV for the 62P TORU Test, the flight control team noted that the Space Integrated Global Positioning System/ Inertial Navigation System (SIGI)1 INS Y-channel (ISS Z-axis) rate differences were not tracking with those of the SIGI2 INS. SIGI1 INS Y-channel (ISS Z-axis) rate gyro appears to be failed. The GPS systems within both SIGIs continue to output good attitude and state measurements. Both the US GN&C attitude determination (AD) and state determination (SD) systems are behaving nominally and are not reliant on the performance of the ring laser gyros within either of the SIGIs. GNC is considered to be in a stable configuration. Today’s Planned Activities All activities were completed unless otherwise noted. Closing Window Shutters 6, 8, 9, 12, 13, 14 СОЖ Maintenance MPEG2 Multicast Test via Ku-band Activation of MPEG2 Multicast TV Monitoring Progress 431 Undocking and Re-docking to DC1 in TORU r/g 2680 On MCC GO Activation of mpeg2 multicast video recording mode Close Applications and Downlink MPEG2 Multicast Video via OCA Progress 432 [AO] Transfers and IMS Ops / r/g 1812, 1832 Comm reconfig for nominal ops / Communications System Progress 432 [AO] Transfers and IMS Ops / r/g 1812, 1832 ISS crew and ГОГУ r/g 2662 3DP Printed Coupon Removal and Stowage JEM System Laptop Terminal Reboot HAM radio session from Columbus CMS ARED Quarterly Maintenance Earth photo/video ops / r/g 2682 Progress 432 [AO] Transfers and IMS Ops / r/g 1812, 1832 TReK Laptop Reconfig WRS Recycle Tank Fill from EDV OTKLIK. Sensor functional test and point of impact accuracy check (Part 2) r/g 2681 EXPRESS-3 Laptop Computer (ELC) CLS 10 load Insert SNFM DVD into EXPRESS Rack Laptop 47S Crew SSC Laptops, Wireless connection configuration IMS Delta File Prep Food Frequency Questionnaire HABIT Conference HABIT Camcorder Setup T2 Installation of Acoustic Blanket and T2 SLM Measurements in Node 3 Sound Level Meter (SLM) Setup and Operations in Node 3, Airlock, Node 2 and FGB SLM data transfer HABIT Task Video End USOS Window Shutter Close Remove SNFM DVD from EXPRESS Rack Laptop Completed Task List Items None Ground Activities All activities were completed unless otherwise noted. TORU test Nominal ground commanding Three-Day Look Ahead: Saturday, 07/02: Crew day off, housekeeping Sunday, 07/03: Crew off duty Monday, 07/04: Crew holiday QUICK ISS Status – Environmental Control Group: Component Status Elektron On Vozdukh Manual [СКВ] 1 – SM Air Conditioner System (“SKV1”) Off [СКВ] 2 – SM Air Conditioner System (“SKV2”) Off Carbon Dioxide Removal Assembly (CDRA) Lab Standby Carbon Dioxide Removal Assembly (CDRA) Node 3 Operate Major Constituent Analyzer (MCA) Lab Idle Major Constituent Analyzer (MCA) Node 3 Operate Oxygen Generation Assembly (OGA) Process Urine Processing Assembly (UPA) Standby Trace Contaminant Control System (TCCS) Lab Off Trace Contaminant Control System (TCCS) Node 3 Full Up
from ISS On-Orbit Status Report http://ift.tt/29kTm5H
via IFTTT
from ISS On-Orbit Status Report http://ift.tt/29kTm5H
via IFTTT
Allow anonymous users to authenticate
I would like to be able to allow anonymous users to authenticate with Instagram, but when attempting to do so there is a PDOException related to ...
from Google Alert - anonymous http://ift.tt/299HU8C
via IFTTT
from Google Alert - anonymous http://ift.tt/299HU8C
via IFTTT
Ravens: TE Darren Waller suspended 4 games for violating the NFL's substance abuse policy; 2 catches in 6 games in 2015 (ESPN)
from ESPN http://ift.tt/17lH5T2
via IFTTT
via IFTTT
Access Denied for anonymous users
... when I'm logged off I get the "Access denied page". Is there a setting I have to set to be able to print the node as an anonymous user?? Thanx.
from Google Alert - anonymous http://ift.tt/296s8Kz
via IFTTT
from Google Alert - anonymous http://ift.tt/296s8Kz
via IFTTT
Some anonymous players always use computers
#3 You have a choice, you can exclude anonymous users from your unrated games. Check the "Members only" box when you create a game.
from Google Alert - anonymous http://ift.tt/29cQwfq
via IFTTT
from Google Alert - anonymous http://ift.tt/29cQwfq
via IFTTT
ISS Daily Summary Report – 06/30/16
Synchronized Position Hold Engage and Reorient Experimental Satellites (SPHERES) Maintenance Run: Yesterday during SPHERES maintenance setup, the crew discovered corrosion on the battery terminals in the battery compartments of beacons 1, 2, and the spare beacon. Today the crew successfully removed the corrosion from beacons 1 and 2 and initiated the maintenance run. The first part of the run provided data that may aide ground teams in improving communication between satellites. The second portion of the run was not completed due to a hard drive installation issue, resulting in no data collection. However the issues were resolved and teams estimate that a majority of the desired data was collected from today’s activities. SPHERES are bowling-ball sized satellites that provide a test bed for development and research into multi-body formation flying, multi-spacecraft control algorithms and free-flying physical and material science investigations. Up to three self-contained free-flying satellites can fly within the cabin of the ISS, performing flight formations, testing of control algorithms or as a platform for investigations requiring this unique free-flying test environment. Each satellite is a self-contained unit with power, propulsion, computers, navigation equipment, and provides physical and electrical connections (via standardized expansion ports) for Principle Investigator (PI) provided hardware and sensors. Node 2 (N2) Common Cabin Air Assembly (CCAA) Inlet Fan: On June 5, the N2 CCAA inlet fan failed off due to high current draw. The failure is attributed to increased mechanical resistance to rotation. The fan was restarted and its current draw decreased. Review of data after the failure indicated a slow rise in current over several days preceding the failure. The fan current data is now showing a similar rise and may trigger a shutdown within 4-6 days. Ground teams are monitoring the fan current and are prepared for the crew to replace the N2 CCAA inlet Orbital Replacement Unit (ORU), which includes the fan, if necessary. Express Logistics Carrier (ELC) Software Update: The software update to ELC version 4 for the ExPCAs (Express Carrier Avionics) on the 4 ELCs was completed yesterday. The new software improves the process for modifying configurations and adds capabilities for future payloads on the ELCs. Today’s Planned Activities All activities were completed unless otherwise noted. ABOUT GAGARIN FROM SPACE. HAM Radio Session with Ufa r/g 2669 SPHERES Battery Stowage SPHERES. Maintenance Run СОЖ Maintenance SPHERES Data Export Dragon Prepack PAO Hardware Setup Crew Prep for PAO PAO Event Daily Planning Conference USOS Window Shutter Close ISS HAM – RADIO Deactivation Completed Task List Items None Ground Activities All activities were completed unless otherwise noted. SPHERES support Nominal ground commanding Three-Day Look Ahead: Friday, 07/01: 3D Printer Coupon prints and retrievals, ARED quarterly maintenance, T2 acoustic blanket install & SLM measurements Saturday, 07/02: Crew day off, housekeeping Sunday, 07/03: Crew off duty QUICK ISS Status – Environmental Control Group: Component Status Elektron On Vozdukh Manual [СКВ] 1 – SM Air Conditioner System (“SKV1”) Off [СКВ] 2 – SM Air Conditioner System (“SKV2”) On Carbon Dioxide Removal Assembly (CDRA) Lab Standby Carbon Dioxide Removal Assembly (CDRA) Node 3 Operate Major Constituent Analyzer (MCA) Lab Idle Major Constituent Analyzer (MCA) Node 3 Operate Oxygen Generation Assembly (OGA) Process Urine Processing Assembly (UPA) Standby Trace Contaminant Control System (TCCS) Lab Off Trace Contaminant Control System (TCCS) Node 3 Full Up
from ISS On-Orbit Status Report http://ift.tt/29bhic6
via IFTTT
from ISS On-Orbit Status Report http://ift.tt/29bhic6
via IFTTT
How to Crack Android Full Disk Encryption on Qualcomm Devices
The heated battle between Apple and the FBI provoked a lot of talk about Encryption – the technology that has been used to keep all your bits and bytes as safe as possible. We can not say a lot about Apple's users, but Android users are at severe risk when it comes to encryption of their personal and sensitive data. Android's full-disk encryption can be cracked much more easily than expected

from The Hacker News http://ift.tt/29ahhSW
via IFTTT
from The Hacker News http://ift.tt/29ahhSW
via IFTTT
Apple Patents Technology to remotely disable your iPhone Camera at Concerts
Here's something you'll not like at all: Apple has been awarded a patent for technology that would prevent you from snapping pictures and shooting videos with your iPhone or iPad at places or events, like concerts or museums, where it might be prohibited or inappropriate. The patent, granted on Tuesday by the United States Patents and Trademark Office, is highly technical. <!-- adsense -->

from The Hacker News http://ift.tt/29gy6wn
via IFTTT
from The Hacker News http://ift.tt/29gy6wn
via IFTTT
anonymous-sums
anonymous-sums. Anonymous sum types http://ift.tt/1ZRRZuaanonymous-sums. Version on this page: 0.4.0.0. LTS Haskell 6.5: 0.4.0.0.
