In today’s blog post, I interview David Austin, who, with his teammate, Weimin Wang, took home 1st place (and $25,000) in Kaggle’s Iceberg Classifier Challenge.
David and Weimin’s winning solution can be practically used to allow safer navigation for ships and boats across hazardous waters, resulting in less damages to ships and cargo, and most importantly, reduce accidents, injuries, and deaths.
According to Kaggle, the Iceberg image classification challenge:
- Was the most popular image classification challenge they’ve ever had (measured in terms of competing teams)
- And was the 7th most popular competition of all time (across all challenges types: image, text, etc.)
Soon after the competition ended, David sent me the following message:
Hi Adrian, I’m a PyImageSearch Guru’s member, consumer of all your books, will be at PyImageConf in August, and an overall appreciative student of your teaching.
Just wanted to share a success story with you, as I just finished in first out of 3,343 teams in the Statoil Iceberg Classifier Kaggle competition ($25k first place prize).
A lot of my deep learning and cv knowledge was acquired through your training and a couple of specific techniques I learned through you were used in my winning solution (thresholding and mini-Googlenet specifically). Just wanted to say thanks and to let you know you’re having a great impact.
Thanks! David
David’s personal message really meant a lot to me, and to be honest, it got me a bit emotional.
As a teacher and educator, there is no better feeling in the world seeing readers:
- Get value out what you’ve taught from your blog posts, books, and courses
- Use their knowledge in ways that enriches their lives and improves the lives of others
Inside today’s post I’ll be interviewing David and discussing:
- What the iceberg image classification challenge is…and why it’s important
- The approach, algorithms, and techniques utilized by David and Weimin in their winning submission
- What the most difficult aspect of the challenge was (and how they overcame it)
- His advice for anyone who wants to compete in a Kaggle competition
I am so incredibly happy for both David and Weimin — they deserve all the congrats and a huge round of applause.
Join me in this interview and discover how David and his teammate Weimin won Kaggle’s most popular image classification competition.
An interview with David Austin: 1st place and $25,000 in Kaggle’s most popular competition
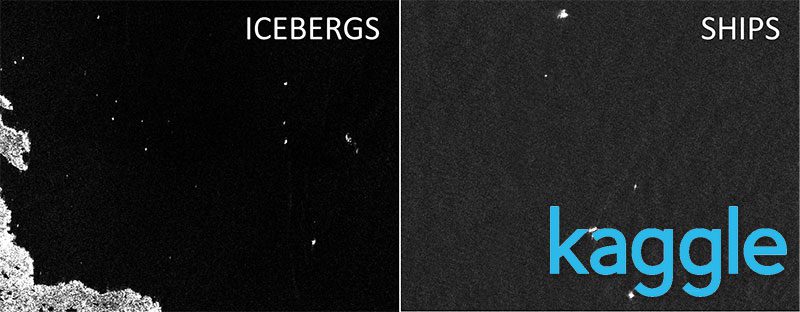
Figure 1: The goal of the Kaggle Iceberg Classifier challenge is to build an image classifier that classifies input regions of a satellite image as either “iceberg” or “ship” (source).
Adrian: Hi David! Thank you for agreeing to do this interview. And congratulations on your 1st place finish in the Kaggle Iceberg Classifier Change, great job!
David: Thanks Adrian, it’s a pleasure to get to speak with you.
Adrian: How did you first become interested in computer vision and deep learning?
David: My interest in deep learning has been growing steadily over the past two years as I’ve seen how people have been using it go gain incredible insights from the data they work with. I have interest in both the active research as well as the practical application sides of deep learning, so I find competing in Kaggle competitions a great place to keep the skills sharp and to try out new techniques as they become available.
Adrian: What was your background in computer vision and machine learning/deep learning before you entered the competition? Did you compete in any previous Kaggle competitions?
David: My first exposure to machine learning goes back about 10 years when I first started learning about gradient boosted trees and random forests and applying them to classification type problems. Over the past couple of years I’ve started focusing more extensively on deep learning and computer vision.
I started competing in Kaggle competitions a little under a year ago in my spare time as a way to sharpen my skills, and this was my third image classification competition.

Figure 2: An example of how an iceberg looks. The goal of the Kaggle competition was to recognize such icebergs from satellite imagery (source).
Adrian: Can you tell me a bit more about the Iceberg Classifier Challenge? What motivated you to compete in it?
David: Sure, the Iceberg Classification Challenge was a binary image classification problem in which the participants were asked to classify ships vs. icebergs collected via satellite imagery. It’s especially important in the energy exploration space to be able to identify and avoid threats such as drifting icebergs.
