
An example of a Pokedex (thank you to Game Trader USA for the Pokedex template!)
When I was a kid, I was a huge Pokemon nerd. I collected the trading cards, played the Game Boy games, and watched the TV show. If it involved Pokemon, I was probably interested in it.
Pokemon made a lasting impression on me — and looking back, Pokemon may have even inspired me to study computer vision.
You see, in the very first episode of the show (and in the first few minutes of the game), the protagonist, Ash Ketchum, was given a special electronic device called a Pokedex.
A Pokedex is used to catalogue and provide information regarding species of Pokemon encounters Ash along his travels. You can think of the Pokedex as a “Pokemon Encyclopedia” of sorts.
When stumbling upon a new species of Pokemon Ash had not seen before, he would hold the Pokedex up to the Pokemon and then the Pokedex would automatically identify it for him, presumably via some sort of camera sensor (similar to the image at the top of this post).
In essence, the Pokedex was acting like a smartphone app that utilized computer vision!
We can imagine a similar app on our iPhone or Android today, where:
- We open the “Pokedex” app on our phone
- The app accesses our camera
- We snap a photo of the Pokemon
- And then the app automatically identifies the Pokemon
As a kid, I always thought the Pokedex was so cool…
…and now I’m going to build one.
In this three-part blog post series we’re going to build our very own Pokedex:
- We’ll start today by using the Bing Image Search API to (easily) build our image dataset of Pokemon.
- Next week, I’ll demonstrate how to implement and train a CNN using Keras to recognize each Pokemon.
- And finally, we’ll use our trained Keras model and deploy it to an iPhone app (or at the very least a Raspberry Pi — I’m still working out the kinks in the iPhone deployment).
By the end of the series we’ll have a fully functioning Pokedex!
To get started using the Bing Image Search API to build an image dataset for deep learning, just keep reading.
Looking for the source code to this post?
Jump right to the downloads section.
How to (quickly) build a deep learning image dataset
In order to build our deep learning image dataset, we are going to utilize Microsoft’s Bing Image Search API, which is part of Microsoft’s Cognitive Services used to bring AI to vision, speech, text, and more to apps and software.
In a previous blog post, you’ll remember that I demonstrated how you can scrape Google Images to build your own dataset — the problem here is that it’s a tedious, manual process.
Instead, I was looking for a solution that would enable me to programmatically download images via a query.
I did not want to have to open my browser or utilize browser extensions to download the image files from my search.
Many years ago Google deprecated its own image search API (which is the reason we need to scrape Google Images in the first place).
A few months ago I decided to give Microsoft’s Bing Image Search API a try. I was incredibly pleased.
The results were relevant and the API was easy to consume.
It also includes a free 30-day trial as well, after which the API seems reasonably priced (I haven’t converted to a paying customer yet but I probably will given the pleasant experience).
In the remainder of today’s blog post, I’ll be demonstrating how we can leverage the Bing Image Search API to quickly build an image dataset suitable for deep learning.
Creating your Cognitive Services account
In this section, I’ll provide a short walkthrough of how to get your (free) Bing Image Search API account.
The actual registration process is straightforward; however, finding the actual page that kicks off the registration process is a bit confusing — it’s my primary critique of the service.
To get started, head to the Bing Image Search API page:
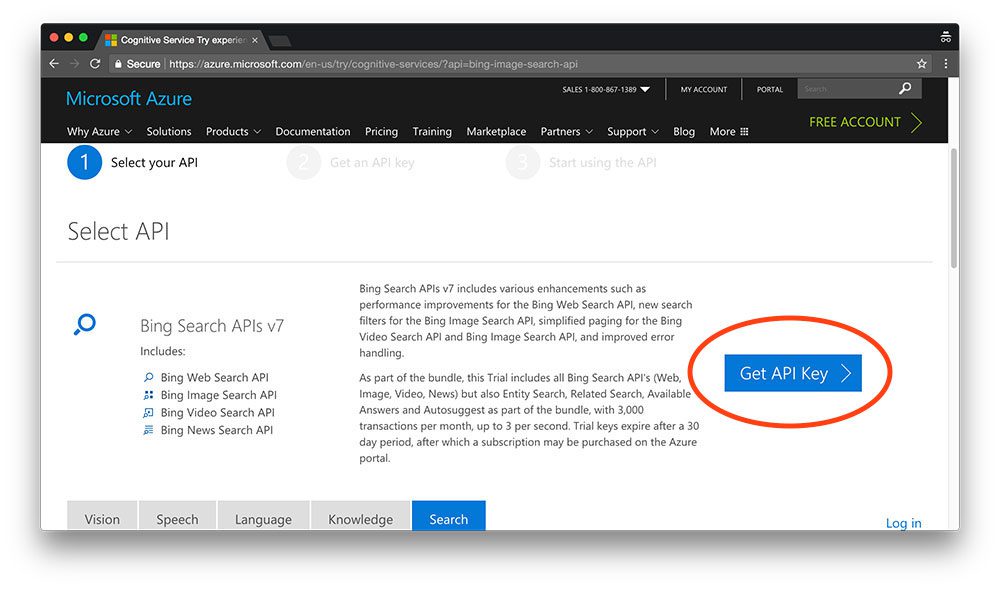
Figure 1: We can use the Microsoft Bing Search API to download images for a deep learning dataset.