from Google Alert - anonymous http://ift.tt/295ejfk
via IFTTT
from Google Alert - anonymous http://ift.tt/295ejfk
via IFTTT
Google finally announces Android N's name and It's not Nutella
No, it's not Nutella. Google has finally announced the official name of the latest version of its Android mobile software, codenamed Android N: "Nougat." Yes, the next version of sugary snack-themed Android and the successor to Android Marshmallow will now be known as Android Nougat, the company revealed on Snapchat and Twitter. <!-- adsense --> The announcement comes days after Google set

from The Hacker News http://ift.tt/29ag150
via IFTTT
from The Hacker News http://ift.tt/29ag150
via IFTTT
MLB: Hyun Soo Kim homers in the 7th inning for Orioles' 56th home run of month, passing 1996 Athletics for most in June (ESPN)
from ESPN http://ift.tt/1eW1vUH
via IFTTT
via IFTTT
The New World Atlas of Artificial Sky Brightness
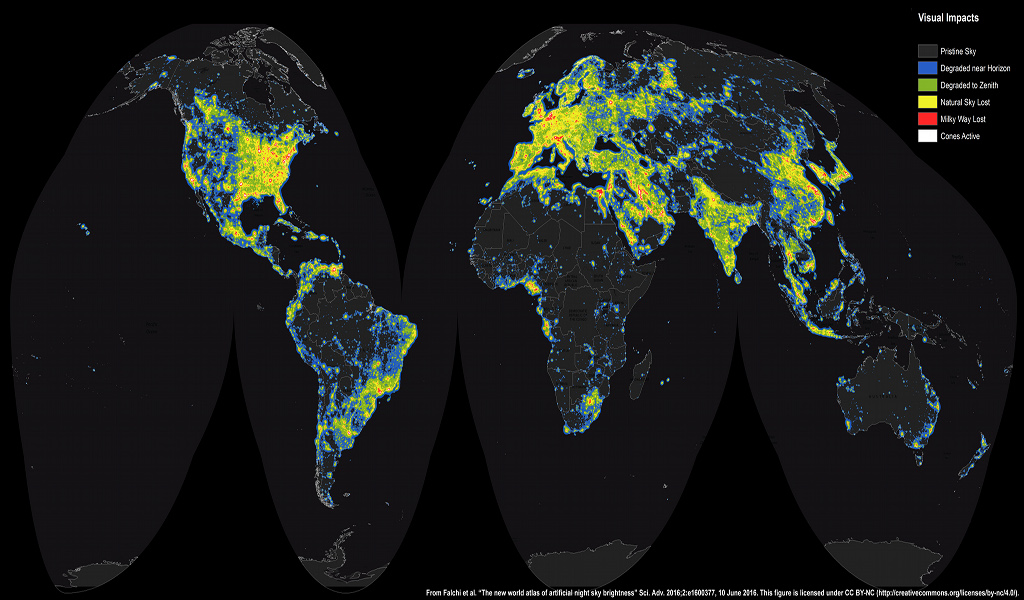
How far are you from a naturally dark night sky? In increasing steps, this world map (medium | large) shows the effect of artificial night sky brightness on the visual appearance of the night sky. The brightness was modeled using high resolution satellite data and fit to thousands of night sky brightness measurements in recent work. Color-coded levels are compared to the natural sky brightness level for your location. For example, artificial sky brightness levels in yellow alter the natural appearance of the night sky. In red they hide the Milky Way in an artificial luminous fog. The results indicate that the historically common appearance of our galaxy at night is now lost for more than one-third of humanity. That includes 60% of Europeans and almost 80% of North Americans, along with inhabitants of other densely populated, light-polluted regions of planet Earth. via NASA http://ift.tt/2970a3C
Thursday, June 30, 2016
Orioles: P T.J. McFarland (left knee) placed on the 15-day disabled list; P Vance Worley (groin) activated from the DL (ESPN)
from ESPN http://ift.tt/1eW1vUH
via IFTTT
via IFTTT
Anonymous should be able to edit their user profile
Navigating to user/0/edit should allow anonymous to edit their profile.
from Google Alert - anonymous http://ift.tt/296j0WT
via IFTTT
from Google Alert - anonymous http://ift.tt/296j0WT
via IFTTT
Swift: Compiled Inference for Probabilistic Programming Languages. (arXiv:1606.09242v1 [cs.AI])
A probabilistic program defines a probability measure over its semantic structures. One common goal of probabilistic programming languages (PPLs) is to compute posterior probabilities for arbitrary models and queries, given observed evidence, using a generic inference engine. Most PPL inference engines---even the compiled ones---incur significant runtime interpretation overhead, especially for contingent and open-universe models. This paper describes Swift, a compiler for the BLOG PPL. Swift-generated code incorporates optimizations that eliminate interpretation overhead, maintain dynamic dependencies efficiently, and handle memory management for possible worlds of varying sizes. Experiments comparing Swift with other PPL engines on a variety of inference problems demonstrate speedups ranging from 12x to 326x.
DONATE to arXiv: One hundred percent of your contribution will fund improvements and new initiatives to benefit arXiv's global scientific community. Please join the Simons Foundation and our generous member organizations and research labs in supporting arXiv. https://goo.gl/QIgRpr
from cs.AI updates on arXiv.org http://ift.tt/29a7xa5
via IFTTT
Compression of Neural Machine Translation Models via Pruning. (arXiv:1606.09274v1 [cs.AI])
Neural Machine Translation (NMT), like many other deep learning domains, typically suffers from over-parameterization, resulting in large storage sizes. This paper examines three simple magnitude-based pruning schemes to compress NMT models, namely class-blind, class-uniform, and class-distribution, which differ in terms of how pruning thresholds are computed for the different classes of weights in the NMT architecture. We demonstrate the efficacy of weight pruning as a compression technique for a state-of-the-art NMT system. We show that an NMT model with over 200 million parameters can be pruned by 40% with very little performance loss as measured on the WMT'14 English-German translation task. This sheds light on the distribution of redundancy in the NMT architecture. Our main result is that with retraining, we can recover and even surpass the original performance with an 80%-pruned model.
DONATE to arXiv: One hundred percent of your contribution will fund improvements and new initiatives to benefit arXiv's global scientific community. Please join the Simons Foundation and our generous member organizations and research labs in supporting arXiv. https://goo.gl/QIgRpr
from cs.AI updates on arXiv.org http://ift.tt/29hkhzv
via IFTTT
How Many Folders Do You Really Need?. (arXiv:1606.09296v1 [cs.AI])
Email classification is still a mostly manual task. Consequently, most Web mail users never define a single folder. Recently however, automatic classification offering the same categories to all users has started to appear in some Web mail clients, such as AOL or Gmail. We adopt this approach, rather than previous (unsuccessful) personalized approaches because of the change in the nature of consumer email traffic, which is now dominated by (non-spam) machine-generated email. We propose here a novel approach for (1) automatically distinguishing between personal and machine-generated email and (2) classifying messages into latent categories, without requiring users to have defined any folder. We report how we have discovered that a set of 6 "latent" categories (one for human- and the others for machine-generated messages) can explain a significant portion of email traffic. We describe in details the steps involved in building a Web-scale email categorization system, from the collection of ground-truth labels, the selection of features to the training of models. Experimental evaluation was performed on more than 500 billion messages received during a period of six months by users of Yahoo mail service, who elected to be part of such research studies. Our system achieved precision and recall rates close to 90% and the latent categories we discovered were shown to cover 70% of both email traffic and email search queries. We believe that these results pave the way for a change of approach in the Web mail industry, and could support the invention of new large-scale email discovery paradigms that had not been possible before.
DONATE to arXiv: One hundred percent of your contribution will fund improvements and new initiatives to benefit arXiv's global scientific community. Please join the Simons Foundation and our generous member organizations and research labs in supporting arXiv. https://goo.gl/QIgRpr
from cs.AI updates on arXiv.org http://ift.tt/29a7ZoC
via IFTTT
Learning Crosslingual Word Embeddings without Bilingual Corpora. (arXiv:1606.09403v1 [cs.CL])
Crosslingual word embeddings represent lexical items from different languages in the same vector space, enabling transfer of NLP tools. However, previous attempts had expensive resource requirements, difficulty incorporating monolingual data or were unable to handle polysemy. We address these drawbacks in our method which takes advantage of a high coverage dictionary in an EM style training algorithm over monolingual corpora in two languages. Our model achieves state-of-the-art performance on bilingual lexicon induction task exceeding models using large bilingual corpora, and competitive results on the monolingual word similarity and cross-lingual document classification task.
DONATE to arXiv: One hundred percent of your contribution will fund improvements and new initiatives to benefit arXiv's global scientific community. Please join the Simons Foundation and our generous member organizations and research labs in supporting arXiv. https://goo.gl/QIgRpr
from cs.AI updates on arXiv.org http://ift.tt/29hkYbZ
via IFTTT
Clique-Width and Directed Width Measures for Answer-Set Programming. (arXiv:1606.09449v1 [cs.AI])
Disjunctive Answer Set Programming (ASP) is a powerful declarative programming paradigm whose main decision problems are located on the second level of the polynomial hierarchy. Identifying tractable fragments and developing efficient algorithms for such fragments are thus important objectives in order to complement the sophisticated ASP systems available to date. Hard problems can become tractable if some problem parameter is bounded by a fixed constant; such problems are then called fixed-parameter tractable (FPT). While several FPT results for ASP exist, parameters that relate to directed or signed graphs representing the program at hand have been neglected so far. In this paper, we first give some negative observations showing that directed width measures on the dependency graph of a program do not lead to FPT results. We then consider the graph parameter of signed clique-width and present a novel dynamic programming algorithm that is FPT w.r.t. this parameter. Clique-width is more general than the well-known treewidth, and, to the best of our knowledge, ours is the first FPT algorithm for bounded clique-width for reasoning problems beyond SAT.
DONATE to arXiv: One hundred percent of your contribution will fund improvements and new initiatives to benefit arXiv's global scientific community. Please join the Simons Foundation and our generous member organizations and research labs in supporting arXiv. https://goo.gl/QIgRpr
from cs.AI updates on arXiv.org http://ift.tt/29a7f35
via IFTTT
Probabilistic Reasoning in the Description Logic ALCP with the Principle of Maximum Entropy (Full Version). (arXiv:1606.09521v1 [cs.AI])
A central question for knowledge representation is how to encode and handle uncertain knowledge adequately. We introduce the probabilistic description logic ALCP that is designed for representing context-dependent knowledge, where the actual context taking place is uncertain. ALCP allows the expression of logical dependencies on the domain and probabilistic dependencies on the possible contexts. In order to draw probabilistic conclusions, we employ the principle of maximum entropy. We provide reasoning algorithms for this logic, and show that it satisfies several desirable properties of probabilistic logics.
DONATE to arXiv: One hundred percent of your contribution will fund improvements and new initiatives to benefit arXiv's global scientific community. Please join the Simons Foundation and our generous member organizations and research labs in supporting arXiv. https://goo.gl/QIgRpr
from cs.AI updates on arXiv.org http://ift.tt/29hkLWe
via IFTTT
Ordering as privileged information. (arXiv:1606.09577v1 [cs.AI])
We propose to accelerate the rate of convergence of the pattern recognition task by directly minimizing the variance diameters of certain hypothesis spaces, which are critical quantities in fast-convergence results.We show that the variance diameters can be controlled by dividing hypothesis spaces into metric balls based on a new order metric. This order metric can be minimized as an ordinal regression problem, leading to a LUPI (Learning Using Privileged Information) application where we take the privileged information as some desired ordering, and construct a faster-converging hypothesis space by empirically restricting some larger hypothesis space according to that ordering. We give a risk analysis of the approach. We discuss the difficulties with model selection and give an innovative technique for selecting multiple model parameters. Finally, we provide some data experiments.