There were a couple interesting aspects to the dataset that made this a fun challenge to work on.
First, the dataset was relatively small with only 1604 images in the training set, so the barrier to entry from a hardware perspective was pretty low, but the difficulty of working with a limited dataset was high.
Secondly, when looking at the images, to the human eye many of them look analogous to what a “snowy” TV screen looks like, just a bunch of salt and pepper noise and it was not at all visually clear which images were ships and which ones were icebergs:

Figure 3: It’s extremely difficult for the human eye to accurately determine if an input region is an “iceberg” or a “ship” (source).
So the fact that it would be particularly difficult for a human to accurately predict the classifications, I thought it would serve as a great test to see what computer vision and deep learning could do.
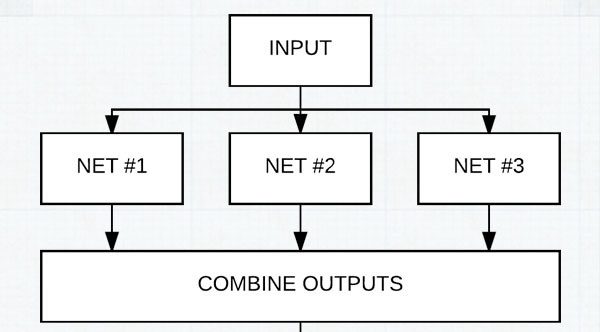
Figure 4: David and Weimin winning solution involved using an ensemble of CNN architectures.
Adrian: Let’s get a bit technical. Can you tell us a bit about the approach, algorithms, and techniques you used in your winning entry?
David: Well, the overall approach was very similar to most typical computer vision problems in that we spent quite a bit of time up front understanding the data.
One of my favorite techniques early on is to use unsupervised learning methods to identify natural patterns in the data, and use that learning to determine what deep learning approaches to take down-stream.
In this case a standard KNN algorithm was able to identify a key signal that helped define our model architecture. From there, we used a pretty extensive CNN architecture that consisted of over 100+ customized CNN’s and VGG like architectures and then combined the results from these models using both greedy blending and two-level stacking with other image features.
Now that may sound like a very complex approach, but remember that the objective function here was to minimize log loss error, and in this case we only added models in so much as they reduced log loss without overfitting, so it was another good example of the power of ensembling many weaker learners.
We ended up training many of the same CNN’s a second time but only using a subset of the data that we identified from the unsupervised learning at the beginning of the process as this also gave us an improvement in performance.
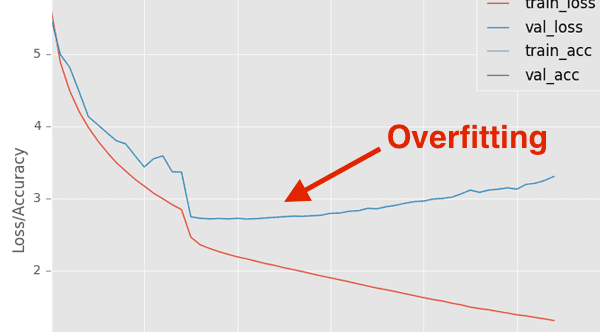
Figure 5: The most difficult aspect of the Kaggle Iceberg challenge for David and his teammate was avoiding overfitting.
Adrian: What was the most difficult aspect of the challenge for you and why?
David: The hardest part of the challenge was in validating that we weren’t overfitting.
The dataset size for an image classification problem was relatively small, so we were always worried that overfitting could be a problem. For this reason we made sure that all of our models were done using 4 fold cross validation, which adds to the computational cost, but reduces the overfitting risk. Especially when you’re dealing with an unforgiving loss function like log loss, you have to be constantly on the lookout for overfitting.
Adrian: How long did it take to train your model(s)?
David: Even with the large number of CNN’s that we chose to use, and even with using 4-fold cross validation on the entire set of models, training only took between 1-2 days. Individual models without cross validation could train in some cases on the order of minutes.
Adrian: If you had to pick the most important technique or trick you applied during the competition, what would it be?
David: Without a doubt, the most important step was the up-front exploratory analysis to give a good understanding of the dataset.
It turns out there was a very important signal in the one other feature other than the image data that helped remove a lot of noise in the data.
In my opinion one of the most overlooked steps in any CV or deep learning problem is the upfront work required to understand the data and use that knowledge to make the best design choices.