As we can see from the screenshot, the trial includes all of Bing’s search APIs with a total of 3,000 transactions per month — this will be more than sufficient to play around and build our first image-based deep learning dataset.
To register for the Bing Image Search API, click the “Get API Key” button.
From there you’ll be able to register by logging in with your Microsoft, Facebook, LinkedIn, or GitHub account (I went with GitHub for simplicity).
After you finish the registration process you’ll end up on the Your APIs page which should look similar to my browser below:
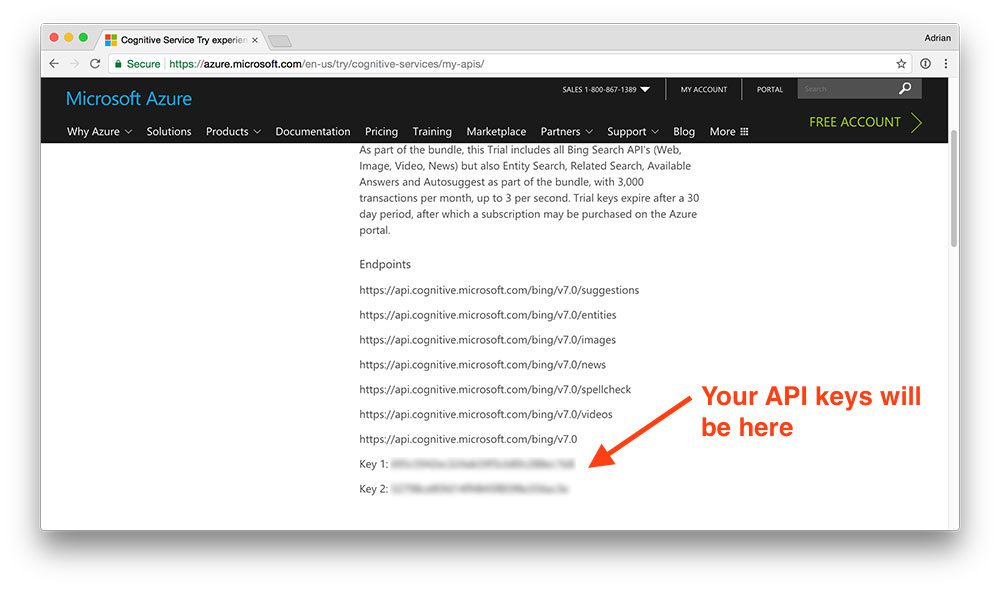
Figure 2: The Microsoft Bing API endpoints along with my API keys which I need in order to use the API.
Here you can see my list of Bing search endpoints, including my two API keys (blurred out for obvious reasons).
Make note of your API key as you’ll need it in the next section.
Building a deep learning dataset with Python
Now that we have registered for the Bing Image Search API, we are ready to build our deep learning dataset.
Read the docs
Before continuing, I would recommend opening up the following two Bing Image Search API documentation pages in your browser:
You should reference these two pages if you have any questions on either (1) how the API works or (2) how we are consuming the API after making a search request.
Install the requests package
If you do not already have
requestsinstalled on your system, you can install it via:
$ pip install requests
The
requestspackage makes it super easy for us to make HTTP requests and not get bogged down in fighting with Python to gracefully handle requests.
Additionally, if you are using Python virtual environments make sure you use the
workoncommand to access the environment before installing
requests:
$ workon your_env_name $ pip install requests
Create your Python script to download images
Let’s go ahead and get started coding.