DONATE to arXiv: One hundred percent of your contribution will fund improvements and new initiatives to benefit arXiv's global scientific community. Please join the Simons Foundation and our generous member organizations and research labs in supporting arXiv. https://goo.gl/QIgRpr
from cs.AI updates on arXiv.org http://ift.tt/29a7mvj
via IFTTT
Performance Based Evaluation of Various Machine Learning Classification Techniques for Chronic Kidney Disease Diagnosis. (arXiv:1606.09581v1 [cs.LG])
Areas where Artificial Intelligence (AI) & related fields are finding their applications are increasing day by day, moving from core areas of computer science they are finding their applications in various other domains.In recent times Machine Learning i.e. a sub-domain of AI has been widely used in order to assist medical experts and doctors in the prediction, diagnosis and prognosis of various diseases and other medical disorders. In this manuscript the authors applied various machine learning algorithms to a problem in the domain of medical diagnosis and analyzed their efficiency in predicting the results. The problem selected for the study is the diagnosis of the Chronic Kidney Disease.The dataset used for the study consists of 400 instances and 24 attributes. The authors evaluated 12 classification techniques by applying them to the Chronic Kidney Disease data. In order to calculate efficiency, results of the prediction by candidate methods were compared with the actual medical results of the subject.The various metrics used for performance evaluation are predictive accuracy, precision, sensitivity and specificity. The results indicate that decision-tree performed best with nearly the accuracy of 98.6%, sensitivity of 0.9720, precision of 1 and specificity of 1.
DONATE to arXiv: One hundred percent of your contribution will fund improvements and new initiatives to benefit arXiv's global scientific community. Please join the Simons Foundation and our generous member organizations and research labs in supporting arXiv. https://goo.gl/QIgRpr
from cs.AI updates on arXiv.org http://ift.tt/29hkh2t
via IFTTT
Contextual Symmetries in Probabilistic Graphical Models. (arXiv:1606.09594v1 [cs.AI])
An important approach for efficient inference in probabilistic graphical models exploits symmetries among objects in the domain. Symmetric variables (states) are collapsed into meta-variables (meta-states) and inference algorithms are run over the lifted graphical model instead of the flat one. Our paper extends existing definitions of symmetry by introducing the novel notion of contextual symmetry. Two states that are not globally symmetric, can be contextually symmetric under some specific assignment to a subset of variables, referred to as the context variables. Contextual symmetry subsumes previous symmetry definitions and can rep resent a large class of symmetries not representable earlier. We show how to compute contextual symmetries by reducing it to the problem of graph isomorphism. We extend previous work on exploiting symmetries in the MCMC framework to the case of contextual symmetries. Our experiments on several domains of interest demonstrate that exploiting contextual symmetries can result in significant computational gains.
DONATE to arXiv: One hundred percent of your contribution will fund improvements and new initiatives to benefit arXiv's global scientific community. Please join the Simons Foundation and our generous member organizations and research labs in supporting arXiv. https://goo.gl/QIgRpr
from cs.AI updates on arXiv.org http://ift.tt/29a6Yx3
via IFTTT
A Permutation-based Model for Crowd Labeling: Optimal Estimation and Robustness. (arXiv:1606.09632v1 [cs.LG])
The aggregation and denoising of crowd labeled data is a task that has gained increased significance with the advent of crowdsourcing platforms and massive datasets. In this paper, we propose a permutation-based model for crowd labeled data that is a significant generalization of the common Dawid-Skene model, and introduce a new error metric by which to compare different estimators. Working in a high-dimensional non-asymptotic framework that allows both the number of workers and tasks to scale, we derive optimal rates of convergence for the permutation-based model. We show that the permutation-based model offers significant robustness in estimation due to its richness, while surprisingly incurring only a small additional statistical penalty as compared to the Dawid-Skene model. Finally, we propose a computationally-efficient method, called the OBI-WAN estimator, that is uniformly optimal over a class intermediate between the permutation-based and the Dawid-Skene models, and is uniformly consistent over the entire permutation-based model class. In contrast, the guarantees for estimators available in prior literature are sub-optimal over the original Dawid-Skene model.
DONATE to arXiv: One hundred percent of your contribution will fund improvements and new initiatives to benefit arXiv's global scientific community. Please join the Simons Foundation and our generous member organizations and research labs in supporting arXiv. https://goo.gl/QIgRpr
from cs.AI updates on arXiv.org http://ift.tt/29hkVNl
via IFTTT
Lifted Region-Based Belief Propagation. (arXiv:1606.09637v1 [cs.AI])
Due to the intractable nature of exact lifted inference, research has recently focused on the discovery of accurate and efficient approximate inference algorithms in Statistical Relational Models (SRMs), such as Lifted First-Order Belief Propagation. FOBP simulates propositional factor graph belief propagation without constructing the ground factor graph by identifying and lifting over redundant message computations. In this work, we propose a generalization of FOBP called Lifted Generalized Belief Propagation, in which both the region structure and the message structure can be lifted. This approach allows more of the inference to be performed intra-region (in the exact inference step of BP), thereby allowing simulation of propagation on a graph structure with larger region scopes and fewer edges, while still maintaining tractability. We demonstrate that the resulting algorithm converges in fewer iterations to more accurate results on a variety of SRMs.
DONATE to arXiv: One hundred percent of your contribution will fund improvements and new initiatives to benefit arXiv's global scientific community. Please join the Simons Foundation and our generous member organizations and research labs in supporting arXiv. https://goo.gl/QIgRpr
from cs.AI updates on arXiv.org http://ift.tt/29a7mvn
via IFTTT
Networked Intelligence: Towards Autonomous Cyber Physical Systems. (arXiv:1606.04087v4 [cs.AI] UPDATED)
The development of intelligent systems requires synthesis of progress made both in commerce and academia. In this report you find an overview of relevant research fields and industrially applicable technologies for building very large scale cyber physical systems. A concept architecture is used to illustrate how existing pieces may fit together, and the maturity of the subsystems is estimated.
The goal is to structure the developments and the challenge of machine intelligence for Consumer and Industrial Internet technologists, cyber physical systems researchers and people interested in the convergence of data & Internet of Things. It can be used for planning developments of intelligent systems.
DONATE to arXiv: One hundred percent of your contribution will fund improvements and new initiatives to benefit arXiv's global scientific community. Please join the Simons Foundation and our generous member organizations and research labs in supporting arXiv. https://goo.gl/QIgRpr
from cs.AI updates on arXiv.org http://ift.tt/1PZbsJd
via IFTTT
I have a new follower on Twitter
Jordi Ollier-Howard
#LGBT #GayLewisham #Gay #Chemsex #Recovering #CMA #NA Instagram: CatfordLad / KIK: JordiGOH / Facebook: JordiOH
Lewisham, London
https://t.co/GPEsUFQTkk
Following: 2043 - Followers: 529
June 30, 2016 at 06:27PM via Twitter http://twitter.com/JordiOH
Orioles need 3 HRs to tie record for most in any month (58), have gone deep on June 30 in 22 straight years - Eddie Matz (ESPN)
from ESPN http://ift.tt/1eW1vUH
via IFTTT
via IFTTT
Anonymous Buyer Snaps Up Trump-Maples Engagement Ring
New York--An anonymous buyer paid what was expected for the 7.45-carat emerald-cut Harry Winston diamond ring that once marked the union of ...
from Google Alert - anonymous http://ift.tt/296tcPH
via IFTTT
from Google Alert - anonymous http://ift.tt/296tcPH
via IFTTT
Oculus CEO's Twitter gets Hacked; Hacker declares himself new CEO
Twitter account of another high profile has been hacked! This time, it is Facebook-owned virtual reality company Oculus CEO Brendan Iribe who had his Twitter account hacked Wednesday. Iribe is the latest in the list of technology chief executives to have had their social media accounts hacked in recent weeks. Recently, Google's CEO Sundar Pichai, Twitter's ex-CEO Dick Costolo, and

from The Hacker News http://ift.tt/297XtT5
via IFTTT
from The Hacker News http://ift.tt/297XtT5
via IFTTT
Function auto post doesn't work with your Anonymous Post
Hello,. I'm using your Anonymous Post plugin for guest posting. My goal is: Every guest post automatically post on twitter. But if I use your plugin Auto ...