As algorithms have become more readily available and easy to import, often times there’s a rush to “throw algorithms” at a problem without really understanding if those algorithms are the right one for the job, or if there’s work that should be done before or after training to handle the data appropriately.

Figure 6: David used TensorFlow, Keras, and xgboost in the winning Kaggle submission.
Adrian: What are your tools and libraries of choice?
David: Personally I find Tensorflow and Keras to be amongst the most usable so when working on deep learning problems, I tend to stick to them.
For stacking and boosting, I use xgboost, again primarily due to familiarity and it’s proven results.
In this competition I used my
dl4cvvirtualenv (a Python virtual environment used inside Deep Learning for Computer Vision with Python) and added xgboost to it.
Adrian: What advice would you give to someone who wants to compete in their first Kaggle competition?
David: One of the great things about Kaggle competitions is the community nature of how the competitions work.
There’s a very rich discussion forum and way for participants to share their code if they choose to do so which is really invaluable when you’re trying to learn both general approaches as well as ways to apply code to a specific problem.
When I started on my first competition I spent hours reading through the forums and other high quality code and found it to be one of the best ways to learn.
Adrian: How did the PyImageSearch Gurus course and Deep Learning for Computer Vision with Python book prepare you for the Kaggle competition?
David: Very similar to competing in a Kaggle competition, PyImageSearch Gurus is a learn-by-doing formatted course.
To me there’s nothing that can prepare you for working on problems like actually working on problems and following high quality solutions and code, and one of the things I appreciate most about the PyImageSearch material is the way it walks you through practical solutions with production level code.
I also believe that one of the best ways to really learn and understand deep learning architectures is to read a paper and then go try to implement it.
This strategy is implemented in practice throughout the ImageNet Bundle book, and it’s the same strategy that can be used to modify and adapt architectures like we did in this competition.
I also learned about MiniGoogleNet from the Practitioner Bundle book which I hadn’t come across before and was a model that performed well in this competition.
Adrian: Would you recommend PyImageSearch Gurus or Deep Learning for Computer Vision with Python to other developers, researchers, and students trying to learn computer vision + deep learning?
David: Absolutely. I would recommend it to anyone who’s looking to establish a strong foundation in CV and deep learning because you’re not only going to learn the principals, but you’re going to learn how to quickly apply your learning to real-world problems using the most popular and up to date tools and SW.
Adrian: What’s next?
David: Well, I’ve got a pretty big pipeline of projects I want to work on lined up so I’m going to be busy for a while. There are a couple other Kaggle competitions that look like really fun challenges to work on so there’s a good chance I’ll jump back into those too.
Adrian: If a PyImageSearch reader wants to chat, what is the best place to connect with you?
David: The best way to reach me is my LinkedIn profile. You can connect with Weimin Wang on LinkedIn as well. I’ll also be attending PyImageConf 2018 in August if you want to chat in person.
What about you? Are you ready to follow in the footsteps of David?
Are you ready start your journey to computer vision + deep learning mastery and follow in the footsteps of David Austin?
David is a long-time PyImageSearch reader and has worked through both:
- The PyImageSearch Gurus course, an in-depth treatment of computer vision and image processing
- Deep Learning for Computer Vision with Python, the most comprehensive computer vision + deep learning book available today
I can’t promise you’ll win a Kaggle competition like David has, but I can guarantee that these are the two best resources available today to master computer vision and deep learning.
To quote Stephen Caldara, a Sr. Systems Engineer at Amazon Robotics:
I am very pleased with the [PyImageSearch Gurus] content you have created. I would rate it easily at a university ‘masters program’ level. And better organized.
Along with Adam Geitgey, author of the popular Machine Learning is Fun! blog series:
I highly recommend grabbing a copy of Deep Learning for Computer Vision with Python. It goes into a lot of detail and has tons of detailed examples. It’s the only book I’ve seen so far that covers both how things work and how to actually use them in the real world to solve difficult problems. Check it out!
Give the course and book a try — I’ll be there to help you every step of the way.
Summary
In today’s blog post, I interviewed David Austin, who, with his teammate, Weimin Wang, won first place (and $25,000) in Kaggle’s Iceberg Classifier Challenge.
David and Weimin’s hard work will help ensure safer, less hazardous travel through iceberg-prone waters.
I am so incredibly happy (and proud) for David and Weimin. Please join me and congratulate them in the comments section of this blog post.
The post An interview with David Austin: 1st place and $25,000 in Kaggle’s most popular image classification competition appeared first on PyImageSearch.
from PyImageSearch https://ift.tt/2G9cejF
via IFTTT
No comments:
Post a Comment