Open up a new file, name it
search_bing_api.py, and insert the following code:
# import the necessary packages
from requests import exceptions
import argparse
import requests
import cv2
import os
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-q", "--query", required=True,
help="search query to search Bing Image API for")
ap.add_argument("-o", "--output", required=True,
help="path to output directory of images")
args = vars(ap.parse_args())
Lines 2-6 handle importing the packages necessary for this script. You’ll need OpenCV and requests installed in your virtual environment. To set up OpenCV on your system, just follow the relevant guide for your system here.
Next, we parse two command line arguments:
-
--query:
The image search query you’re using, which could be anything such as “pikachu”, “santa” or “jurassic park”. -
--output:
The output directory for your images. My personal preference (for the sake of organization and sanity) is to separate your images into separate class subdirectories, so be sure to specify the correct folder that you’d like your images to go into (shown below in the “Downloading images for training a deep neural network” section).
You do not need to modify the command line arguments section of this script (Lines 9-14). These are inputs you give the script at runtime. To learn how to properly use command line arguments, see my recent blog post.
From there, let’s configure some global variables:
# set your Microsoft Cognitive Services API key along with (1) the # maximum number of results for a given search and (2) the group size # for results (maximum of 50 per request) API_KEY = "YOUR_API_KEY_GOES_HERE" MAX_RESULTS = 250 GROUP_SIZE = 50 # set the endpoint API URL URL = "https://api.cognitive.microsoft.com/bing/v7.0/images/search"
The one part of this script that you must modify is the
API_KEY. You can grab an API key by logging into Microsoft Cognitive Services and selecting the service you’d like to use (as shown above where you need to click the “Get API Key” button). From there, simply paste the API key within the quotes for this variable.
You can also modify
MAX_RESULTSand
GROUP_SIZEfor your search. Here, I’m limiting my results to the first
250images and returning the maximum number of images per request by the Bing API (
50total images).
You can think of the
GROUP_SIZEparameter as the number of search results to return “per page”. Therefore, if we would like a total of 250 images, we would need to go through 5 “pages” with 50 images “per page”.
When training a Convolutional Neural Network, I would ieally like to have ~1,000 images per class but this is just an example. Feel free to download as many images as you would like, just be mindful:
- That all images you download should still be relevant to the query.
- You don’t bump up against the limits of Bing’s free API tier (otherwise you’ll need to start paying for the service).
From there, let’s make sure that we are prepared to handle all (edit: most) of the possible exceptions that can arise when trying to fetch an image by first making a list of the exceptions we may encounter:
# when attempting to download images from the web both the Python
# programming language and the requests library have a number of
# exceptions that can be thrown so let's build a list of them now
# so we can filter on them
EXCEPTIONS = set([IOError, FileNotFoundError,
exceptions.RequestException, exceptions.HTTPError,
exceptions.ConnectionError, exceptions.Timeout])
When working with network requests there are a number of exceptions that can be thrown, so we list them on Lines 30-32. We’ll try to catch them and handle them gracefully later.
From there, let’s initialize our search parameters and make the search:
# store the search term in a convenience variable then set the
# headers and search parameters
term = args["query"]
headers = {"Ocp-Apim-Subscription-Key" : API_KEY}
params = {"q": term, "offset": 0, "count": GROUP_SIZE}
# make the search
print("[INFO] searching Bing API for '{}'".format(term))
search = requests.get(URL, headers=headers, params=params)
search.raise_for_status()
# grab the results from the search, including the total number of
# estimated results returned by the Bing API
results = search.json()
estNumResults = min(results["totalEstimatedMatches"], MAX_RESULTS)
print("[INFO] {} total results for '{}'".format(estNumResults,
term))
# initialize the total number of images downloaded thus far
total = 0
On Lines 36-38, we initialize the search parameters. Be sure to review the API documentation as needed.
From there, we perform the search (Lines 42-43) and grab the results in JSON format (Line 47).
We calculate and print the estimated number of results to the terminal next (Lines 48-50).
We’ll be keeping a counter of the images downloaded as we go, so I initialize
totalon Line 53.
Now it’s time to loop over the results in
GROUP_SIZEchunks:
# loop over the estimated number of results in `GROUP_SIZE` groups
for offset in range(0, estNumResults, GROUP_SIZE):
# update the search parameters using the current offset, then
# make the request to fetch the results
print("[INFO] making request for group {}-{} of {}...".format(
offset, offset + GROUP_SIZE, estNumResults))
params["offset"] = offset
search = requests.get(URL, headers=headers, params=params)
search.raise_for_status()
results = search.json()
print("[INFO] saving images for group {}-{} of {}...".format(
offset, offset + GROUP_SIZE, estNumResults))
Here we are looping over the estimated number of results in
GROUP_SIZEbatches as that is what the API allows (Line 56).