from Google Alert - anonymous http://ift.tt/2950KN4
via IFTTT
from Google Alert - anonymous http://ift.tt/2950KN4
via IFTTT
ISS Daily Summary Report – 06/29/16
Exposed Experiment Handrail Attachment Mechanism (ExHAM) #1-2 Operations: Following the JEMAL depressurization, venting, and leak check yesterday, today ExHAM was installed on the JEMAL Slide Table and extended to the JEM Exposed Facility (JEF) side. ExHAM is a cuboid mechanism equipped with a grapple fixture on the upper surface for the Kibo’s robotic arm, Japanese Experiment Module Remote Manipulator System Small Fine Arm (JEMRMS SFA) for fixation to the handrail on the Kibo’s EF. There are 7 loadable experiments on the upper surface and 13 on the side surfaces. Liberated particles: After ExHAM installation had already been completed but while the external cameras were still configured, loose particles were observed crossing the field of view of one of the cameras in the JEM EF area. The source of these particles is not known at this time. Ground teams are investigating. 3D Printing in Zero-G Experiment Operations: Following yesterday’s activities to print the calibration and compression coupons in the Microgravity Science Glovebox (MSG), today the ground team remotely operated the 3D printer to produce two more 3D printed test coupons, after which the crew removed and stowed them. The 3D Printing In Zero-G experiment demonstrates that a 3D printer works normally in space. A 3D printer extrudes streams of heated plastic, metal or other material, building layer on top of layer to create 3 dimensional objects. Testing a 3D printer using relatively low-temperature plastic feedstock on the ISS is the first step toward establishing an on-demand machine shop in space, a critical enabling component for deep-space crewed missions and in-space manufacturing. Synchronized Position Hold Engage and Reorient Experimental Satellites (SPHERES) Work Area Setup: In preparation for SPHERES maintenance operations tomorrow, the crew participated in a training session and crew conference with the payload developer before completing setup activities. The crew then configured the work area to activate and check out the hardware and the EXPRESS Laptop Computer ELC before testing begins. Upon inspection, it was found that two of the five beacons as well as the spare beacon had corrosion in their battery compartments. Ground teams are developing a cleaning procedure. Dose Tracker: The crew completed entries for medication tracking which documents the medication usage of crewmembers before and during their missions by capturing data regarding medication use during spaceflight, including side effect qualities, frequencies and severities. The data is expected to either support or counter anecdotal evidence of medication ineffectiveness during flight and unusual side effects experienced during flight. It is also expected that specific, near-real-time questioning about symptom relief and side effects will provide the data required to establish whether spaceflight-associated alterations in pharmacokinetics (PK) or pharmacodynamics (PD) is occurring during missions. Today’s Planned Activities All activities were completed unless otherwise noted. JEMRMS Activate and Start Bus Monitor SEISMOPROGNOZ. Downlink data from Control and Data Acquisition Module (МКСД) HDD (start) r/g 2224 JEMAL ST Extension to JEF Side DUBRAVA. Observation and Photography using VSS / r/g 2668 SPHERES – Battery Charging 3DP Printed Coupon Removal and Stowage Filling EDV (KVO) for Elektron r/g 2660nu Separation Assembly Ops r/g 2673 Environmental Control & Life Support System (ECLSS) Tank Drain Verification of ИП-1 Flow Sensor Position / SM Pressure Control & Atmosphere Monitoring System TOCA Calibration PILOT-T. Preparation for the experiment r/g 2666 Environmental Control & Life Support System (ECLSS) Recycle Tank Drain Part 2 SPHERES Battery Replacement MELF2 Stowage PILOT-T. Experiment Ops r/g 2666 JEMAL Slide Table Retraction WRS – Recycle Tank Fill from EDV 3DP Printed Coupon Removal and Stowage WRS Recycle Tank Fill from EDV DOSETRK Questionnaire Completion SPHERES Experiment OBT VELO Exercise, Day 3 SPHERES Battery Replacement SEISMOPROGNOZ. Download data from Control and Data Acquisition Module (МКСД) HDD (end) and start backup r/g 2224 SPHERES tagup with PD TOCA Calibration ARED Cylinder Flywheel Evacuation Stopping JEMRMS Arm Bus Monitoring Progress 432 [AO] Transfers and IMS Ops / r/g 1812, 1832 Replacement of СРВК-2М Gas-Liquid Mixture Filter r/g 2671 JEMRMS USB Memory Stick Virus Check JEMRMS Data Transfer SPHERES Battery Replacement USOS Window Shutter Close PILOT-T. Experiment Ops r/g 2667 PILOT-T. Closeout Ops Tagup with specialists / r/g 2667 SPHERES Battery Replacement Environmental Control & Life Support System (ECLSS) Recycle Tank Fill Part 3 SPHERES. Maintenance Run IMS Delta File Prep Video Footage of Greetings / r/g 2670 WRS Recycle Tank Fill from EDV SPHERES Battery Replacement Completed Task List Items None Ground Activities All activities were completed unless otherwise noted. JEMAL/EXHAM ops Nominal ground commanding Three-Day Look Ahead: Thursday, 06/30: SPHERES Docking Port test/maintenance run Friday, 07/01: 3D Printer Coupon prints and retrievals, ARED quarterly maintenance, T2 acoustic blanket install & SLM measurements Saturday, 07/02: Crew day off, housekeeping QUICK ISS Status – Environmental Control Group: Component Status Elektron On Vozdukh Manual [СКВ] 1 – SM Air Conditioner System (“SKV1”) Off [СКВ] 2 – SM Air Conditioner System (“SKV2”) On Carbon Dioxide Removal Assembly (CDRA) Lab Standby Carbon Dioxide Removal Assembly (CDRA) Node 3 Operate Major Constituent Analyzer (MCA) Lab Idle Major Constituent Analyzer (MCA) Node 3 Operate Oxygen Generation Assembly (OGA) Process Urine Processing Assembly (UPA) Standby Trace Contaminant Control System (TCCS) Lab Off Trace Contaminant Control System (TCCS) Node 3 Full Up
from ISS On-Orbit Status Report http://ift.tt/29dmWIN
via IFTTT
from ISS On-Orbit Status Report http://ift.tt/29dmWIN
via IFTTT
Check 'My Activity' Dashboard to know how much Google knows about you
It's no secret that Google knows a lot about you. The company tracks almost everything you do on the Internet, including your searches, music you listen to, videos you watch, and even the places you travel to, and it does this for targeting relevant ads to its users and better improve its service. Now the technology giant has a plan to make it easier to control all the data the company

from The Hacker News http://ift.tt/294ghNz
via IFTTT
from The Hacker News http://ift.tt/294ghNz
via IFTTT
From Alpha to Omega in Crete

This beautiful telephoto composition spans light-years in a natural night skyscape from the island of Crete. Looking south, exposures both track the stars and record a fixed foreground in three merged panels that cover a 10x12 degree wide field of view. The May 15 waxing gibbous moonlight illuminates the church and mountainous terrain. A mere 18 thousand light-years away, huge globular star cluster Omega Centauri (NGC 5139) shining above gives a good visual impression of its appearance in binoculars on that starry night. Active galaxy Centaurus A (NGC 5128) is near the top of the frame, some 11 million light-years distant. Also found toward the expansive southern constellation Centaurus and about the size of our own Milky Way is edge on spiral galaxy NGC 4945. About 13 million light-years distant it's only a little farther along, and just above the horizon at the right. via NASA http://ift.tt/293kSAl
Wednesday, June 29, 2016
I have a new follower on Twitter
George Shiber
Alumnus: @Columbia University and @GC_CUNY: #Philosophy #Mathematics #Logic. Probing SuperString/M-Theory. Veni Vidi Vici. Breathing #Science and #Philosophy
New York, USA
https://t.co/7uMWhZFUZS
Following: 15317 - Followers: 16149
June 29, 2016 at 11:05PM via Twitter http://twitter.com/GeorgeShiber
Anonymous Viewer
Finally allows you to view that pesky anonymous user at user/0. Depends on bad judgment.
from Google Alert - anonymous http://ift.tt/29r4h9X
via IFTTT
from Google Alert - anonymous http://ift.tt/29r4h9X
via IFTTT
Technical Report: Towards a Universal Code Formatter through Machine Learning. (arXiv:1606.08866v1 [cs.PL])
There are many declarative frameworks that allow us to implement code formatters relatively easily for any specific language, but constructing them is cumbersome. The first problem is that "everybody" wants to format their code differently, leading to either many formatter variants or a ridiculous number of configuration options. Second, the size of each implementation scales with a language's grammar size, leading to hundreds of rules.
In this paper, we solve the formatter construction problem using a novel approach, one that automatically derives formatters for any given language without intervention from a language expert. We introduce a code formatter called CodeBuff that uses machine learning to abstract formatting rules from a representative corpus, using a carefully designed feature set. Our experiments on Java, SQL, and ANTLR grammars show that CodeBuff is efficient, has excellent accuracy, and is grammar invariant for a given language. It also generalizes to a 4th language tested during manuscript preparation.
DONATE to arXiv: One hundred percent of your contribution will fund improvements and new initiatives to benefit arXiv's global scientific community. Please join the Simons Foundation and our generous member organizations and research labs in supporting arXiv. https://goo.gl/QIgRpr
from cs.AI updates on arXiv.org http://ift.tt/291ux99
via IFTTT
On the Semantic Relationship between Probabilistic Soft Logic and Markov Logic. (arXiv:1606.08896v1 [cs.AI])
Markov Logic Networks (MLN) and Probabilistic Soft Logic (PSL) are widely applied formalisms in Statistical Relational Learning, an emerging area in Artificial Intelligence that is concerned with combining logical and statistical AI. Despite their resemblance, the relationship has not been formally stated. In this paper, we describe the precise semantic relationship between them from a logical perspective. This is facilitated by first extending fuzzy logic to allow weights, which can be also viewed as a generalization of PSL, and then relate that generalization to MLN. We observe that the relationship between PSL and MLN is analogous to the known relationship between fuzzy logic and Boolean logic, and furthermore the weight scheme of PSL is essentially a generalization of the weight scheme of MLN for the many-valued setting.
DONATE to arXiv: One hundred percent of your contribution will fund improvements and new initiatives to benefit arXiv's global scientific community. Please join the Simons Foundation and our generous member organizations and research labs in supporting arXiv. https://goo.gl/QIgRpr
from cs.AI updates on arXiv.org http://ift.tt/29qYW2w
via IFTTT
Exploring high-level Perspectives on Self-Configuration Capabilities of Systems. (arXiv:1606.08906v1 [cs.AI])
Optimization of product performance repetitively introduces the need to make products adaptive in a more general sense. This more general idea is often captured under the term 'self-configuration'. Despite the importance of such capability, research work on this feature appears isolated by technical domains. It is not easy to tell quickly whether the approaches chosen in different technological domains introduce new ideas or whether the differences just reflect domain idiosyncrasies. For the sake of easy identification of key differences between systems with self-configuring capabilities, I will explore higher level concepts for understanding self-configuration, such as the {\Omega}-units, in order to provide theoretical instruments for connecting different areas of technology and research.
DONATE to arXiv: One hundred percent of your contribution will fund improvements and new initiatives to benefit arXiv's global scientific community. Please join the Simons Foundation and our generous member organizations and research labs in supporting arXiv. https://goo.gl/QIgRpr
from cs.AI updates on arXiv.org http://ift.tt/295tQ23
via IFTTT
subgraph2vec: Learning Distributed Representations of Rooted Sub-graphs from Large Graphs. (arXiv:1606.08928v1 [cs.LG])
In this paper, we present subgraph2vec, a novel approach for learning latent representations of rooted subgraphs from large graphs inspired by recent advancements in Deep Learning and Graph Kernels. These latent representations encode semantic substructure dependencies in a continuous vector space, which is easily exploited by statistical models for tasks such as graph classification, clustering, link prediction and community detection. subgraph2vec leverages on local information obtained from neighbourhoods of nodes to learn their latent representations in an unsupervised fashion. We demonstrate that subgraph vectors learnt by our approach could be used in conjunction with classifiers such as CNNs, SVMs and relational data clustering algorithms to achieve significantly superior accuracies. Also, we show that the subgraph vectors could be used for building a deep learning variant of Weisfeiler-Lehman graph kernel. Our experiments on several benchmark and large-scale real-world datasets reveal that subgraph2vec achieves significant improvements in accuracies over existing graph kernels on both supervised and unsupervised learning tasks. Specifically, on two realworld program analysis tasks, namely, code clone and malware detection, subgraph2vec outperforms state-of-the-art kernels by more than 17% and 4%, respectively.
DONATE to arXiv: One hundred percent of your contribution will fund improvements and new initiatives to benefit arXiv's global scientific community. Please join the Simons Foundation and our generous member organizations and research labs in supporting arXiv. https://goo.gl/QIgRpr
from cs.AI updates on arXiv.org http://ift.tt/2998ktw
via IFTTT
Greedy, Joint Syntactic-Semantic Parsing with Stack LSTMs. (arXiv:1606.08954v1 [cs.CL])
We present a transition-based parser that jointly produces syntactic and semantic dependencies. It learns a representation of the entire algorithm state, using stack long short-term memories. Our greedy inference algorithm has linear time, including feature extraction. On the CoNLL 2008--9 English shared tasks, we obtain the best published parsing performance among models that jointly learn syntax and semantics.
DONATE to arXiv: One hundred percent of your contribution will fund improvements and new initiatives to benefit arXiv's global scientific community. Please join the Simons Foundation and our generous member organizations and research labs in supporting arXiv. https://goo.gl/QIgRpr
from cs.AI updates on arXiv.org http://ift.tt/29qZ3Ls
via IFTTT
Evaluation and selection of Medical Tourism sites: A rough AHP based MABAC approach. (arXiv:1606.08962v1 [cs.AI])
In this paper, a novel multiple criteria decision making (MCDM) methodology is presented for assessing and prioritizing medical tourism destinations in uncertain environment. A systematic evaluation and assessment method is proposed by integrating rough number based AHP (Analytic Hierarchy Process) and rough number based MABAC (Multi-Attributive Border Approximation area Comparison). Rough number is used to aggregate individual judgments and preferences to deal with vagueness in decision making due to limited data. Rough AHP analyzes the relative importance of criteria based on their preferences given by experts. Rough MABAC evaluates the alternative sites based on the criteria weights. The proposed methodology is explained through a case study considering different cities for healthcare service in India. The validity of the obtained ranking for the given decision making problem is established by testing criteria proposed by Wang and Triantaphyllou (2008) along with further analysis and discussion.
DONATE to arXiv: One hundred percent of your contribution will fund improvements and new initiatives to benefit arXiv's global scientific community. Please join the Simons Foundation and our generous member organizations and research labs in supporting arXiv. https://goo.gl/QIgRpr
from cs.AI updates on arXiv.org http://ift.tt/295tWGF
via IFTTT
Non-linear Label Ranking for Large-scale Prediction of Long-Term User Interests. (arXiv:1606.08963v1 [cs.AI])
We consider the problem of personalization of online services from the viewpoint of ad targeting, where we seek to find the best ad categories to be shown to each user, resulting in improved user experience and increased advertisers' revenue. We propose to address this problem as a task of ranking the ad categories depending on a user's preference, and introduce a novel label ranking approach capable of efficiently learning non-linear, highly accurate models in large-scale settings. Experiments on a real-world advertising data set with more than 3.2 million users show that the proposed algorithm outperforms the existing solutions in terms of both rank loss and top-K retrieval performance, strongly suggesting the benefit of using the proposed model on large-scale ranking problems.
DONATE to arXiv: One hundred percent of your contribution will fund improvements and new initiatives to benefit arXiv's global scientific community. Please join the Simons Foundation and our generous member organizations and research labs in supporting arXiv. https://goo.gl/QIgRpr
from cs.AI updates on arXiv.org http://ift.tt/291u2Ms
via IFTTT
Credibilistic TOPSIS Model for Evaluation and Selection of Municipal Solid Waste Disposal Methods. (arXiv:1606.08965v1 [cs.AI])
Municipal solid waste management (MSWM) is a challenging issue of urban development in developing countries. Each country having different socio-economic-environmental background, might not accept a particular disposal method as the optimal choice. Selection of suitable disposal method in MSWM, under vague and imprecise information can be considered as multi criteria decision making problem (MCDM). In the present paper, TOPSIS (Technique for Order Preference by Similarity to Ideal Solution) methodology is extended based on credibility theory for evaluating the performances of MSW disposal methods under some criteria fixed by experts. The proposed model helps decision makers to choose a preferable alternative for their municipal area. A sensitivity analysis by our proposed model confirms this fact.
DONATE to arXiv: One hundred percent of your contribution will fund improvements and new initiatives to benefit arXiv's global scientific community. Please join the Simons Foundation and our generous member organizations and research labs in supporting arXiv. https://goo.gl/QIgRpr
from cs.AI updates on arXiv.org http://ift.tt/29qZ425
via IFTTT
Algebraic foundations for qualitative calculi and networks. (arXiv:1606.09140v1 [cs.AI])
A qualitative representation $\phi$ is like an ordinary representation of a relation algebra, but instead of requiring $(a; b)^\phi = a^\phi | b^\phi$, as we do for ordinary representations, we only require that $c^\phi\supseteq a^\phi | b^\phi \iff c\geq a ; b$, for each $c$ in the algebra. A constraint network is qualitatively satisfiable if its nodes can be mapped to elements of a qualitative representation, preserving the constraints. If a constraint network is satisfiable then it is clearly qualitatively satisfiable, but the converse can fail. However, for a wide range of relation algebras including the point algebra, the Allen Interval Algebra, RCC8 and many others, a network is satisfiable if and only if it is qualitatively satisfiable.
Unlike ordinary composition, the weak composition arising from qualitative representations need not be associative, so we can generalise by considering network satisfaction problems over non-associative algebras. We prove that computationally, qualitative representations have many advantages over ordinary representations: whereas many finite relation algebras have only infinite representations, every finite qualitatively representable algebra has a finite qualitative representation; the representability problem for (the atom structures of) finite non-associative algebras is NP-complete; the network satisfaction problem over a finite qualitatively representable algebra is always in NP; the validity of equations over qualitative representations is co-NP-complete. On the other hand we prove that there is no finite axiomatisation of the class of qualitatively representable algebras.
DONATE to arXiv: One hundred percent of your contribution will fund improvements and new initiatives to benefit arXiv's global scientific community. Please join the Simons Foundation and our generous member organizations and research labs in supporting arXiv. https://goo.gl/QIgRpr
from cs.AI updates on arXiv.org http://ift.tt/295tYyw
via IFTTT
Tractability and Decompositions of Global Cost Functions. (arXiv:1502.02414v2 [cs.AI] UPDATED)
Enforcing local consistencies in cost function networks is performed by applying so-called Equivalent Preserving Transformations (EPTs) to the cost functions. As EPTs transform the cost functions, they may break the property that was making local consistency enforcement tractable on a global cost function. A global cost function is called tractable projection-safe when applying an EPT to it is tractable and does not break the tractability property. In this paper, we prove that depending on the size r of the smallest scopes used for performing EPTs, the tractability of global cost functions can be preserved (r = 0) or destroyed (r > 1). When r = 1, the answer is indefinite. We show that on a large family of cost functions, EPTs can be computed via dynamic programming-based algorithms, leading to tractable projection-safety. We also show that when a global cost function can be decomposed into a Berge acyclic network of bounded arity cost functions, soft local consistencies such as soft Directed or Virtual Arc Consistency can directly emulate dynamic programming. These different approaches to decomposable cost functions are then embedded in a solver for extensive experiments that confirm the feasibility and efficiency of our proposal.
DONATE to arXiv: One hundred percent of your contribution will fund improvements and new initiatives to benefit arXiv's global scientific community. Please join the Simons Foundation and our generous member organizations and research labs in supporting arXiv. https://goo.gl/QIgRpr
from cs.AI updates on arXiv.org http://ift.tt/1CNwGly
via IFTTT
A Single-Pass Classifier for Categorical Data. (arXiv:1503.02521v4 [cs.AI] UPDATED)
This paper describes a new method for classifying a dataset that partitions elements into their categories. It has relations with neural networks but a slightly different structure, requiring only a single pass through the classifier to generate the weight sets. A grid-like structure is required as part of a novel idea of converting a 1-D row of real values into a 2-D structure of value bands. Each cell in any band then stores a distinct set of weights, to represent its own importance and its relation to each output category. During classification, all of the output weight lists can be retrieved and summed to produce a probability for what the correct output category is. The bands possibly work like hidden layers of neurons, but they are variable specific, making the process orthogonal. The construction process can be a single update process without iterations, making it potentially much faster. It can also be compared with k-NN and may be practical for partial or competitive updating.
DONATE to arXiv: One hundred percent of your contribution will fund improvements and new initiatives to benefit arXiv's global scientific community. Please join the Simons Foundation and our generous member organizations and research labs in supporting arXiv. https://goo.gl/QIgRpr
from cs.AI updates on arXiv.org http://ift.tt/1ENtzts
via IFTTT
Mapping Heritability of Large-Scale Brain Networks with a Billion Connections {\em via} Persistent Homology. (arXiv:1509.04771v2 [cs.AI] UPDATED)
In many human brain network studies, we do not have sufficient number (n) of images relative to the number (p) of voxels due to the prohibitively expensive cost of scanning enough subjects. Thus, brain network models usually suffer the small-n large-p problem. Such a problem is often remedied by sparse network models, which are usually solved numerically by optimizing L1-penalties. Unfortunately, due to the computational bottleneck associated with optimizing L1-penalties, it is not practical to apply such methods to construct large-scale brain networks at the voxel-level. In this paper, we propose a new scalable sparse network model using cross-correlations that bypass the computational bottleneck. Our model can build sparse brain networks at the voxel level with p > 25000. Instead of using a single sparse parameter that may not be optimal in other studies and datasets, the computational speed gain enables us to analyze the collection of networks at every possible sparse parameter in a coherent mathematical framework via persistent homology. The method is subsequently applied in determining the extent of heritability on a functional brain network at the voxel-level for the first time using twin fMRI.
DONATE to arXiv: One hundred percent of your contribution will fund improvements and new initiatives to benefit arXiv's global scientific community. Please join the Simons Foundation and our generous member organizations and research labs in supporting arXiv. https://goo.gl/QIgRpr
from cs.AI updates on arXiv.org http://ift.tt/1Fhseht
via IFTTT
Consciousness is Pattern Recognition. (arXiv:1605.03009v2 [cs.AI] UPDATED)
This is a proof of the strong AI hypothesis, i.e. that machines can be conscious. It is a phenomenological proof that pattern-recognition and subjective consciousness are the same activity in different terms. Therefore, it proves that essential subjective processes of consciousness are computable, and identifies significant traits and requirements of a conscious system. Since Husserl, many philosophers have accepted that consciousness consists of memories of logical connections between an ego and external objects. These connections are called "intentions." Pattern recognition systems are achievable technical artifacts. The proof links this respected introspective philosophical theory of consciousness with technical art. The proof therefore endorses the strong AI hypothesis and may therefore also enable a theoretically-grounded form of artificial intelligence called a "synthetic intentionality," able to synthesize, generalize, select and repeat intentions. If the pattern recognition is reflexive, able to operate on the set of intentions, and flexible, with several methods of synthesizing intentions, an SI may be a particularly strong form of AI. Similarities and possible applications to several AI paradigms are discussed. The article then addresses some problems: The proof's limitations, reflexive cognition, Searles' Chinese room, and how an SI could "understand" "meanings" and "be creative."
DONATE to arXiv: One hundred percent of your contribution will fund improvements and new initiatives to benefit arXiv's global scientific community. Please join the Simons Foundation and our generous member organizations and research labs in supporting arXiv. https://goo.gl/QIgRpr
from cs.AI updates on arXiv.org http://ift.tt/24M4BJZ
via IFTTT
Orioles Video: Mark Trumbo crushes 2-run shot into second deck in 12-6 win over Padres; MLB-best 23rd HR of season (ESPN)
from ESPN http://ift.tt/1eW1vUH
via IFTTT
via IFTTT
MLB: Mark Trumbo's 4th-inning HR was Orioles' 55th in June, tying mark set by 1996 A's; most HR for any month is 58 (ESPN)
from ESPN http://ift.tt/1eW1vUH
via IFTTT
via IFTTT
"Pretty Little Liars" recap (7.20): So long, anonymous white guys!