The current
offsetis passed as a parameter when we call
requests.getto grab the JSON blob (Line 62).
From there, let’s try to save the images in the current batch:
# loop over the results
for v in results["value"]:
# try to download the image
try:
# make a request to download the image
print("[INFO] fetching: {}".format(v["contentUrl"]))
r = requests.get(v["contentUrl"], timeout=30)
# build the path to the output image
ext = v["contentUrl"][v["contentUrl"].rfind("."):]
p = os.path.sep.join([args["output"], "{}{}".format(
str(total).zfill(8), ext)])
# write the image to disk
f = open(p, "wb")
f.write(r.content)
f.close()
# catch any errors that would not unable us to download the
# image
except Exception as e:
# check to see if our exception is in our list of
# exceptions to check for
if type(e) in EXCEPTIONS:
print("[INFO] skipping: {}".format(v["contentUrl"]))
continue
Here we’re going to loop over the current batch of images and attempt to download each individual image to our output folder.
We establish a try-catch block so that we can catch the possible
EXCEPTIONSwhich we defined earlier in the script. If we encounter an exception we’ll be skipping that particular image and moving forward (Line 71 and Lines 88-93).
Inside of the
tryblock, we attempt to fetch the image by URL (Line 74), and build a path + filename for it (Lines 77-79).
We then try to open and write the file to disk (Lines 82-84). It’s worth noting here that we’re creating a binary file object denoted by the
bin
"wb". We access the binary data via
r.content.
Next, let’s see if the image can actually be loaded by OpenCV which would imply (1) that the image file was downloaded successfully and (2) the image path is valid:
# try to load the image from disk
image = cv2.imread(p)
# if the image is `None` then we could not properly load the
# image from disk (so it should be ignored)
if image is None:
print("[INFO] deleting: {}".format(p))
os.remove(p)
continue
# update the counter
total += 1
In this block, we load the image file on Line 96.
As long as the
imagedata is not
None, we update our
totalcounter and loop back to the top.
Otherwise, we call
os.removeto delete the invalid image and we continue back to the top of the loop without updating our counter. The if-statement on Line 100 could trigger due to network errors when downloading the file, not having the proper image I/O libraries installed, etc. If you’re interested in learning more about
NoneTypeerrors in OpenCV and Python, refer to this blog post.
Downloading images for training a deep neural network

Figure 3: The Bing Image Search API is so easy to use that I love it as much as I love Pikachu!
Now that we have our script coded up, let’s download images for our deep learning dataset using Bing’s Image Search API.
Make sure you use the “Downloads” section of this guide to download the code and example directory structure.
In my case, I am creating a
datasetdirectory:
$ mkdir dataset
All images downloaded will be stored in
dataset. From there, execute the following commands to make a subdirectory and run the search for “charmander”:
$ mkdir dataset/charmander $ python search_bing_api.py --query "charmander" --output dataset/charmander [INFO] searching Bing API for 'charmander' [INFO] 250 total results for 'charmander' [INFO] making request for group 0-50 of 250... [INFO] saving images for group 0-50 of 250... [INFO] fetching: https://fc06.deviantart.net/fs70/i/2012/355/8/2/0004_c___charmander_by_gaghiel1987-d5oqbts.png [INFO] fetching: https://th03.deviantart.net/fs71/PRE/f/2010/067/5/d/Charmander_by_Woodsman819.jpg [INFO] fetching: https://fc05.deviantart.net/fs70/f/2011/120/8/6/pokemon___charmander_by_lilnutta10-d2vr4ov.jpg ... [INFO] making request for group 50-100 of 250... [INFO] saving images for group 50-100 of 250... ... [INFO] fetching: https://38.media.tumblr.com/f0fdd67a86bc3eee31a5fd16a44c07af/tumblr_nbhf2vTtSH1qc9mvbo1_500.gif [INFO] deleting: dataset/charmander/00000174.gif ...
As I mentioned in the introduction of this post, we are downloading images of Pokemon to be used when building a Pokedex (a special device to recognize Pokemon in real-time).
In the above command I am downloading images of Charmander, a popular Pokemon. Most of the 250 images will successfully download, but as shown in the output above, there will be a few that aren’t able to be opened by OpenCV and will be deleted.