Episode 7.2 begins right where last week left off, with Hanna getting a ride home from Mary Drake. Mary offers to take Hanna to the police or the ...
from Google Alert - anonymous http://ift.tt/296bDA2
via IFTTT
from Google Alert - anonymous http://ift.tt/296bDA2
via IFTTT
docker/docker
The Docker Trusted Registry product states that it will allow anonymous access until auth is enabled. However it also states you cannot even create a ...
from Google Alert - anonymous http://ift.tt/295qP4m
via IFTTT
from Google Alert - anonymous http://ift.tt/295qP4m
via IFTTT
Global Terrorism Database Leaked! Reveals 2.2 Million Suspected Terrorists
A massive database of terrorists and "heightened-risk individuals and entities" containing more than 2.2 Million records has reportedly leaked online. Researcher Chris Vickery claimed on Reddit that he had managed to obtain a copy of 2014 version of the World-Check confidential database, which is being used by banks, governments, and intelligence agencies worldwide to scope out risks

from The Hacker News http://ift.tt/299m8pE
via IFTTT
from The Hacker News http://ift.tt/299m8pE
via IFTTT
ISS Daily Summary Report – 06/28/16
3D Printing in Zero-G Experiment Setup: Today, the crew set up the 3D Printer in the Microgravity Science Glovebox (MSG) work volume. The payload ground team remotely operated the device to produce two 3D printed test coupons, and the crew removed and stowed each of them. The 3D Printing In Zero-G experiment demonstrates that a 3D printer works normally in space. In general, a 3D printer extrudes streams of heated plastic, metal or other material, building layer on top of layer to create 3 dimensional objects. Testing a 3D printer using relatively low-temperature plastic feedstock on the ISS is the first step toward establishing an on-demand machine shop in space, a critical enabling component for deep-space crewed missions and in-space manufacturing. Japanese Experiment Module (JEM) Airlock (JEM A/L) Operations: In preparation for tomorrow’s EXHAM installation on the JEM Exposed Facility (JEF) the JEM A/L was depressurized and the crew performed a leak check and vented residual air. When venting was complete, the vent valve and JEM A/L backup manual valve were closed. Habitability Human Factors Directed Observations: The crew completed a session of the Habitability experiment by recording and submitting a walk-through video documenting observations of an area or activity providing insight related to human factors and habitability. The Habitability investigation collects observations about the relationship between crew members and their environment on the ISS. Observations can help spacecraft designers understand how much habitable volume is required, and whether a mission’s duration impacts how much space crew members need. Health Maintenance System (HMS) Crew Medical Officer (CMO) Training: The crew completed this refresher course on some of the equipment and procedures taught in the CMO classes covering crew illness and/or injury. Lessons include text, pictures and video detailing previously learned medical procedures and hardware. Today’s Planned Activities All activities were completed unless otherwise noted. Verification of anti-virus scan results on Auxiliary Computer System [ВКС] laptops / r/g 8247 Microgravity Science Glovebox (MSG) Activation of MSG glove box On MCC GO Regeneration of БМП Ф2 Micropurification Cartridge (start) JEM A/L Depress and Vent TM750 Camcorder Battery Operation Checkout VIZIR. Measuring SM panels 114, 116 / r/g 2655 Activation of Progress 431 (DC1), Air Duct Removal / IRS Activation/Deactivation ARED exercise video setup 3D Printing in Zero-G Payload Overview On MCC GO Removal of ССВП Quick-Disconnect screw clamps from DC1 side and video of DC1- Progress 431 interface 3D Printing in Zero-G Hardware Gather DC1-Progress 431 Hatch Closure / IRS Activation/Deactivation Cleaning FGB Gas-Liquid Heat Exchanger (ГЖТ) Detachable Screens 1, 2, 3 On MCC GO DC1-СУ and СУ- Progress 431 Hatch Leak Check / IRS Activation/Deactivation 3DP Hardware Setup Scheduled monthly maintenance of Central Post Laptop. Laptop Log-File Downlink r/g 1888 OTKLIK. Hardware Monitoring / r/g 1588 Vacuum Cleaning of ВД1 and ВД2 air ducts in DC1 Photo/TV Camcorder Setup Verification URAGAN. Observation and Photography using VSS / r/g 2658 JEMAL Verifying depressurization complete JEM Airlock Depressurization and Vent Confirmation ALGOMETRIA. Experiment Ops / r/g 2386 Soyuz 720 Samsung Tablet Recharge – initiate ALGOMETRIA. Experiment Ops / r/g 2385 Filling EDV (KVO) for Elektron r/g 2660 3DP Printed Coupon Removal and Stowage Crew Onboard Training (OBT) Self-Assessment Questionnaire TEPC Transfer СОЖ Maintenance WRS Water Sample Analysis Crew Onboard Training (OBT) Self-Assessment Questionnaire Photo/TV Camcorder Setup Verification HABIT Preparing for the experiment 3DP Printed Coupon Removal and Stowage Soyuz 720 Samsung tablet charge, end IMS Delta File Prep Photo/TV Camcorder Setup Verification CONTENT. Experiment Ops / r/g 2656 FGB ЦВ1 Fan Grille Cleaning / Ventilation and Air Conditioning System ARED Exercise Video Equipment Stowage Evening Work Prep CONTENT. Experiment Ops / r/g 2657 TOCA Data Recording On MCC GO БМП Ф2 Absorption Cartridge Regeneration (end) Completed Task List Items None Ground Activities All activities were completed unless otherwise noted. JEM A/L depress Nominal ground commanding Three-Day Look Ahead: Wednesday, 06/29: CBEF Incubator Unit cleaning, Mouse habitat IU installation, MSPR VRU SSD replacement Thursday, 06/30: SPHERES Docking Port test/maintenance run Friday, 07/01: 3D Printer Coupon prints and retrievals, ARED quarterly maintenance, T2 acoustic blanket install & SLM measurements QUICK ISS Status – Environmental Control Group: Component Status Elektron On Vozdukh Manual [СКВ] 1 – SM Air Conditioner System (“SKV1”) Off [СКВ] 2 – SM Air Conditioner System (“SKV2”) On Carbon Dioxide Removal Assembly (CDRA) Lab Standby Carbon Dioxide Removal Assembly (CDRA) Node 3 Operate Major Constituent Analyzer (MCA) Lab Idle Major Constituent Analyzer (MCA) Node 3 Operate Oxygen Generation Assembly (OGA) Process Urine Processing Assembly (UPA) Standby Trace Contaminant Control System (TCCS) Lab Off Trace Contaminant Control System (TCCS) Node 3 Full Up
from ISS On-Orbit Status Report http://ift.tt/29amc78
via IFTTT
from ISS On-Orbit Status Report http://ift.tt/29amc78
via IFTTT
China Orders Apple to Monitor App Store Users and Track their Identities
China has long been known for its strict censorship which makes it difficult for foreign technology companies to do business in the world’s most populous country of over 1.35 billion people. Now, the new law issued by the Chinese government will expand its strict Internet monitoring efforts into mobile apps, targeting operators including Apple. However, Google currently doesn’t operate its

from The Hacker News http://ift.tt/293aNmP
via IFTTT
from The Hacker News http://ift.tt/293aNmP
via IFTTT
STOP Sharing that Facebook Privacy and Permission Notice, It's a HOAX
Recently, you may have seen some of your Facebook friends started posting a Facebook "Privacy Notice" clarifying that they no longer give Facebook permission to use their photos, personal information, and so on. The Privacy message looks something like this: <!-- adsense --> "From Monday, 27th June, 2016, 1528 IST, I don't give Facebook permission to use my pictures, my information or my

from The Hacker News http://ift.tt/291WtKn
via IFTTT
from The Hacker News http://ift.tt/291WtKn
via IFTTT
Orioles Video: Chris Davis parks the ball over the center-field wall in the 6th inning of 11-7 win over the Padres (ESPN)
from ESPN http://ift.tt/1eW1vUH
via IFTTT
via IFTTT
Tuesday, June 28, 2016
Towards Verified Artificial Intelligence. (arXiv:1606.08514v1 [cs.AI])
Verified artificial intelligence (AI) is the goal of designing AI-based systems that are provably correct with respect to mathematically-specified requirements. This paper considers Verified AI from a formal methods perspective. We describe five challenges for achieving Verified AI, and five corresponding principles for addressing these challenges.
DONATE to arXiv: One hundred percent of your contribution will fund improvements and new initiatives to benefit arXiv's global scientific community. Please join the Simons Foundation and our generous member organizations and research labs in supporting arXiv. https://goo.gl/QIgRpr
from cs.AI updates on arXiv.org http://ift.tt/293kiU2
via IFTTT
A Learning Algorithm for Relational Logistic Regression: Preliminary Results. (arXiv:1606.08531v1 [cs.AI])
Relational logistic regression (RLR) is a representation of conditional probability in terms of weighted formulae for modelling multi-relational data. In this paper, we develop a learning algorithm for RLR models. Learning an RLR model from data consists of two steps: 1- learning the set of formulae to be used in the model (a.k.a. structure learning) and learning the weight of each formula (a.k.a. parameter learning). For structure learning, we deploy Schmidt and Murphy's hierarchical assumption: first we learn a model with simple formulae, then more complex formulae are added iteratively only if all their sub-formulae have proven effective in previous learned models. For parameter learning, we convert the problem into a non-relational learning problem and use an off-the-shelf logistic regression learning algorithm from Weka, an open-source machine learning tool, to learn the weights. We also indicate how hidden features about the individuals can be incorporated into RLR to boost the learning performance. We compare our learning algorithm to other structure and parameter learning algorithms in the literature, and compare the performance of RLR models to standard logistic regression and RDN-Boost on a modified version of the MovieLens data-set.
DONATE to arXiv: One hundred percent of your contribution will fund improvements and new initiatives to benefit arXiv's global scientific community. Please join the Simons Foundation and our generous member organizations and research labs in supporting arXiv. https://goo.gl/QIgRpr
from cs.AI updates on arXiv.org http://ift.tt/294qSfs
via IFTTT
A Local Density-Based Approach for Local Outlier Detection. (arXiv:1606.08538v1 [cs.AI])
This paper presents a simple but effective density-based outlier detection approach with the local kernel density estimation (KDE). A Relative Density-based Outlier Score (RDOS) is introduced to measure the local outlierness of objects, in which the density distribution at the location of an object is estimated with a local KDE method based on extended nearest neighbors of the object. Instead of using only $k$ nearest neighbors, we further consider reverse nearest neighbors and shared nearest neighbors of an object for density distribution estimation. Some theoretical properties of the proposed RDOS including its expected value and false alarm probability are derived. A comprehensive experimental study on both synthetic and real-life data sets demonstrates that our approach is more effective than state-of-the-art outlier detection methods.
DONATE to arXiv: One hundred percent of your contribution will fund improvements and new initiatives to benefit arXiv's global scientific community. Please join the Simons Foundation and our generous member organizations and research labs in supporting arXiv. https://goo.gl/QIgRpr
from cs.AI updates on arXiv.org http://ift.tt/293kouE
via IFTTT
"Show me the cup": Reference with Continuous Representations. (arXiv:1606.08777v1 [cs.CL])
One of the most basic functions of language is to refer to objects in a shared scene. Modeling reference with continuous representations is challenging because it requires individuation, i.e., tracking and distinguishing an arbitrary number of referents. We introduce a neural network model that, given a definite description and a set of objects represented by natural images, points to the intended object if the expression has a unique referent, or indicates a failure, if it does not. The model, directly trained on reference acts, is competitive with a pipeline manually engineered to perform the same task, both when referents are purely visual, and when they are characterized by a combination of visual and linguistic properties.
DONATE to arXiv: One hundred percent of your contribution will fund improvements and new initiatives to benefit arXiv's global scientific community. Please join the Simons Foundation and our generous member organizations and research labs in supporting arXiv. https://goo.gl/QIgRpr
from cs.AI updates on arXiv.org http://ift.tt/297sbuK
via IFTTT
Adaptive Training of Random Mapping for Data Quantization. (arXiv:1606.08808v1 [cs.LG])
Data quantization learns encoding results of data with certain requirements, and provides a broad perspective of many real-world applications to data handling. Nevertheless, the results of encoder is usually limited to multivariate inputs with the random mapping, and side information of binary codes are hardly to mostly depict the original data patterns as possible. In the literature, cosine based random quantization has attracted much attentions due to its intrinsic bounded results. Nevertheless, it usually suffers from the uncertain outputs, and information of original data fails to be fully preserved in the reduced codes. In this work, a novel binary embedding method, termed adaptive training quantization (ATQ), is proposed to learn the ideal transform of random encoder, where the limitation of cosine random mapping is tackled. As an adaptive learning idea, the reduced mapping is adaptively calculated with idea of data group, while the bias of random transform is to be improved to hold most matching information. Experimental results show that the proposed method is able to obtain outstanding performance compared with other random quantization methods.
DONATE to arXiv: One hundred percent of your contribution will fund improvements and new initiatives to benefit arXiv's global scientific community. Please join the Simons Foundation and our generous member organizations and research labs in supporting arXiv. https://goo.gl/QIgRpr
from cs.AI updates on arXiv.org http://ift.tt/29mz1sQ
via IFTTT
Active Ranking from Pairwise Comparisons and the Futility of Parametric Assumptions. (arXiv:1606.08842v1 [cs.LG])
We consider sequential or active ranking of a set of n items based on noisy pairwise comparisons. Items are ranked according to the probability that a given item beats a randomly chosen item, and ranking refers to partitioning the items into sets of pre-specified sizes according to their scores. This notion of ranking includes as special cases the identification of the top-k items and the total ordering of the items. We first analyze a sequential ranking algorithm that counts the number of comparisons won, and uses these counts to decide whether to stop, or to compare another pair of items, chosen based on confidence intervals specified by the data collected up to that point. We prove that this algorithm succeeds in recovering the ranking using a number of comparisons that is optimal up to logarithmic factors. This guarantee does not require any structural properties of the underlying pairwise probability matrix, unlike a significant body of past work on pairwise ranking based on parametric models such as the Thurstone or Bradley-Terry-Luce models. It has been a long-standing open question as to whether or not imposing these parametric assumptions allow for improved ranking algorithms. Our second contribution settles this issue in the context of the problem of active ranking from pairwise comparisons: by means of tight lower bounds, we prove that perhaps surprisingly, these popular parametric modeling choices offer little statistical advantage.
DONATE to arXiv: One hundred percent of your contribution will fund improvements and new initiatives to benefit arXiv's global scientific community. Please join the Simons Foundation and our generous member organizations and research labs in supporting arXiv. https://goo.gl/QIgRpr
from cs.AI updates on arXiv.org http://ift.tt/29aiJau
via IFTTT
Deep Reinforcement Learning from Self-Play in Imperfect-Information Games. (arXiv:1603.01121v2 [cs.LG] UPDATED)
Many real-world applications can be described as large-scale games of imperfect information. To deal with these challenging domains, prior work has focused on computing Nash equilibria in a handcrafted abstraction of the domain. In this paper we introduce the first scalable end-to-end approach to learning approximate Nash equilibria without prior domain knowledge. Our method combines fictitious self-play with deep reinforcement learning. When applied to Leduc poker, Neural Fictitious Self-Play (NFSP) approached a Nash equilibrium, whereas common reinforcement learning methods diverged. In Limit Texas Holdem, a poker game of real-world scale, NFSP learnt a strategy that approached the performance of state-of-the-art, superhuman algorithms based on significant domain expertise.
DONATE to arXiv: One hundred percent of your contribution will fund improvements and new initiatives to benefit arXiv's global scientific community. Please join the Simons Foundation and our generous member organizations and research labs in supporting arXiv. https://goo.gl/QIgRpr
from cs.AI updates on arXiv.org http://ift.tt/1QWDK7A
via IFTTT
Landmark-based Plan Recognition. (arXiv:1604.01277v2 [cs.AI] UPDATED)
Recognition of goals and plans using incomplete evidence from action execution can be done efficiently by using planning techniques. In many applications it is important to recognize goals and plans not only accurately, but also quickly. In this paper, we develop a heuristic approach for recognizing plans based on planning techniques that rely on ordering constraints to filter candidate goals from observations. These ordering constraints are called landmarks in the planning literature, which are facts or actions that cannot be avoided to achieve a goal. We show the applicability of planning landmarks in two settings: first, we use it directly to develop a heuristic-based plan recognition approach; second, we refine an existing planning-based plan recognition approach by pre-filtering its candidate goals. Our empirical evaluation shows that our approach is not only substantially more accurate than the state-of-the-art in all available datasets, it is also an order of magnitude faster.
DONATE to arXiv: One hundred percent of your contribution will fund improvements and new initiatives to benefit arXiv's global scientific community. Please join the Simons Foundation and our generous member organizations and research labs in supporting arXiv. https://goo.gl/QIgRpr
from cs.AI updates on arXiv.org http://ift.tt/1SOnFhC
via IFTTT
Teaching natural language to computers. (arXiv:1604.08781v2 [cs.CL] UPDATED)
"Natural Language," whether spoken and attended to by humans, or processed and generated by computers, requires networked structures that reflect creative processes in semantic, syntactic, phonetic, linguistic, social, emotional, and cultural modules. Being able to produce novel and useful behavior following repeated practice gets to the root of both artificial intelligence and human language. This paper investigates the modalities involved in language-like applications that computers -- and programmers -- engage with, and aims to fine tune the questions we ask to better account for context, self-awareness, and embodiment.
DONATE to arXiv: One hundred percent of your contribution will fund improvements and new initiatives to benefit arXiv's global scientific community. Please join the Simons Foundation and our generous member organizations and research labs in supporting arXiv. https://goo.gl/QIgRpr
from cs.AI updates on arXiv.org http://ift.tt/1O8ysPZ
via IFTTT
The Transport Consortium starts testing the Public Transport Card with anonymous passes
The Madrid Transport Consortium has started tests on the Public Transport Card with anonymous passes, which will permit users of 10-journey tickets ...
from Google Alert - anonymous http://ift.tt/291bBfD
via IFTTT
from Google Alert - anonymous http://ift.tt/291bBfD
via IFTTT
Orioles: P T.J. McFarland recalled from Triple-A Tuesday; appeared in 23 innings over 14 games with Baltimore in 2016 (ESPN)
from ESPN http://ift.tt/1eW1vUH
via IFTTT
via IFTTT
IoT Botnet — 25,000 CCTV Cameras Hacked to launch DDoS Attack
The Internet of Things (IoTs) or Internet-connected devices are growing at an exponential rate and so are threats to them. Due to the insecure implementation, these Internet-connected embedded devices, including Smart TVs, Refrigerators, Microwaves, Set-top boxes, Security Cameras and printers, are routinely being hacked and used as weapons in cyber attacks. We have seen how hackers

from The Hacker News http://ift.tt/290Y1ZG
via IFTTT
from The Hacker News http://ift.tt/290Y1ZG
via IFTTT
[FD] KL-001-2016-002 : Ubiquiti Administration Portal CSRF to Remote Command Execution
KL-001-2016-002 : Ubiquiti Administration Portal CSRF to Remote Command Execution Title: Ubiquiti Administration Portal CSRF to Remote Command Execution Advisory ID: KL-001-2016-002 Publication Date: 2016.06.28 Publication URL: http://ift.tt/29lwYW0 1. Vulnerability Details Affected Vendor: Ubiquiti Affected Product: AirGateway, AirFiber, mFi Affected Version: 1.1.6, 3.2, 2.1.11 Platform: Embedded Linux CWE Classification: CWE-352: Cross-Site Request Forgery (CSRF); CWE-77: Improper Neutralization of Special Elements used in a Command ('Command Injection') Impact: Arbitrary Code Execution Attack vector: HTTP 2. Vulnerability Description The Ubiquiti AirGateway, AirFiber and mFi platforms feature remote administration via an authenticated web-based portal. Lack of CSRF protection in the Remote Administration Portal, and unsafe passing of user input to operating system commands exectuted with root privileges, can be abused in a way that enables remote command execution. 3. Technical Description The firmware files analyzed were AirGWP.v1.1.6.28062.150731.1520.bin, AF24.v3.2.bin, and firmware.bin respectively. The MD5 hash values for the vulnerable files served by the administration portal are: AirGateway b45fe8e491d62251f0a7a100c636178a /usr/www/system.cgi AirFiber d8926f7f65a2111f4036413f985082b9 /usr/www/system.cgi mFi 960e8f6e507b227dbc4b65fc7a7036bc /usr/www/system.cgi The firmware file contains a LZMA compressed, squashfs partition. The binaries running on the embedded device are compiled for a MIPS CPU. The device can be easily virtualized using QEMU: Example: sudo /usr/sbin/chroot . ./qemu-mips-static /usr/sbin/lighttpd -f /etc/lighttpd/lighttpd.conf The administration portal does not issue a randomized CSRF token either per session, page, or request. Administration authorization is solely based on cookie control. Therefore, it is possible to embed JavaScript into an HTML page so when an administrator is socially engineered into visiting the page, the target device will be accessed with privileges. Device configuration POST parameters include tokens passed to operating system commands run as root in unsafe ways with insufficient input sanitization. Command injection is possible by stacking shell commands in parameters such as iptables.1.cmd. In order for a developer to recreate this discovery, the following instructions should be duplicated. a. Authenticate to the target web application and navigate to the SYSTEM page. b. Download the current configuration. c. Open the configuration in an editor of your choice, navigate to the line containing: iptables.1.cmd=-A FIREWALL -j ACCEPT d. Append the following onto that line: ;touch /var/tmp/csrf-to-rce.txt e. Save the changes, and submit the modified configuration. Apply the changes using apply.cgi afterward. Example: POST /system.cgi HTTP/1.1 Host: 192.168.1.1 User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.10; rv:43.0) Gecko/20100101 Firefox/43.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*; q=0.8 Accept-Language: en-US,en;q=0.5 Accept-Encoding: gzip, deflate DNT: 1 Referer: http://ift.tt/291MlnH Cookie: ui_language=en_US; last_check=1452020493426; AIROS_SESSIONID=e5f61a5c0a9d0690b4efd484e56b8c93 Connection: keep-alive Content-Type: multipart/form-data; boundary
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
One Less Gun
At about 7:00 PM on Sunday June 26, 2016, officers assigned to District B-3 (Mattapan) received an anonymous tip from a concerned citizen which led ...