I do the same for Pikachu:
$ mkdir dataset/pikachu $ python search_bing_api.py --query "pikachu" --output dataset/pikachu [INFO] searching Bing API for 'pikachu' [INFO] 250 total results for 'pikachu' [INFO] making request for group 0-50 of 250... [INFO] saving images for group 0-50 of 250... [INFO] fetching: http://www.mcmbuzz.com/wp-content/uploads/2014/07/025Pikachu_OS_anime_4.png [INFO] fetching: http://images4.fanpop.com/image/photos/23300000/Pikachu-pikachu-23385603-814-982.jpg [INFO] fetching: http://images6.fanpop.com/image/photos/33000000/pikachu-pikachu-33005706-895-1000.png ...
Along with Squirtle:
$ mkdir dataset/squirtle $ python search_bing_api.py --query "squirtle" --output dataset/squirtle [INFO] searching Bing API for 'squirtle' [INFO] 250 total results for 'squirtle' [INFO] making request for group 0-50 of 250... [INFO] saving images for group 0-50 of 250... [INFO] fetching: https://fc03.deviantart.net/fs71/i/2013/082/1/3/007_squirtle_by_pklucario-d5z1gj5.png [INFO] fetching: https://fc03.deviantart.net/fs70/i/2012/035/b/2/squirtle_by_maii1234-d4oo1aq.jpg [INFO] fetching: https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhfFYDbctaPLppgG-XHpJMV7dGUeOZhfiT52unaSaY9Y-s_gm82g_2S9dKxp1bCQYfel2qGnfi0dIDMl0rDKADd-ky5daBFtdUHRQyeuynzEAuOXIBAtFgOcG5DFpiMSqMtl8eBCLbkJWk0/s1600/Leo%2527s+Squirtle.jpg ...
Then Bulbasaur:
$ mkdir dataset/bulbasaur $ python search_bing_api.py --query "bulbasaur" --output dataset/bulbasaur [INFO] searching Bing API for 'bulbasaur' [INFO] 250 total results for 'bulbasaur' [INFO] making request for group 0-50 of 250... [INFO] saving images for group 0-50 of 250... [INFO] fetching: https://fc06.deviantart.net/fs51/f/2009/261/3/e/Bulbasaur_by_elfaceitoso.png [INFO] skipping: https://fc06.deviantart.net/fs51/f/2009/261/3/e/Bulbasaur_by_elfaceitoso.png [INFO] fetching: https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgQFI1nFaMsrkXu2iVO9OAFRm7yBw8ca7AsBK-rIbSXTArh7xtdp1UFuOGMRGpUwGHcwlohBNbZu1r7ONCxoaGvilv9lvVBh1J5MkLtDNu94HE4V7Jobwp0BKIv0vnzslbMVsgiUzA7RYvj/s1600/001Bulbasaur+pokemon+firered+leafgreen.png [INFO] skipping: https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgQFI1nFaMsrkXu2iVO9OAFRm7yBw8ca7AsBK-rIbSXTArh7xtdp1UFuOGMRGpUwGHcwlohBNbZu1r7ONCxoaGvilv9lvVBh1J5MkLtDNu94HE4V7Jobwp0BKIv0vnzslbMVsgiUzA7RYvj/s1600/001Bulbasaur+pokemon+firered+leafgreen.png [INFO] fetching: https://fc09.deviantart.net/fs71/i/2012/088/9/6/bulbasaur_by_songokukai-d4gecpp.png ...
And finally Mewtwo:
$ mkdir dataset/mewtwo $ python search_bing_api.py --query "mewtwo" --output dataset/mewtwo [INFO] searching Bing API for 'mewtwo' [INFO] 250 total results for 'mewtwo' [INFO] making request for group 0-50 of 250... [INFO] saving images for group 0-50 of 250... [INFO] fetching: https://sickr.files.wordpress.com/2011/09/mewtwo.jpg [INFO] fetching: https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjHL_NRziG8t4f-jhA1f8tkSmnELreH2TS4ooUxx9L0-JNzs2oqPhpbkyb5p4Zyunh2naFTd3xuAz0ngSnw20lDLSMJL1ZTvcbxzl-c9hNA3wVZw05C6WaswCplrfof_Zb579RmExusk1I/s1600/Mewtwo+Pokemon+Wallpapers+3.jpg [INFO] fetching: https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEh3hM9ruOXIqHAYwYaGK6MrQAquQ_Aa6_h7mk-x-iW3HgJQqUlqicVmau5CjoAicc39u4evMDN2GrbKnxVmsznr_L3Uql_yKarJHis2q0EtPAFmdxQQsd3Qu73vaY9Wt1hiiDyK2z1xix4/s1600/Mewtwo+Pokemon+Wallpapers.jpg ...