from Google Alert - anonymous http://ift.tt/291u3kK
via IFTTT
from Google Alert - anonymous http://ift.tt/291u3kK
via IFTTT
[FD] [KIS-2016-10] Concrete5 <= 5.7.3.1 (Application::dispatch) Local File Inclusion Vulnerability
---------------------------------------------------------------------------
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
[FD] [KIS-2016-08] Concrete5 <= 5.7.3.1 Multiple Cross-Site Request Forgeries Vulnerabilities
----------------------------------------------------------------------
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
Zero-Day Warning! Ransomware targets Microsoft Office 365 Users
If just relying on the security tools of Microsoft Office 365 can protect you from cyber attacks, you are wrong. Variants of Cerber Ransomware are now targeting MS Office 365 email users with a massive zero-day attack that has the ability to bypass Office 365's built-in security tools. According to a report published by cloud security provider Avanan, the massive zero-day Cerber ransomware

from The Hacker News http://ift.tt/29173D1
via IFTTT
from The Hacker News http://ift.tt/29173D1
via IFTTT
ISS Daily Summary Report – 06/27/16
Ultrasonic Background Noise Test (UBNT): The crew replaced batteries and transmitted data by closing out the Station Support Computer (SSC’s) Distributed Impact Detection System (DIDS) software and removing the UBNT hardware. UBNT detects high-frequency sounds generated by hardware on the U.S.-built portions of the ISS. Identifying sources of noise will aid in development of a leak locating system which would detect the high-pitched sound of air leaking through a pressurized wall. To detect leaks, the system would have to differentiate between harmless background sounds and a potentially dangerous air leak. LAB Major Constituent Analyzer (MCA) Mass Spectrometer Assembly (MSA) Troubleshooting: In December 2014, the crew installed new Orbital Replacement Units ORU1, ORU2, and ORU8 in the Lab MCA. When the Lab MCA was restarted, there was no communication with ORU2. Today the crew attempted to isolate the problem to either ORU2 or the connector it mates with on the MCA drawer. The crew reported no visible damage to either side of the ORU2 connector interface. He performed resistance checks on sockets on the drawer side connector saver and found that four of the sockets tested had lower than expected resistances. To address one potential cause of this problem, the crew replaced ORU4, the Low Voltage Power Supply, and repeated the resistance check on the previously failed sockets. The resistances of the sockets did not change so the original ORU4 was reinstalled. The rack has been closed out with ORU2 and ORU8 uninstalled. Teams are meeting to discuss the forward plan. The Node 3 MCA is operating nominally. Remote Power Controller RPCM LA2A3B-G RPC 2 Trip: This morning the RPC that provides power to the Fluids Integrated Rack (FIR) Primary Power feed tripped. At the time of the trip, ground teams were activating FIR for science operations. The crew reported no smoke odor and Compound Specific Analyzer Combustion Products (CSA-CP) readings were zero. A current spike high enough to trigger an RPC trip was not visible in the 50 Hz Direct Current to Direct Current Converter Unit (DDCU) current data, however, it is possible that the current spike was rapid enough to not be sampled at 50 Hz. After analysis of the system showed that the suspect components would be isolated if the main power feed was not used, the rack was successfully repowered using the auxiliary power feed. The auxiliary power feed will allow the MicroChannel Diffusion to achieve their science goals, and troubleshooting on the main power feed will occur after that payload’s objectives are complete. Today’s Planned Activities All activities were completed unless otherwise noted. МО-8. Configuration Setup МО-8. Body Mass Measurement r/g 2639 МО-8. Closeout Ops USOS window shutter close Window cover close #6,8,9,12,13,14 r/g 6965 On MCC GO Regeneration of БМП Ф1 Micropurification Cartridge (start) TM750 video camera battery charge Sprint Exercise, Optional TORU OBT r/g 2638, 2642 + 2642 UBNT. Locate Ultrasonic Background Noise Test Battery (UBNT) IFM Major Constituent Analyzer (MCA) Troubleshooting UBNT. AA batteries swap IFM Major Constituent Analyzer (MCA) Troubleshooting WRS Maintenance Auxiliary Laptop Anti-Virus Update / r/g 8247 VIZIR. Experiment Ops with СКПФУ Hardware r/g 2643 Transfer of Т61 HDD from USOS / r/g 2641 Preventive maintenance of DC1 АСП hatch sealing mechanisms and Progress 431 [АСА] hatch VIZIR. Experiment Photography / r/g 2644 Progress 431 (DC1) Stowage and IMS Ops / r/g 2584 СОЖ Maintenance IMS Delta File Prep WRS Maintenance Exercise Data Downlink via OCA Progress 431 (DC1) Stowage Completion Report r/g 2234, 2315, 2435, 2512, 2584 UBNT. Hardware Stowage On MCC GO БМП Ф1 Absorption Cartridge Regeneration (end) Preparing for Antivirus scan on Auxiliary Computer Laptops / r/g 8247 Completed Task List Items PL CTB move Polar4 locker prep SSC11, SSC13 battery swap USOS stowage consolidate PiP PS120 secure Ground Activities All activities were completed unless otherwise noted. Nominal ground commanding Three-Day Look Ahead: Tuesday, 06/28: TM750 camcorder battery charge & recording, 3D Printing hardware gather/experiment setup/coupon retrievals Wednesday, 06/29: CBEF Incubator Unit cleaning, Mouse habitat IU installation, MSPR VRU SSD replacement Thursday, 06/30: SPHERES Docking Port test/maintenance run QUICK ISS Status – Environmental Control Group: Component Status Elektron On Vozdukh Manual [СКВ] 1 – SM Air Conditioner System (“SKV1”) On [СКВ] 2 – SM Air Conditioner System (“SKV2”) Off Carbon Dioxide Removal Assembly (CDRA) Lab Standby Carbon Dioxide Removal Assembly (CDRA) Node 3 Operate Major Constituent Analyzer (MCA) Lab Idle Major Constituent Analyzer (MCA) Node 3 Operate Oxygen Generation Assembly (OGA) Process Urine Processing Assembly (UPA) Standby Trace Contaminant Control System (TCCS) Lab Off Trace Contaminant Control System (TCCS) Node 3 Full Up
from ISS On-Orbit Status Report http://ift.tt/28XGlsV
via IFTTT
from ISS On-Orbit Status Report http://ift.tt/28XGlsV
via IFTTT
[FD] Iranian Weblog Services v3.3 CMS - Multiple Web Vulnerabilities
Document Title: =============== Iranian Weblog Services v3.3 CMS - Multiple Web Vulnerabilities References (Source): ==================== http://ift.tt/290yJJH CWE-89 CWE-79 CWE-264 http://ift.tt/297sXqz http://ift.tt/2908NLl http://ift.tt/297toB1 CWE-ID: ====== 89 Release Date: ============= 2016-06-28 Vulnerability Laboratory ID (VL-ID): ==================================== 1862 Common Vulnerability Scoring System: ==================================== 7.4 Abstract Advisory Information: ============================== An independent vulnerability laboratory researcher discovered multiple web vulnerabilities in the Iranian Web Blog Service v3.3 content management system. Vulnerability Disclosure Timeline: ================================== 2016-06-28: Public Disclosure (Vulnerability Laboratory) Discovery Status: ================= Published Affected Product(s): ==================== Iranian Weblog Services Product: Content Management System 3.3 Exploitation Technique: ======================= Remote Severity Level: =============== High Technical Details & Description: ================================ 1.1 A remote sql injection web vulnerability has been discovered in the Iranian Web Blog Service v3.3 content management system. The vulnerability allows remote attackers to execute own sql commands to compromise the web-applicaation or connected dbms. The vulnerability is located in the `i` parameter of the `list.php` file GET method request. Remote attackers are able to execute sql commands by injection of malicious statements via GET method request. The vulnerability is located on the application-side and the request method to inject/execute is GET. The security vulnerability is a classic order by sql injection in the `i` value. The security risk of the sql injection vulnerability is estimated as high with a cvss (common vulnerability scoring system) count of 7.4. Exploitation of the remote sql injection web vulnerability requires no user interaction or privileged web-application user account. Successful exploitation of the remote sql injection results in database management system, web-server and web-application compromise. Request Method(s): [+] GET Vulnerable File(s): [+] list.php Vulnerable Parameter(s): [+] i 1.2 A client-side cross site scripting web vulnerability has been discovered in the Iranian Web Blog Service v3.3 content management system. The web vulnerability allows remote attackers to inject own malicious script codes to the client-side of the online service module or function. The cross site scripting web vulnerability is located in the `page` parameter of the `list.php` file GET method request. Remote attackers are able to inject own malicious script codes to the page parameter to compromise client-side requests. The attack vector of the vulnerability is non-persistent and the request method to inject/execute is GET. The security risk of the cross site web vulnerability is estimated as medium with a cvss (common vulnerability scoring system) count of 3.3. Exploitation of the web vulnerability requires no privileged web-application account with restricted access and only low user interaction. Successful exploitation of the vulnerabilities results in persistent phishing, session hijacking, persistent external redirect to malicious sources and application-side manipulation of affected or connected module context. Request Method(s): [+] GET Vulnerable Module(s): [+] list.php Vulnerable Parameter(s): [+] page 1.3 An arbitrary file upload web vulnerability has been discovered in the Iranian Web Blog Service v3.3 content management system. The vulnerability allows to upload malicious files to unrestricted path variables to compromise the web-server or database. The web vulnerability is located in the connector path of the fckeditor module. Remote attackers are able to upload files without secure authentication, which results in the compromise by malicious webshells (php or js). The path variable of the upload folder is not restricted by default configuration. The security risk of the web vulnerability is estimated as high with a cvss (common vulnerability scoring system) count of 7.1. Exploitation of the web vulnerability requires no privileged web-application account with restricted access or user interaction. Successful exploitation of the vulnerabilities results in unauthorized upload of files like webshells or rootkits to compromise the web-server and database management system. Request Method(s): [+] POST Vulnerable Module(s): [+] Fckeditor Vulnerable Function(s): [+] File Upload Proof of Concept (PoC): ======================= 1.1 The remote sql-injection web vulnerability can be exploited by remote attackers without privileged user account or user interaction. For security demonstration or to reproduce the vulnerability follow the provided information and steps below to continue. Dork(s): inurl:list.php?i= PoC: http://localhost:8080/list.php?i=-1'[SQL-INJECTION VULNERABILITY!]
Source: Gmail -> IFTTT-> Blogger
Source: Gmail -> IFTTT-> Blogger
Subscribe to:
Posts (Atom)