We can count the total number of images downloaded per query by using a bit of
findmagic (thank you to Glenn Jackman on StackOverflow for this great command hack):
$ find . -type d -print0 | while read -d '' -r dir; do
> files=("$dir"/*)
> printf "%5d files in directory %s\n" "${#files[@]}" "$dir"
> done
2 files in directory .
5 files in directory ./dataset
235 files in directory ./dataset/bulbasaur
245 files in directory ./dataset/charmander
245 files in directory ./dataset/mewtwo
238 files in directory ./dataset/pikachu
230 files in directory ./dataset/squirtle
Here we can see we have approximately 230-245 images per class. Ideally, I would like to have ~1,000 images per class, but for the sake of simplicity in this example and network overhead (for users without a fast/stable internet connection), I only downloaded 250.
Note: If you use that ugly
findcommand often, it would be worth making an alias in your
~/.bashrc!
Pruning our deep learning image dataset
However, not every single image we downloaded will be relevant to the query — most will be, but not all of them.
Unfortunately this is the manual intervention step where you need to go through your directories and prune irrelevant images.
On macOS this is actually a pretty quick process.
My workflow involves opening up Finder and then browseing all images in the “Cover Flow” view:
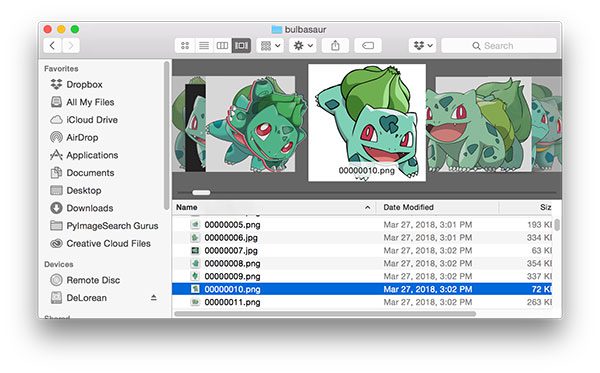
Figure 4: I’m using the macOS “Cover Flow” view in order to quickly flip through images and filter out those that I don’t want in my deep learning dataset.
If an image is not relevant I can move it to the Trash via
cmd + deleteon my keyboard. Similar shortcuts and tools exist on other operating systems as well.
After pruning the irrelevant images, let’s do another image count:
$ find . -type d -print0 | while read -d '' -r dir; do
> files=("$dir"/*);
> printf "%5d files in directory %s\n" "${#files[@]}" "$dir";
> done
3 files in directory .
5 files in directory ./dataset
234 files in directory ./dataset/bulbasaur
238 files in directory ./dataset/charmander
239 files in directory ./dataset/mewtwo
234 files in directory ./dataset/pikachu
223 files in directory ./dataset/squirtle
As you can see, I only had to delete a handful of images per class — the Bing Image Search API worked quite well!
Note: You should also consider removing duplicate images as well. I didn’t take this step as there weren’t too many duplicates (except for the “squirtle” class; I have no idea why there were so many duplicates there), but if you’re interested in learning more about how to find duplicates, see this blog post on image hashing.
Summary
In today’s blog post you learned how to quickly build a deep learning image dataset using Microsoft’s Bing Image Search API.
Using the API we were able to programmatically download images for training a deep neural network, a huge step up from having to manually scrape images using Google Images.
The Bing Image Search API is free to use for 30 days which is perfect if you want to follow along with this series of posts.
I’m still in my trial period, but given the positive experience thus far I would likely pay for the API in the future (especially since it will help me quickly create datasets for fun, hands-on deep learning PyImageSearch tutorials).
In next week’s blog post I’ll be demonstrating how to train a Convolutional Neural Network with Keras on top of the deep learning images we downloaded today. And in the final post in the series (coming in two weeks), I’ll show you how to deploy your Keras model to your smartphone (if possible — I’m still working out the kinks in the Keras + iOS integration).
This is a can’t miss series of posts, so don’t miss out! To be notified when the next post in the series goes live, just enter your email address in the form below.
Downloads:
The post How to (quickly) build a deep learning image dataset appeared first on PyImageSearch.
from PyImageSearch https://ift.tt/2GKjYgB
via IFTTT
No comments:
Post a Comment